- Деревья поиска
- Бинарные деревья поиска
- Дерево двоичного поиска
- Чем отличается от обычного двоичного дерева
- Операции с двоичным деревом поиска
- Поиск элемента
- Вставка элемента
- Удаление элемента
- Случай I: лист
- Случай II: есть дочерний элемент
- Случай III: два дочерних элемента
- Реализация на языках программирования
- Python
- Java
- C
- C++
- Где используется
Деревья поиска
Дерево — одна из наиболее распространенных структур данных в программировании.
Деревья состоят из набора вершин (узлов, нод) и ориентированных рёбер (ссылок) между ними. Вершины связаны таким образом, что от какой-то одной вершины, называемой корневой (вершина 8 на рисунке), можно дойти до всех остальных единственным способом.
- Родитель вершины $v$ — вершина, из которой есть прямая ссылка в $v$.
- Дети (дочерние элементы, сын, дочь) вершины $v$ — вершины, в которые из $v$ есть прямая ссылка.
- Предки — родители родителей, их родители, и так далее.
- Потомки — дети детей, их дети, и так далее.
- Лист (терминальная вершина) — вершина, не имеющая детей.
- Поддерево — вершина дерева вместе со всеми её потомками.
- Степень вершины — количество её детей.
- Глубина вершины — расстояние от корня до неё.
- Высота дерева — максимальная из глубин всех вершин.
Деревья чаще всего представляются в памяти как динамически создаваемые структуры с явными указателями на своих детей, либо как элементы массива связанные отношениями, неявно определёнными их позициями в массиве.
Деревья также используются в контексте графов.
Бинарные деревья поиска
Бинарное дерево поиска (англ. binary search tree, BST) — дерево, для которого выполняются следующие свойства:
- У каждой вершины не более двух детей.
- Все вершины обладают ключами, на которых определена операция сравнения (например, целые числа или строки).
- У всех вершин левого поддерева вершины $v$ ключи не больше, чем ключ $v$.
- У всех вершин правого поддерева вершины $v$ ключи больше, чем ключ $v$.
- Оба поддерева — левое и правое — являются двоичными деревьями поиска.
Более общим понятием являются обычные (не бинарные) деревья поиска — в них количество детей может быть больше двух, и при этом в «более левых» поддеревьях ключи должны быть меньше, чем «более правых». Пока что мы сконцентрируемся только на двоичных, потому что они проще.
Чаще всего бинарные деревья поиска хранят в виде структур — по одной на каждую вершину — в которых записаны ссылки (возможно, пустые) на правого и левого сына, ключ и, возможно, какие-то дополнительные данные.
Как можно понять по названию, основное преимущество бинарных деревьев поиска в том, что в них можно легко производить поиск элементов:
Эта функция — как и многие другие основные, например, вставка или удаление элементов — работает в худшем случае за высоту дерева. Высота бинарного дерева в худшем случае может быть $O(n)$ («бамбук»), поэтому в эффективных реализациях поддерживаются некоторые инварианты, гарантирующую среднюю глубину вершины $O(\log n)$ и соответствующую стоимость основных операций. Такие деревья называются сбалансированными.
Источник
Дерево двоичного поиска
Дерево двоичного поиска — это структура данных, которая позволяет быстро работать с отсортированном списком чисел.
- Дерево двоичное, потому что у каждого узла не более двух дочерних элементов.
- Дерево поиска, потому что его можно использовать для проверки вхождения числа — за время O(log(n)) .
Чем отличается от обычного двоичного дерева
- Все узлы левого поддерева меньше корневого узла.
- Все узлы правого поддерева больше корневого узла.
- Оба поддерева каждого узла тоже являются деревьями двоичного поиска, т. е. также обладают первыми двумя свойствами.
