- Обход дерева – центрированный (inorder), прямой (preorder) и обратный (postorder) (три основных способа обхода)
- Центрированный тип обхода (Inorder traversal)
- Прямой тип обхода (Preorder traversal)
- Обратный тип обхода (Postorder traversal)
- Бинарное дерево. Способы обхода и удаления вершин
- Алгоритм обхода в глубину
- Удаление вершин бинарного дерева
- Удаление листовых вершин
- Удаление узла с одним потомком
- Удаление узла с двумя потомками
Обход дерева – центрированный (inorder), прямой (preorder) и обратный (postorder) (три основных способа обхода)

Обход дерева означает посещение каждого узла дерева. Например, вы можете добавить все значения в дерево или найти самое большое. Для всех этих операций вам необходимо будет посетить каждый узел дерева. Линейные структуры данных, такие как массивы, стеки, очереди и связанный список, имеют только один способ чтения данных. Но иерархическая структура данных, такая как дерево, может проходить разными способами. Давайте подумаем о том, как мы можем прочитать элементы дерева на изображении, показанном выше. Начиная сверху, слева направо
Начиная снизу, слева направо
Хотя этот процесс в некотором роде прост, он не учитывает иерархию дерева, а только глубину узлов. Вместо этого мы используем методы обхода, которые учитывают базовую структуру дерева, то есть

Помните, что нашей задачей является посещение каждого узла, поэтому нам нужно посетить все узлы в поддереве, посетить корневой узел и также посетить все узлы в правом поддереве.
В зависимости от порядка, в котором мы это делаем, может быть три типа обхода .
Центрированный тип обхода (Inorder traversal)
- Сначала посетите все узлы в левом поддереве
- Затем корневой узел
- Посетите все узлы в правом поддереве
inorder(root->left) display(root->data) inorder(root->right)Прямой тип обхода (Preorder traversal)
- Посетите корневой узел
- Посетите все узлы в левом поддереве
- Посетите все узлы в правом поддереве
display(root->data) preorder(root->left) preorder(root->right)Обратный тип обхода (Postorder traversal)
- посетить все узлы в левом поддереве
- посетить корневой узел
- посетить все узлы в правом поддереве
postorder(root->left) postorder(root->right) display(root->data)Давайте визуализируем центрированный тип обхода (inorder traversal). Начнем с корневого узла.
Сначала мы проходим левое поддерево. Мы также должны помнить, что нужно посетить корневой узел и правое поддерево, когда дерево будет готово.
Давайте поместим все это в стек, чтобы мы помнили.
Теперь перейдем к поддереву, указанному на вершине стека.
Опять же, мы следуем тому же правилу центрированного типа (inorder)
Left subtree -> root -> right subtreeПройдя левое поддерево, мы остаемся с
Поскольку у узла "5" нет поддеревьев, мы печатаем его напрямую. После этого мы печатаем его родительский узел «12», а затем правый дочерний «6».
Поместить все в стек было полезно, потому как теперь, когда левое поддерево корневого узла было пройдено, мы можем распечатать его и перейти к правому поддереву.
После прохождения всех элементов, центрированный тип обхода (inorder traversal) выглядит так:
Нам не нужно создавать стек самостоятельно, потому что рекурсия поддерживает для нас правильный порядок.
Полный код для центрированного (inorder), прямого (preorder) и обратного (postorder) типа обхода на языке программирования C размещен ниже:
#include #include struct node < int data; struct node* left; struct node* right; >; void inorder(struct node* root)< if(root == NULL) return; inorder(root->left); printf("%d ->", root->data); inorder(root->right); > void preorder(struct node* root)< if(root == NULL) return; printf("%d ->", root->data); preorder(root->left); preorder(root->right); > void postorder(struct node* root) < if(root == NULL) return; postorder(root->left); postorder(root->right); printf("%d ->", root->data); > struct node* createNode(value)< struct node* newNode = malloc(sizeof(struct node)); newNode->data = value; newNode->left = NULL; newNode->right = NULL; return newNode; > struct node* insertLeft(struct node *root, int value) < root->left = createNode(value); return root->left; > struct node* insertRight(struct node *root, int value)< root->right = createNode(value); return root->right; > int main()< struct node* root = createNode(1); insertLeft(root, 12); insertRight(root, 9); insertLeft(root->left, 5); insertRight(root->left, 6); printf("Inorder traversal \n"); inorder(root); printf("\nPreorder traversal \n"); preorder(root); printf("\nPostorder traversal \n"); postorder(root); >Вывод кода будет выглядеть так:
Inorder traversal 5 ->12 ->6 ->1 ->9 -> Preorder traversal 1 ->12 ->5 ->6 ->9 -> Postorder traversal 5 ->6 ->12 ->9 ->1 ->
Рекомендуем хостинг TIMEWEB
Стабильный хостинг, на котором располагается социальная сеть EVILEG. Для проектов на Django рекомендуем VDS хостинг.
