8.4 Синтаксические деревья
Синтаксическое дерево (дерево операций) — это структура, представляющая собой результат работы синтаксического анализатора. Она отражает синтаксис конструкций входного языка и явно содержит в себе полную взаимосвязь операций.
8.4.1 Дерево разбора. Преобразование дерева разбора в дерево операций
В синтаксическом дереве внутренние узлы (вершины) соответствуют операциям, а листья представляют собой операнды. Как правило, листья синтаксического дерева связаны с записями в таблице идентификаторов. Структура синтаксического дерева отражает синтаксис языка программирования, на котором написана исходная программа.
Синтаксические деревья могут быть построены компилятором для любой части входной программы. Не всегда синтаксическому дереву должен соответствовать фрагмент кода результирующей программы — например, возможно построение синтаксических деревьев для декларативной части языка. В этом случае операции, имеющиеся в дереве, не требуют порождения объектного кода, но несут информацию о действиях, которые должен выполнить сам компилятор над соответствующими элементами. В том случае, когда синтаксическому дереву соответствует некоторая последовательность операций, влекущая порождение фрагмента объектного кода, говорят о дереве операций.
Дерево операций можно непосредственно построить из дерева вывода, порожденного синтаксическим анализатором. Для этого достаточно исключить из дерева вывода цепочки нетерминальных символов, а также узлы, не несущие семантической (смысловой) нагрузки при генерации кода. Примером таких узлов могут служить различные скобки, которые меняют порядок выполнения операций и операторов, но после построения дерева никакой смысловой нагрузки не несут, так как им не соответствует никакой объектный код.
То, какой узел в дереве является операцией, а какой — операндом, невозможно определить из грамматики, описывающей синтаксис входного языка. Также ниоткуда не следует, каким операциям должен соответствовать объектный код в результирующей программе, а каким — нет. Все это определяется только исходя из семантики — «смысла» — языка входной программы. Поэтому только разработчик компилятора может четко определить, как при построении дерева операций должны различаться операнды и сами операции, а также то, какие операции являются семантически незначащими для порождения объектного кода.
Алгоритм преобразования дерева вывода в дерево операций:
1). Если в дереве больше не содержится узлов, помеченных нетерминальными символами, то выполнение алгоритма завершено, иначе — перейти к шагу 2.
2). Выбрать крайний левый узел дерева, помеченный нетерминальным символом грамматики и сделать его текущим. Перейти к шагу 3.
3). Если текущий узел имеет только один нижележащий узел, то текущий узел необходимо удалить из дерева, а связанный с ним узел присоединить к узлу вышележащего уровня (исключить из дерева цепочку) и вернуться к шагу 1;
4). Если текущий узел имеет нижележащий узел (лист дерева), помеченный терминальным символом, который не несет семантической нагрузки, тогда этот лист нужно удалить из дерева и вернуться к шагу 3; иначе — перейти к шагу 5.
5). Если текущий узел имеет один нижележащий узел (лист дерева), помеченный терминальным символом, обозначающим знак операции, а остальные узлы помечены как операнды, то узел, помеченный знаком операции, надо удалить из дерева, текущий узел пометить этим знаком операции и перейти к шагу 1; иначе — перейти к шагу 6.
6). Если среди нижележащих узлов для текущего узла есть узлы, помеченные нетерминальными символами грамматики то необходимо выбрать крайний левый среди этих узлов, сделать его текущим узлом перейти к шагу 3; иначе — выполнение алгоритма завершено.
Этот алгоритм всегда работает с узлом дерева, который считается текущим и стремится исключить из дерева, все узлы, помеченные нетерминальными символами. То, какие из символов считать семантически незначащими, а какие считать, знаками операций, решает разработчик компилятора. Если семантика языка задана корректно, то в результате работы алгоритма из дерева будут исключены все нетерминальные символы.
Пример синтаксического дерева, построенного для цепочки (а+а)*b из языка, заданного различными вариантами грамматики арифметических выражений представлен на рис. 42.
В результате применения алгоритма преобразования деревьев синтаксического разбора, в дерево операций, получим дерево операции, представленное на рис. 42. Причем, несмотря на то, что исходные синтаксические деревья имели различную структуру, зависящую от используемой грамматики, результирующее дерево операций всегда имеет одну и ту же структуру, зависящую только от семантики входного языка.