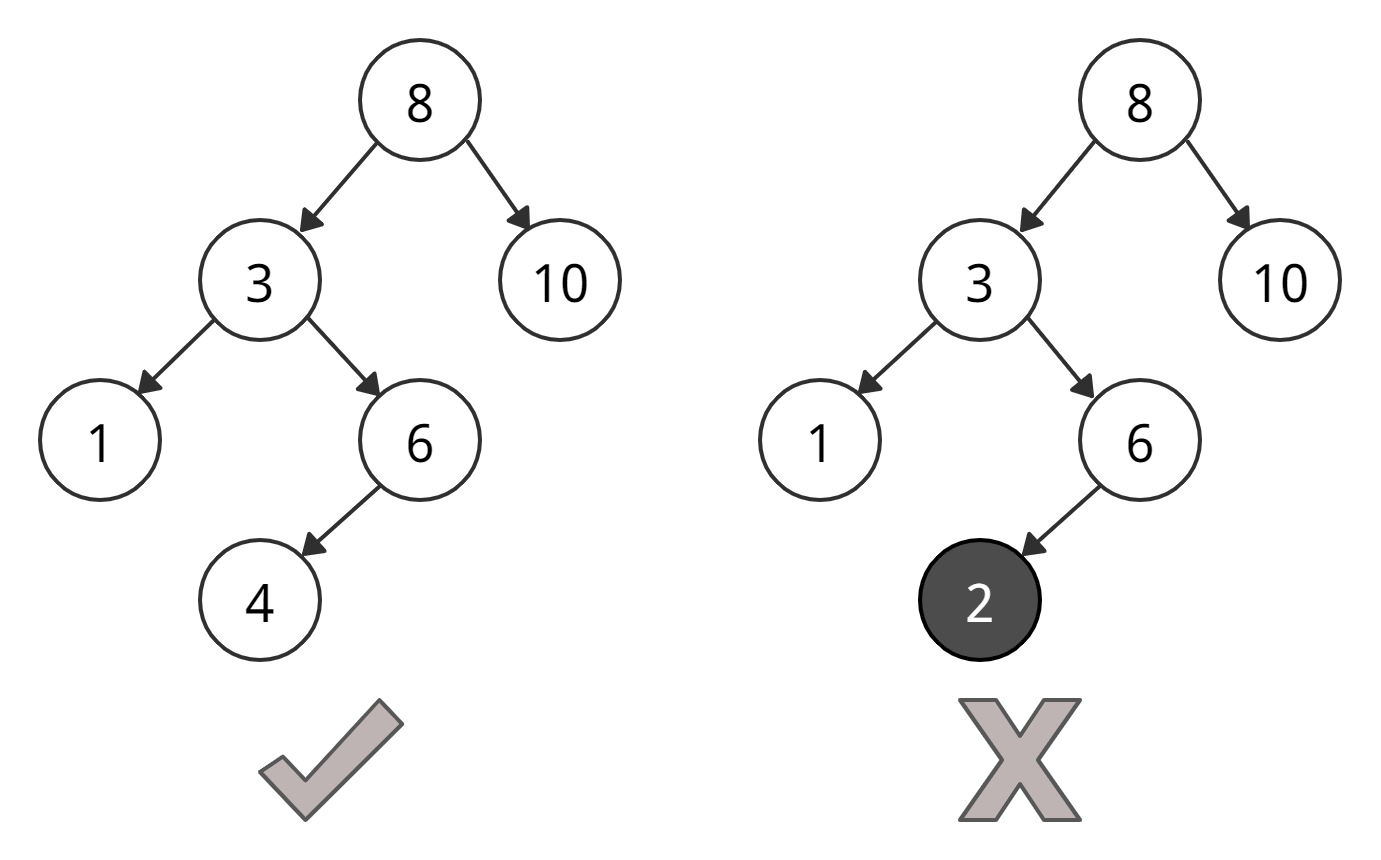
У правого дерева есть поддерево со значением 2, которое меньше, чем корень 3 — таким дерево двоичного поиска быть не может.
Операции с двоичным деревом поиска
Поиск элемента
Сложность в среднем: O(log n)
Сложность в худшем случае: O(n)
Алгоритм зависит от свойств дерева: у каждого левого поддерева есть значения, которые ниже корня или у каждого правого поддерева есть значения, которые выше корня.
Если значение ниже корня, мы можем точно сказать, что оно находится не в правильном поддереве. Тогда нам нужно искать только в левом поддереве. А если значение выше корня, можно точно сказать, что значения нет в левом поддереве. Тогда ищем только в правом поддереве.
Алгоритм:
If root == NULL
return NULL;
If number == root->data
return root->data;
If number < root->data
return search(root->left)
If number > root->data
return search(root->right)
Изобразим это на диаграмме.
• Не нашли 4 → идем по левому поддереву корня 8
• Не нашли 4 → идем по левому поддереву корня 3
• Не нашли 4 → идем по левому поддереву корня 6
Если мы нашли значение, мы возвращаем его так, чтобы оно распространялось на каждом шаге рекурсии — рассмотрите рисунок ниже.
Как вы могли заметить, мы четыре раза вызывали search(struct node*) . Когда мы возвращаем новый узел или NULL , значение возвращается снова и снова, пока search(root) не вернет окончательный результат.
Если мы не нашли значение, значит, мы достигли левого или правого дочернего элемента листового узла, который имеет значение NULL — это значение также рекурсивно распространяется и возвращается.
Вставка элемента
Сложность в среднем: O(log n)
Сложность в худшем случае: ΘO(n)
Операция вставки значения похожа на поиск элемента. Мы также придерживаемся правила: левое поддерево меньше корня, правое поддерево — больше.
Мы продолжаем переходить либо к правому поддереву, либо к левому поддереву в зависимости от значения узла, и когда достигаем точки, в которой левое или правое поддерево имеет значение NULL, помещаем туда новый узел.