Рекомендуемые статьи по этой тематике
По статье задано0 вопрос(ов)
Вам это нравится? Поделитесь в социальных сетях!
Источник
Бинарное дерево. Способы обхода и удаления вершин
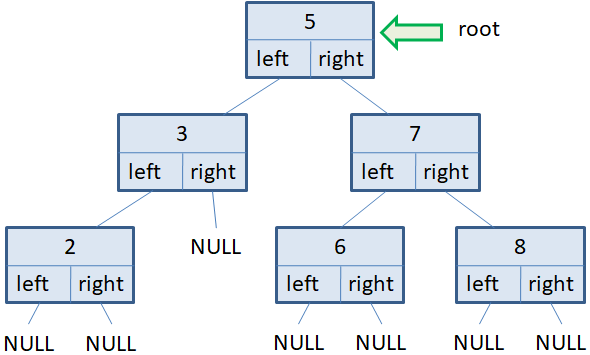
Давайте представим, что у нас имеется следующее двухуровневое бинарное дерево: На корневую вершину ведет указатель root. Создадим еще один вспомогательный указатель p на эту же вершину:
Изначально в списке только одна корневая вершина. Сформируем два цикла: первый будет работать, пока список вершин не пуст, то есть, пока в дереве имеются узлы текущего уровня; а второй будет перебирать вершины текущего уровня, выводить информацию на экран и формировать список следующего уровня:
while v: vn = [] for x in v: print(x.data) if x.left: vn += [x.left] if x.right: vn += [x.right] v = vnВ результате, сначала будет выведено значение 7 корневого узла. Затем, сформирован список vn из двух узлов следующего уровня в порядке слева-направо. После этого списку v присваивается новый сформированный список vn следующего уровня и на следующей итерации цикла while во вложенном цикле for будут перебираться уже вершины первого уровня. На экран выведутся значения 2 и 5. Снова сформируется список vn из вершин следующего второго уровня. И на следующей итерации цикла while будут выведены значения 3, 4 и 6. После этого список vn окажется пустым, следовательно, список v также будет пустой и цикл while завершит свою работу. Вот пример реализации алгоритма перебора вершин бинарного дерева в ширину в самом простом варианте. При этом мы обходим по всем узлам дерева ровно один раз.
Алгоритм обхода в глубину
Следующий тип алгоритмов – это обход дерева в глубину. Здесь мы проходим по определенной ветви до листовой вершины. Лучше всего показать этот ход на конкретном примере. Пусть у нас то же самое бинарное дерево. Начальная вершина, как всегда, корневая (root). Затем, мы должны для себя решить, по какой из двух ветвей идти в первую очередь, а по какой – во вторую. Я решил обойти дерево сначала по левой ветви, а затем, с возвратами проходить правые ветви. Это можно реализовать следующей рекурсивной функцией:
def show_tree(self, node): if node is None: return self.show_tree(node.left) print(node.data) self.show_tree(node.right)Как она работает? Мы начинаем двигаться от корневого узла. Если он существует, то вызывается та же самая функция для левого узла. В результате, мы как бы попадаем в ту же самую функцию, только параметр node теперь является ссылкой на узел со значением 3. Здесь выполняется та же самая проверка: если узел существует, то по рекурсии мы снова переходим к следующему левому узлу. Это узел со значением 2. Снова делается проверка на его существование и, так как он существует, переходим к следующему левому узлу. Теперь параметр node принимает значение None (на рисунке NULL), рекурсия завершается и мы возвращаемся к прежнему вызову с параметром node узла 2. Это значение отображается на экране и делается попытка пройти по правой ветви. Так как справа объектов нет, то вызов текущей функции завершается и мы попадаем