Рис. 42. Пример дерева операций для языка арифметических выражений
Дерево операций является формой внутреннего представления программы, которой удобно пользоваться на этапах синтаксического разбора, семантического анализа и подготовки к генерации кода, когда еще нет необходимости работать непосредственно с кодами команд результирующей программы.
Преимущества внутреннего представления в виде дерева операций:
1) четко отражает связь всех операций между собой, поэтому его удобно использовать для преобразований, связанных с перестановкой и переупорядочиванием операций без изменений конечного результата;
2) синтаксические деревья – это машинно-независимая форма внутреннего представления программы.
Недостаток синтаксических деревьев заключается в том, что они представляют собой сложные связанные структуры, а поэтому не могут быть тривиальным образом преобразованы в линейную последовательность команд результирующей программы. Тем не менее, они удобны при работе с внутренним представлением программы на тех этапах, когда нет необходимости непосредственно обращаться к командам результирующей программы.
Синтаксические деревья могут быть преобразованы в другие формы внутреннего представления программы, представляющие собой линейные списки, с учетом семантики входного языка. Эти преобразования выполняются на основе принципов СУ-компиляции.
Источник
16. Построение дерева синтаксического разбора.
Дерево разбора может рассматриваться как графическое представление порождения, из которого удалена информация о порядке замещения не терминалов.
Каждый внутренний узел дерева представляет применение продукции.
Внутренний узел дерева помечен нетерминалом А из заголовка соответствующей продукции, а дочерние узлы слева направо символами из тела продукции, использованные в порождении для замены А.
Например, дерево для разбора – (id+id):
Листья дерева разбора не терминальными или терминальными и будучи прочитаны слева на право, образуют сентенциальную форму называемую кроной или границей дерева.
Для того что бы увидеть связь между порождениями и деревьями разбора рассмотрим произвольное приведение. α1 → α2 → … → αn
Где альфа 1 отдельный не терминал А.
Для каждой сентенциальной формы альфа 1 можно построить дерево разбора, кроной которого является альфа 1 этот процесс представляет собой индукцию по i.
Пример, последовательность деревьев разбора:
Для моделирования этого шага корню Е в начало дерева добавляют два дочерних узла помеченных «-» и «Е».
2) – E => — (E) добавляют 3 дочерних узла, помеченных (, Е, ) к листу Е для получения дерева с кроной – (Е).
Продолжая построение описываемым способом получается полноценное дерево разбора.
Т.к. дерево разбора игнорирует порядок, в котором производилось замещение символов в сентенциальной форме, между порождениями и деревьями возникает соотношение «многих к одному».
Каждое дерево связано с единственным левым и единственным правым порождением.
17. Нисходящий синтаксический анализ
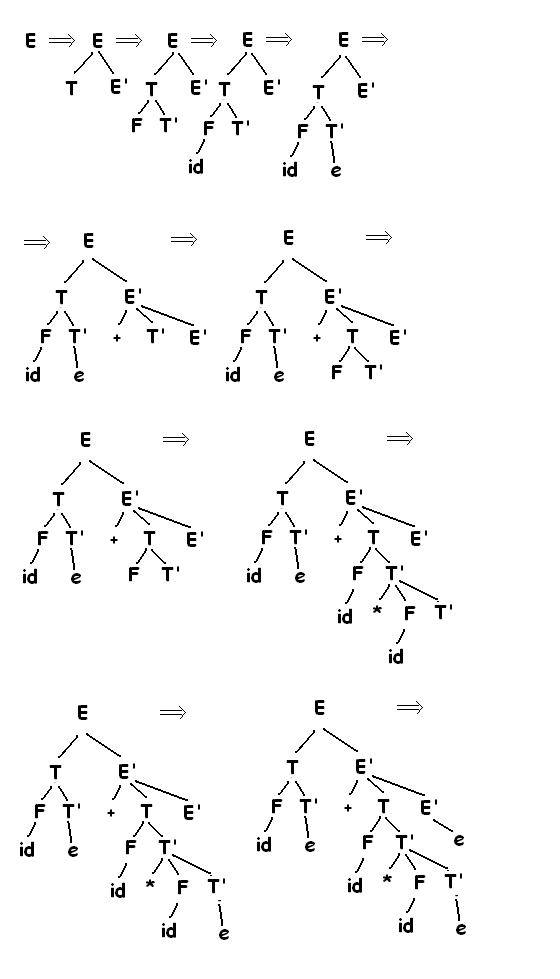
Можно рассмотреть как поиск левого порождения входящей строки. Рассмотрим последовательность построений деревьев разбора для входящей строки (id+id)*id, представляющий собой нисходящий синтаксический анализ, построенный в соответствии с грамматикой:
Эта последовательность деревьев соответствует левому порождению входящей строки. На каждом шаге нисходящего синтаксического анализа ключеваой проблемой является определение продукции, применимой для нетерминалов, например А. Когда А продукция выбрана, остальные части процесса синтаксического анализа состоят из проверки соответвствий терминальных символов в теле продукции входящей строки. В рассмотренном примере строится дерево с двумя узлами, помеченными E’, в первом (в прямом) порядке обхода узла Е’ выбирается продукция
E’ -> +TE’, во втором E’ -> e. Синтаксический анализатор может выбрать нужную E’ продукцию, рассматривающую очередной входящий символ. Класс Грамматик для которых можно построить синтаксический анализатор, просматривающий k-символов во входящем потоке называется классом LL(k).