Алгоритм:
If node == NULL
return createNode(data)
if (data < node->data)
node->left = insert(node->left, data);
else if (data > node->data)
node->right = insert(node->right, data);
return node;
Алгоритм не такой простой, как может показаться на первый взгляд. Давайте визуализируем процесс.
• 4 > 3 → идем через правого «ребенка» 3.
• Левого «ребенка» у 6 нет → вставляем 4 как левый дочерний элемент 6.
Мы вставили узел в нужное место, но нам всё еще нужно выйти из функции, не повредив при этом остальную часть дерева. Здесь пригодится return node; . В случае с NULL , вновь созданный узел возвращается и присоединяется к родительскому узлу, иначе тот же узел возвращается без каких-либо изменений по мере продвижения вверх, пока мы не вернемся к корню.
Таким образом, когда мы будем двигаться обратно вверх по дереву, связи других узлов не изменятся.
Корень возвращаем в конце — так ничего не сломается.
Удаление элемента
Сложность в среднем: O(log n)
Сложность в худшем случае: O(n)
Всего может быть три случая при удаление элемента из дерева двоичного поиска. Давайте рассмотрим каждый.
Случай I: лист
Первый случай — когда нужно удалить листовой элемент. Просто удаляем узел из дерева.
Случай II: есть дочерний элемент
Во втором случае у узла, который мы хотим удалить, есть один дочерний узел. В этом случае действуем так:
• Меняем 6 на 7 и удаляем узел 7.
Случай III: два дочерних элемента
Если у узла, который мы хотим удалить, есть два потомка, делаем так:
- Получаем значение inorder-преемника этого узла.
- Заменяем удаляем узел на inorder-преемника.
- Удаляем inorder-преемника.
• Копируем значение inorder-преемника — 4.
Реализация на языках программирования
Python
# Операции с двоичным деревом поиска на Python # Создаем узел class Node: def __init__(self, key): self.key = key self.left = None self.right = None # Отсортированный (inorder) обход def inorder(root): if root is not None: # Обходим левое поддерево inorder(root.left) # Обходим корень print(str(root.key) + "->", end=' ') # Обходим правое поддерево inorder(root.right) # Вставка элемента def insert(node, key): # Возвращаем новый узел, если дерево пустое if node is None: return Node(key) # Идем в нужное место и вставляет узел if key < node.key: node.left = insert(node.left, key) else: node.right = insert(node.right, key) return node # Поиск inorder-преемника def minValueNode(node): current = node # Найдем крайний левый лист — он и будет inorder-преемником while(current.left is not None): current = current.left return current # Удаление узла def deleteNode(root, key): # Возвращаем, если дерево пустое if root is None: return root # Найдем узел, который нужно удалить if key < root.key: root.left = deleteNode(root.left, key) elif(key >root.key): root.right = deleteNode(root.right, key) else: # Если у узла только один дочерний узел или вообще их нет if root.left is None: temp = root.right root = None return temp elif root.right is None: temp = root.left root = None return temp # Если у узла два дочерних узла, # помещаем центрированного преемника # на место узла, который нужно удалить temp = minValueNode(root.right) root.key = temp.key # Удаляем inorder-преемниа root.right = deleteNode(root.right, temp.key) return root # Тестим функции root = None root = insert(root, 8) root = insert(root, 3) root = insert(root, 1) root = insert(root, 6) root = insert(root, 7) root = insert(root, 10) root = insert(root, 14) root = insert(root, 4) print("Отсортированный обход: ", end=' ') inorder(root) print("\nПосле удаления 10") root = deleteNode(root, 10) print("Отсортированный обход: ", end=' ') inorder(root)Java
// Операции с двоичным деревом поиска на Java // Создаем узел class BinarySearchTree < class Node < int key; Node left, right; public Node(int item) < key = item; left = right = null; >> Node root; BinarySearchTree() < root = null; >void insert(int key) < root = insertKey(root, key); >// Вставляем в дерево элемент Node insertKey(Node root, int key) < // Возвращаем новый узел, если дерево пустое if (root == null) < root = new Node(key); return root; >// Идем в нужное место и вставляем узел if (key < root.key) root.left = insertKey(root.left, key); else if (key >root.key) root.right = insertKey(root.right, key); return root; > void inorder() < inorderRec(root); >// Отсортированный (inorder) обход void inorderRec(Node root) < if (root != null) < inorderRec(root.left); System.out.print(root.key + " ->"); inorderRec(root.right); > > void deleteKey(int key) < root = deleteRec(root, key); >Node deleteRec(Node root, int key) < // Возвращаем, если дерево пустое if (root == null) return root; // Ищем узел, который нужно удалить if (key < root.key) root.left = deleteRec(root.left, key); else if (key >root.key) root.right = deleteRec(root.right, key); else < // Если у узла только один дочерний элемент или их вообще нет if (root.left == null) return