19. Структура больших файлов и каталогов в ntfs. Индексация файлов в ntfs.
Здесь мы будем говорить о структуре каталогов NTFS. Каталог в NTFS представляет собой индекс имён файлов, то есть список имён, упорядоченных по любому признаку. В настоящий момент упорядочивание файлов происходит только по имени. Для индексации или упорядочивания используется b+ дерево.
В случае больших каталогов списки файлов располагаются в отрезках. Атрибут корень индекса содержит первый уровень структуры b+ дерева и указывает на индексные буферы, содержащие следующий уровень. То есть в данном случае корень индекса создаёт только несколько имён. Атрибут корень индекса и каждый отрезок, содержащий список файлов, содержащий имя файла, файловую ссылку на запись MFT, метку времени и информацию о размере файла. Эта информация дублируется из соответствующих записей. Дублируется для того, чтобы ускорить просмотр. Атрибут размещения индекса содержит отображение VCN-LCN для индексных буферов.
Битовая карта используется для отслеживания того, какие VCN в индексных буферах заняты, а какие свободны. Каждый индексный буфер размером 2 Кб может содержать около 15 записей для имён файлов. Это 3-4 записи на кластер, размером 512 байт. Рассмотрим пример. Файл f4 – это элемент первого уровня b+ дерева, он указывает на индексный буфер, содержащий имена файлов, которые меньше чем f4 (в смысле символа). Например, мы создали файл с именем f31. Он будет расположен раньше, чем f4.
Хранение имён файлов в виде b+ дерева даёт следующие преимущества:
- Поиск в каталоге выполняется быстрее.
- Так как b+ дерево имеет тенденцию к росту в ширину, а не в глубину, то скорость поиска не уменьшается с ростом каталогов.
Файловая система NTFS имеет много преимуществ по сравнению с FAT. Она умеет управлять дисками размером до нескольких сотен терабайт (один терабайт равен миллиону мегабайт). Далее, NTFS гораздо лучше обращается с местом при работе с большими дисками и умеет исправлять ошибки после сбоев. Делается это через запись в реальном времени всех модификаций файловой системы по контрольным точкам, которые затем используются в случае принудительной перезагрузки.
Master File Table управляет файлами и так называемыми метаданными в относительной структуре базы данных. Ее легко представить в качестве таблицы. Информация относительно файлов размещена в строки, а атрибуты (скрытый, зашифрованный, сжатый, система, и т.д.) — в столбцы. Для больших файлов MFT содержит указатели о месте их нахождения. То же самое и с папками: достаточно маленькие полностью включены в файловую таблицу. NTFS управляет большими папками с помощью так называемой структуры B-tree, которая индексирует похожие файлы или их названия, что ускоряет последующую обработку.
Каталог в NTFS представляет собой индекс имён файлов, то есть список имён, упорядоченных по любому признаку. В настоящий момент упорядочивание файлов происходит только по имени. Для индеек-ии или упоряд-ия используется b+ дерево.
В случае больших каталогов списки файлов располагаются в отрезках. Атрибут корень индекса содержит первый уровень структуры b+ дерева и указывает на индексные буферы, содержащие следующий уровень. То есть в данном случае корень индекса создаёт только несколько имён. Атрибут корень индекса и каждый отрезок, содержащий список файлов, содержащий имя файла, файловую ссылку на запись MFT, метку времени и информацию о размере файла. Эта информация дублируется из соответствующих записей. Дублируется для того, чтобы ускорить просмотр. Атрибут размещения индекса содержит отображение VCN-LCN для индексных буферов.
Хранение имён файлов в виде b+ дерева даёт следующие преимущества:
- Поиск в каталоге выполняется быстрее.
- Так как b+ дерево имеет тенденцию к росту в ширину, а не в глубину, то скорость поиска не уменьшается с ростом каталогов.
Источник
Структура хранения информации о составе каталога в файловой системе NTFS
Аннотация:
Уткин П.С., Чередникова О.Ю. Структура хранения информации о составе каталога в файловой системе NTFS. Выполнен обзор утилит, позволяющих просмотреть структуру информации в файловой системе NTFS. Проанализирована структура индексных записей. Разработано приложение, позволяющее просматривать информацию в NTFS-разделе.
Общая постановка проблемы
Для специалистов, занятых разработкой утилит для операционных систем, и, в частности файловых систем, важно понимать структуру хранения информации на логическом диске. Использование знаний о структуре существующих файловых систем также позволяет создавать новые файловые системы, используя преимущества имеющихся. Одной из самых используемых файловых систем операционных систем семейства Windows NT на сегодняшний день, является файловая система NTFS. Однако ее структуру нельзя назвать простой. В частности, способ хранения информации о составе директории в виде В-дерева, состоящего из индексных записей, не является очевидным. Поэтому актуальной является задача разработки программного приложения, позволяющего в удобном для пользователя виде отобразить структуру каталога NTFS-раздела.