Метод рекурсивного спуска
Программа синтаксического анализатора методом рекурсивного спуска состоит из набора процедур по одной для каждого нетерминала. Работа программы начинается с вызова процедуры для стартового символа и успешно заканчивается в случае сканирования всей входящей строки.
Типичная процедура для нетерминала низходящего анализатора
If (Xi-нетерминал) Вызов процедуры Xi();
else if(Xi равно текущему входному символу a)
Переход к следующему входному символу
Этот псевдокод недетерминирован т.к. он начинается с выбором А-продукции не указанным способом.
Рекурсивный способ в общем случае может потребовать выполнения возврата т.е. повторения сканирования входного потока. При анализе синтаксической конструкции языка программирования возврат требуется редко. В ситуациях , наподобие, синтаксического анализа естественного языка возврат не слишком эффективен и предпочтительней являются табличные методы. Чтобы разрешить возврат код в примере должен быть модифицирован:
- Невозможно выбрать единую А-продукцию в строке (1), поэтому требуется испытывать каждую из нескольких продукций в некотором порядке.
- Ошибка в строке (*) не является окончательной и предполагает возворат к строке (1) и испытание другой А-продукции.
Объявлять о найденной во входной строке ошибке можно только в том случае, если больше не имеется непроверенных А-продукций.
Чтобы построить дерево разбора для входной строки ω-cod начинают с дерева, состоящего из единичного узла с меткой S и указателя входного потока, указывающего на С или первый символ ω.
S имеет единичную продукцию, поэтому ее используют для разворачивания и получения дерева.
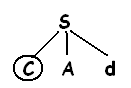
Соответствует первому символу входного потока ω, поэтому указатель входного потока перемещается к а-второму символу ω и рассматривается следующий лист, помеченный А.
Затем разворачивается А с использованием альтернативы А -> ab и получаем таким образом дерево, показанное на рис.
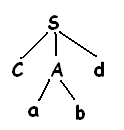
Имеется совпадение второго входного символа а, поэтому выполняется переход к третьему символу d и сравнивают его с очередным листком b. Т.к. b не соответствует d, то сообщается об ошибке и происходит возврат к А.
Чтобы выяснить нет ли альтернативной продукции, которая не была проверена до этого времени, вернувшись к а необходимо отбросить указатель входного потока так, чтобы он указывал на позицию 2, в которой указатель находится, когда впервые столкнулся с а. Это означает что процедура для а должна хранить указатель на входной поток в локальной переменной.
Вторая альтернатива для а дает дерево разбора:
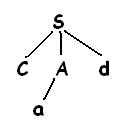
Лист а соответствует второму символу ω, а лист d – третьему символу. Т.к. построено дерево разбора для входящей строки ω, то алгоритм завершает работу и сообщает об успешном выполнении синтаксического анализа и построении дерева разбора. Левосторонняя грамматика может привести синтаксический анализатор, работающий методом рекурсивного спуска к бесконечному циклу, т.е. когда пытаются проверить нетерминал а, то в конечном счете можно найти этот же нетерминал а и перейти к попытке развернуть а, так и не взяв ни одного символа из входного потока.
Источник