root.right; else if (root.right == null) return root.left; // Если у узла два дочерних элемента // Помещаем inorder-преемника на место узла, который хотим удалить root.key = minValue(root.right); // Удаляем inorder-преемника root.right = deleteRec(root.right, root.key); >return root; > // Ищем inorder-преемника int minValue(Node root) < int minv = root.key; while (root.left != null) < minv = root.left.key; root = root.left; >return minv; > // Тестим функции public static void main(String[] args) < BinarySearchTree tree = new BinarySearchTree(); tree.insert(8); tree.insert(3); tree.insert(1); tree.insert(6); tree.insert(7); tree.insert(10); tree.insert(14); tree.insert(4); System.out.print("Отсортированный обход: "); tree.inorder(); System.out.println("\n\nПосле удаления 10"); tree.deleteKey(10); System.out.print("Отсортированный обход: "); tree.inorder(); >>C
// Операции с двоичным деревом поиска на C #include #include struct node < int key; struct node *left, *right; >; // Создаем узел struct node *newNode(int item) < struct node *temp = (struct node *)malloc(sizeof(struct node)); temp->key = item; temp->left = temp->right = NULL; return temp; > // Отсортированный (inorder) обход void inorder(struct node *root) < if (root != NULL) < // Обходимо лево inorder(root->left); // Обходим корень printf("%d -> ", root->key); // Обходимо право inorder(root->right); > > // Вставка узла struct node *insert(struct node *node, int key) < // Возвращаем новый узел, если дерево пустое if (node == NULL) return newNode(key); // Проходим в нужное место и вставляем узел if (key < node->key) node->left = insert(node->left, key); else node->right = insert(node->right, key); return node; > // Поиск inorder-преемника struct node *minValueNode(struct node *node) < struct node *current = node; // Находим крайний левый лист — он и будет inorder-преемником while (current && current->left != NULL) current = current->left; return current; > // Удаляем узел struct node *deleteNode(struct node *root, int key) < // Возвращаем, если дерево пустое if (root == NULL) return root; // Ищем узел, который нужно удалить if (key < root->key) root->left = deleteNode(root->left, key); else if (key > root->key) root->right = deleteNode(root->right, key); else < // Если у узла только один дочерний элемент или их вообще нет if (root->left == NULL) < struct node *temp = root->right; free(root); return temp; > else if (root->right == NULL) < struct node *temp = root->left; free(root); return temp; > // Если у узла два дочерних элемента struct node *temp = minValueNode(root->right); // Помещаем inorder-преемника на место узла, который хотим удалить root->key = temp->key; // Удаляем inorder-преемника root->right = deleteNode(root->right, temp->key); > return root; > // Тестим функции int main() C++
// Операции с двоичным деревом поиска на C++ #include using namespace std; struct node < int key; struct node *left, *right; >; // Создаем узел struct node *newNode(int item) < struct node *temp = (struct node *)malloc(sizeof(struct node)); temp->key = item; temp->left = temp->right = NULL; return temp; > // Отсортированный (inorder) обход void inorder(struct node *root) < if (root != NULL) < // Обходим лево inorder(root->left); // Обходим корень cout key "; // Обходим право inorder(root->right); > > // Вставка узла struct node *insert(struct node *node, int key) < // Возвращаем новый узел, если дерево пустое if (node == NULL) return newNode(key); // Проходим в нужное место и вставляет узел if (key < node->key) node->left = insert(node->left, key); else node->right = insert(node->right, key); return node; > // Поис inorder-преемника struct node *minValueNode(struct node *node) < struct node *current = node; // Ищем крайний левый лист — он и будет inorder-преемником while (current && current->left != NULL) current = current->left; return current; > // Удаление узла struct node *deleteNode(struct node *root, int key) < // Возвращаем, если дерево пустое if (root == NULL) return root; // Ищем узел, который хотим удалить if (key < root->key) root->left = deleteNode(root->left, key); else if (key > root->key) root->right = deleteNode(root->right, key); else < // Если у узла один дочерний элемент или их нет if (root->left == NULL) < struct node *temp = root->right; free(root); return temp; > else if (root->right == NULL) < struct node *temp = root->left; free(root); return temp; > // Если у узла два дочерних элемента struct node *temp = minValueNode(root->right); // Помещаем inorder-преемника на место узла, который хотим удалить root->key = temp->key; // Удаляем inorder-преемника root->right = deleteNode(root->right, temp->key); > return root; > // Тестим функции int main()
Где используется
- При многоуровневой индексации в базе данных.
- Для динамической сортировки.
- Для управления областями виртуальной памяти в ядре Unix.
Источник