в функцию уровнем выше с параметром node на узел 3. Это значение 3 выводится на экран и делается попытка пройти по правой ветви. Ее нет, поэтому мы возвращаемся на уровень выше, то есть, к корневому узлу со значением 5. Это значение выводится на экран и далее мы переходим к правой вершине 7. Снова вызывается рекурсивная функция с параметром node на узел 7 и делается попытка пройти по левой ветви. Там имеется вершина со значение 6. Она выводится на экран с возвратом к функции узла 7. Затем, отображаем эту семерку на экран и переходит к левому узлу со значением 8. Это значение также отображается, после чего все вызовы рекурсивных функций завершаются. В результате мы на экране увидим следующие значения, записанные в вершинах бинарного дерева: 2, 3, 5, 6, 7, 8 Вы можете подумать, что такой возрастающий порядок значений получился чисто случайно. Однако нет. Если у нас имеется бинарное дерево сформированное по правилу добавления меньших значений в левую ветвь, а больших – в правую, то при обходе дерева в глубину в порядке: левое поддерево (L); промежуточная вершина (N); правое поддерево (R) всегда будет образовываться возрастающая последовательность чисел. Сокращенно такой алгоритм в глубину получил название LNR и относится к симметричному типу обхода. А если пройти сначала по правой ветви, затем вывести значение промежуточной вершины, а после пройти по левой ветви, то получим убывающую последовательность значений в бинарном дереве: 8, 7, 6, 5, 3, 2 Такой алгоритм сокращенно называется RNL и также является одним из видов симметричного обхода. Комбинируя различные варианты обхода и отображения значений вершин можно получать самые разнообразные вариации алгоритмов обхода в глубину.
Удаление вершин бинарного дерева
Теперь, когда мы с вами подробно разобрались в способах формирования бинарного дерева и алгоритмами обхода его вершин, остался один важный вопрос, связанный с удалением его узлов. Здесь возможны несколько типовых исходов.
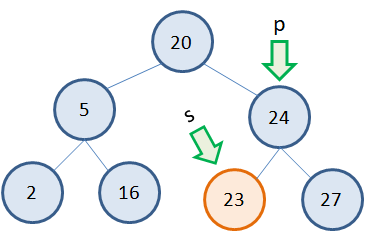
Удаление листовых вершин
Самый простой случай, когда удаляется листовой узел дерева. Предположим, что это узел 23: Тогда, нам достаточно получить указатель p на родительский узел и указатель s на удаляемый узел. Сделать это очень просто, запоминая при обходе дерева предыдущую (родительскую) вершину и текущую. После этого ссылку, ведущую на удаляемый узел следует приравнять NULL и освободить память из под узла s:
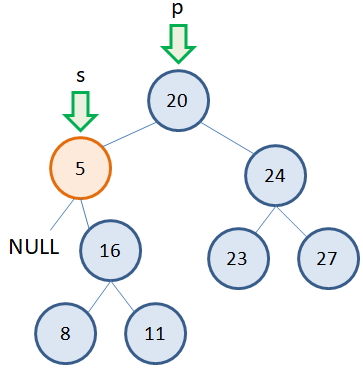
Удаление узла с одним потомком
Также относительно просто обстоит ситуация, когда у удаляемого узла имеется один потомок (слева или справа). Например, нам нужно удалить узел 5, у которого один потомок справа: Здесь мы также должны иметь два указателя: p – на родительскую вершину; s – на удаляемую вершину. Затем, исключаем из дерева удаляемую вершину 5, меняя связь от родительской вершины 20 к вершине 16 (которая идет после удаляемой):
Причем, ситуация принципиально не меняется, если у удаляемой вершины один правый или левый потомок. Алгоритм удаления таких вершин работает похожим образом.