Обзор утилит для анализа внутренней структуры NTFS-раздела
Из существующих решений одним из самых популярных является приложение DiskEditor (рис.1), которое обеспечивает чтение, запись, редактирование содержимого как физического, так и логического раздела. Информация выводится шестнадцатеричными кодами, а также разбита на полям в соответствии с выбранным шаблоном. Системные программисты могут использовать данную программу для понимания структуры данных и проверки правильности их реализации. Однако DiskEditor не может предоставить программисту полной структуры индексных записей каталога NTFS-раздела, т.е. не содержит шаблона для отображения информации в виде отдельных полей. Анализ структуры индексных записей с помощью этой утилиты приходится выполнять по шестнадцатеричным кодам.
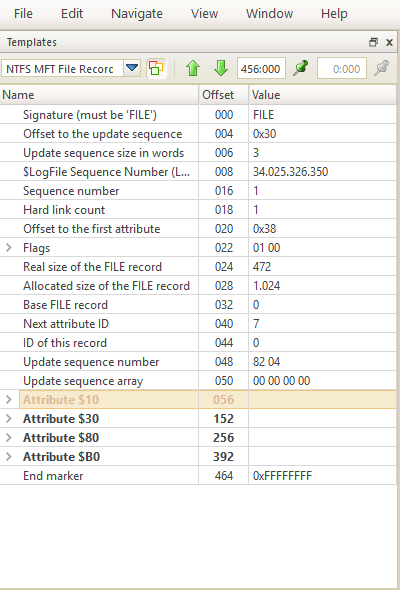
Так же существует программа DiskExplorer for NTFS, благодаря которой системный программист может увидить содержимое индексных узлов каталога и получить ссылку на их записи в MFT-таблице (рис.2).
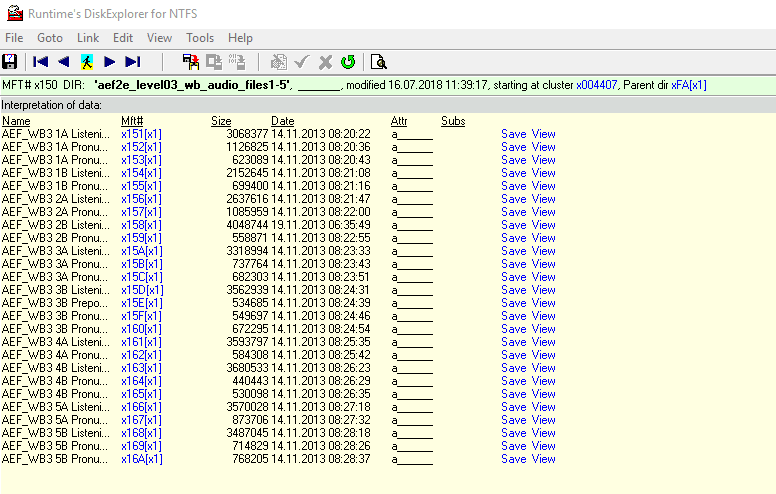
Однако приложение DiskExplorer также не отображает структуру В-дерева. Поэтому целью работы является разработка программного обеспечения для просмотра и анализа NTFS раздела, отображения структуры индексных записей в виде B-деревьев.
Структура хранения информации о составе каталога в NTFS
Все данные в NTFS – это файлы и информация о них храниться в MFT-таблице (аббревиатура с англ. Master File Table). Каждый файл или каталог в файловой системе представлен как запись в MFT-таблице. Размер записи составляет 1 Кбайт. Первые 42 байта содержат в себе заголовок записи MFT. Остальные байты записи хранят в себе атрибуты файла. Атрибут записи – это небольшая структура данных, которая служит для хранения к примеру имени, или содержимого файла (рис.3) [1].

Один из флагов в заголовке записи MFT показывает, что запись описывает каталог. Содержимое каталога сгруппировано в виде В-дерева.
B-дерево — сильноветвящееся сбалансированное дерево поиска, позволяющее проводить поиск, добавление и удаление элементов. B-дерево может применяться для структурирования информации (как правило, метаданных). Время доступа к произвольному блоку очень велико. Поэтому важно уменьшить количество узлов, просматриваемых при каждой операции. Использование поиска по списку каждый раз для нахождения случайного блока могло бы привести к чрезмерному количеству обращений к диску вследствие необходимости последовательного прохода по всем его элементам, предшествующим заданному, тогда как поиск в B-дереве, благодаря свойствам сбалансированности и высокой ветвистости, позволяет значительно сократить количество таких операций [2]. Принцип хранения информации о составе каталога в виде В-дерева следующий: узел дерева хранит имена файлов (атрибут $FILE_NAME) отсортированными. Узел может иметь дочерние узлы, количество которых всегда на единицу больше, чем количество файлов в узле (рис.4) [3]. Самый левый дочерний узел содержит в себе имена, которые в отсортированном списке предшествуют первому имени файла узла. Следующий дочерний узел содержит имена файлов, находящихся в диапазоне между первым и вторым элементом родительского узла в отсортированном списке имен файлов каталога и т.д.
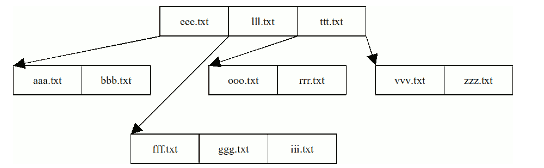
Для реализации В-дерева в NTFS используется понятие индекса, которое пришло из баз данных. Индекс — это коллекция элементов, хранящихся в отсортированном порядке. В качестве индексного элемента может выступать любой атрибут, по которому будет производиться индексация. Для индексов каталогов это всегда атрибут $FILE_NAME, для каждого файла или каталога, содержащегося в нем. На каждый файл или каталог приходится как минимум две структуры FILE_NAME, первый как атрибут у файла, а второй, используемый для индекса. Узел дерева хранит последовательность атрибутов $FILE_NAME [4].
Для хранения узлов дерева используются два типа атрибутов $INDEX_ROOT, который присутствует всегда для любой директории и $INDEX_ALLOCATION, который может и не присутствовать для небольших каталогов.
Атрибут $INDEX_ROOT представляет собой корневой узел индексного дерева. Индексное дерево состоит из индексных элементов, которые являются файлами или каталогами. Атрибут INDEX_ALLOCATION не ограничен по количеству узлов и поэтому он будет содержать индексные элементы, которые не поместились в INDEX_ROOT.
Атрибут $INDEX_ROOT представляет собой корневой узел индексного дерева. Индексное дерево состоит из индексных элементов, которые являются файлами или каталогами. Атрибут INDEX_ALLOCATION не ограничен по количеству узлов и поэтому он будет содержать индексные элементы, которые не поместились в INDEX_ROOT.
- Чтение первого сектора логического диска для определения расположения MFT-таблицы и других параметров раздела;
- Организация цикла чтения записей MFT. Для каждой записи производится анализ ее заголовка и атрибутов.
- Определение записи, принадлежащей каталогу и считывание его атрибута $INDEX_ROOT. Перебор всех элементов индексного узла. Для перехода от одного элемента к другому следует к адресу индексного элемента добавлять смещение следующего элемента относительно текущего.
- Определение наличия дочерних узлов В-дерева и считывание атрибута $INDEX_ALLOCATION. Атрибут представляет собой последовательность индексных записей, количество которых может быть вычислено делением размера атрибута на размер индексной записи. Зная количество индексных записей, их можно обойти как линейный массив элементов. Каждая индексная запись состоит из индексных узлов, которые просматриваются аналогично индексным узлам атрибута $INDEX_ROOT.
В ходе разработки были использованы основные особенности ООП, такие как классы, методы, интерфейсы, инкапсуляция, полиморфизм и наследование. Функциональные возможности разработанного приложения включают в себя чтение MFT-таблицы, перемещаться по записям MFT-таблицы, а так демонстрацию пользователю структуры индексных записей каталога в виде списка.

Выводы
Разработанное приложение позволяет в удобном для пользователя виде увидеть структуру информации на логическом диске с файловой системой NTFS. Приложение может быть использовано студентами IT-специальностей при изучении дисциплины «Операционные системы», а также специалистами в области системного программного обеспечения для анализа структуры информации в файловой системе NTFS. Дальнейшие исследования и разработки связаны со структуризацией списка индексных записей каталога в виде B-дерева, переходом к связанной MFT-записи из узла B-дерева, улучшением интерфейса пользователя.
Список источников
- Кэрриэ Б. Криминалистический анализ файловых систем [Текст]. – СПб.: Питер, 2007. – 480 с.: ил.
- Руссинович М., Соломон Д. Внутреннее устройство Microsoft Windows. 6-е изд. – СПб.: Питер, 2013. – 800 с.: ил. – (Серия «Мастер-класс»)
- Кастер Х. Основы Windows NT и NTFS : [Пер. с англ.] / Хелен Кастер. — М. : Изд. отд. «Рус. редакция», 1996. — 436 с. : ил.
- Таненбаум Э., Бох С. Современные операционные системы. 4-е изд. — СПб.: 2015. – 1120с.
Источник