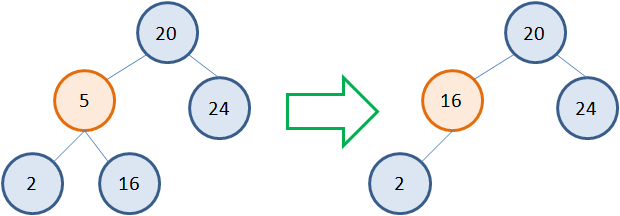
Удаление узла с двумя потомками
Несколько сложнее обстоит дело, когда у удаляемой вершины два потомка. Общая идея здесь такая. Сам узел не удаляется, меняется только его значение на новое. А новое берется как наименьшее из правой ветви. Например, если мы хотим удалить узел 5, то следует взять наименьшее значение 16 из правого поддерева. Записать его вместо 5, а листовой узел 16 просто удалить:
Но это если справа расположен листовой узел. А что если справа имеется полноценное поддерево с множеством вершин? Как быть в такой ситуации? По сути, также. Идея алгоритма остается прежней. Выбираем узел с наименьшим значением 11 в правом поддереве, заменяем 5 на 11 и удаляем листовой узел 11:
В результате получаем дерево: Вот основные типовые варианты удаления вершин в бинарном дереве:



 Но это если справа расположен листовой узел. А что если справа имеется полноценное поддерево с множеством вершин? Как быть в такой ситуации? По сути, также. Идея алгоритма остается прежней. Выбираем узел с наименьшим значением 11 в правом поддереве, заменяем 5 на 11 и удаляем листовой узел 11:
Но это если справа расположен листовой узел. А что если справа имеется полноценное поддерево с множеством вершин? Как быть в такой ситуации? По сути, также. Идея алгоритма остается прежней. Выбираем узел с наименьшим значением 11 в правом поддереве, заменяем 5 на 11 и удаляем листовой узел 11: 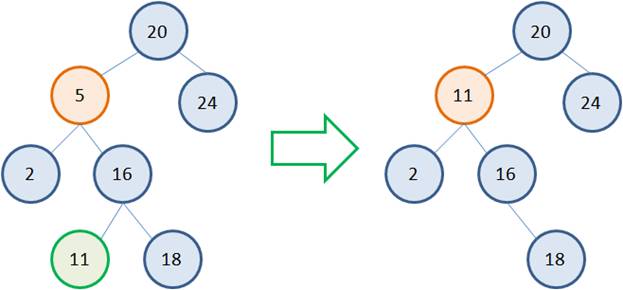 Но вершина с наименьшим значением в правом поддереве не всегда является листовой. Возможны и такие ситуации:
Но вершина с наименьшим значением в правом поддереве не всегда является листовой. Возможны и такие ситуации: 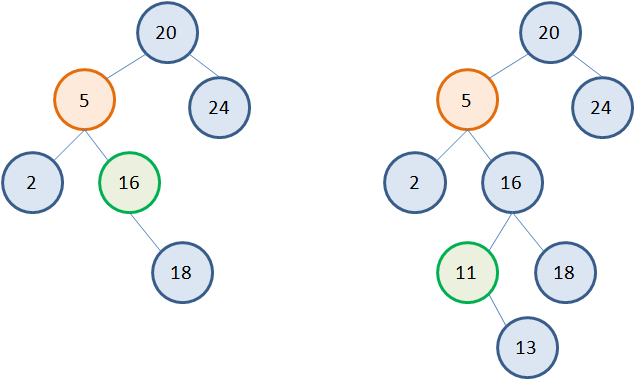 Однако можно заметить, что у узла с наименьшим значением может быть только один потомок справа. А значит, его удаление будет выполняться по алгоритму удаления вершин с одним потомком. Например, рассмотрим второе дерево. Нам потребуется три указателя: t – на удаляемую вершину (то есть, вершину, у которой будет меняться значение); s – на вершину с наименьшим значением в правом поддереве; p – на родительскую вершину для вершины s:
Однако можно заметить, что у узла с наименьшим значением может быть только один потомок справа. А значит, его удаление будет выполняться по алгоритму удаления вершин с одним потомком. Например, рассмотрим второе дерево. Нам потребуется три указателя: t – на удаляемую вершину (то есть, вершину, у которой будет меняться значение); s – на вершину с наименьшим значением в правом поддереве; p – на родительскую вершину для вершины s: 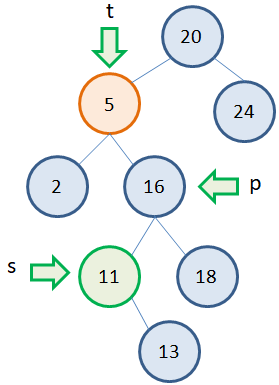 Затем, мы меняем значение вершины 5 на 11:
Затем, мы меняем значение вершины 5 на 11: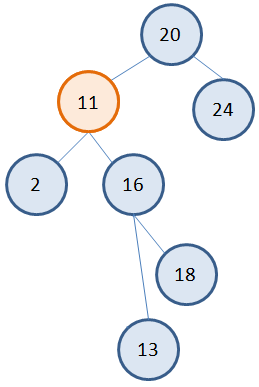
- удаление листового узла;
- удаление узла с одним потомком (правым или левым);
- удаление узла с двумя потомками.
На следующем занятии, в качестве примера, реализуем бинарное дерево на языке Python, чтобы вы во всех деталях понимали принцип его работы. Курс по структурам данных: https://stepik.org/a/134212
Источник