Двоичное дерево поиска
Двоичное дерево поиска. Итеративная реализация.
Д воичные деревья – это структуры данных, состоящие из узлов, которые хранят значение, а также ссылку на свою левую и правую ветвь. Каждая ветвь, в свою очередь, является деревом. Узел, который находится в самой вершине дерева принято называть корнем (root), узлы, находящиеся в самом низу дерева и не имеющие потомков называют листьями (leaves). Ветви узла называют потомками (descendants). По отношению к своим потомкам узел является родителем (parent) или предком (ancestor). Также, развивая аналогию, имеются сестринские узлы (siblings – родные братья или сёстры) – узлы с общим родителем. Аналогично, у узла могут быть дяди (uncle nodes) и дедушки и бабушки ( grandparent nodes). Такие названия помогают понимать различные алгоритмы.
Двоичное дерево. На этом рисунке узел 10 корень, 7 и 12 его наследники. 6, 9, 11, 14 — листья. 7 и 12, также как и 6 и 9 являются сестринскими узлами, 10 — это дедушка узла 6, а 12 — дядя узла 6 и узла 9
Двоичные деревья одна из самых простых структур (по сравнению, например, с другими деревьями). Они обычно реализуют самый базовый и самый естественный способ классификации элементов – делят их по определённому признаку, размещая одну группу в левом поддереве, а другую группу в правом. В поддеревьях рекурсивно поддерживается такой же порядок, за счёт чего узлы дерева упорядочиваются.
Двоичное дерево поиска (далее ДДП) – это несбалансированное двоичное дерево, в котором элементы БОЛЬШЕ корневого размещаются справа, а элементы, которые МЕНЬШЕ размещаются слева.
Такое размещение – слева меньше, справа больше – не обязательно, можно располагать элементы, которые меньше, справа. Отношение БОЛЬШЕ и МЕНЬШЕ – это не обязательно естественная сортировка по величине, это некоторая бинарная операция, которая позволяет разбить элементы на две группы.
Для реализации бинарного дерева поиска будем использовать структуру Node, которая содержит значение, ссылку на правое и левое поддерево, а также ссылку на родителя. Ссылка на родительский узел, в принципе, не является обязательной, однако сильно упрощает и ускоряет все алгоритмы. Далее, ради тренировки, мы ещё рассмотрим реализацию без ссылки на родителя.
ЗАМЕЧАНИЕ: мы рассматриваем случай, когда в дереве все значения разные и не равны NULL. Деревья с повторяющимися узлами рассмотрим позднее.
Обычно в качестве типа данных мы используем void* и далее передаём функции сравнения через указатели. В этот раз будем использовать пользовательский тип и макросы.
typedef int T; #define CMP_EQ(a, b) ((a) == (b)) #define CMP_LT(a, b) ((a) < (b)) #define CMP_GT(a, b) ((a) >(b)) typedef struct Node < T data; struct Node *left; struct Node *right; struct Node *parent; >Node;
Сначала, как обычно, напишем функцию, которая создаёт новый узел. Она принимает в качестве аргументов значение и указатель на своего родителя. Корневой элемент не имеет родителя, значение указателя parent равно NULL.
Node* getFreeNode(T value, Node *parent) < Node* tmp = (Node*) malloc(sizeof(Node)); tmp->left = tmp->right = NULL; tmp->data = value; tmp->parent = parent; return tmp; >
Разберёмся со вставкой. Возможны следующие ситуации
- 1) Дерево пустое. В этом случае новый узел становится корнем ДДП.
- 2) Новое значение меньше корневого. В этом случае значение должно быть вставлено слева. Если слева уже стоит элемент, то повторяем эту же операцию, только в качестве корневого узла рассматриваем левый узел. Если слева нет элемента, то добавляем новый узел.
- 3) Новое значение больше корневого. В этом случае новое значение должно быть вставлено справа. Если справа уже стоит элемент, то повторяем операцию, только в качестве корневого рассматриваем правый узел. Если справа узла нет, то вставляем новый узел.
Пусть нам необходимо поместить в ДДП следующие значения
Первое значение становится корнем.
Второе значение меньше десяти, так что оно помещается слева.
Число 9 меньше 10, так что узел должен располагаться слева, но слева уже стоит значение. 9 больше 7, так что новый узел становится правым потомком семи.
Число 12 помещается справа от 10.
Добавляем оставшиеся узлы 14, 3, 4, 11
Функция, добавляющая узел в дерево
Два узла. Первый – вспомогательная переменная, чтобы уменьшить писанину, второй – тот узел, который будем вставлять.
Node *tmp = NULL; Node *ins = NULL;
Проверяем, если дерево пустое, то вставляем корень
Проходим по дереву и ищем место для вставки
Пока не дошли до пустого узла
Если значение больше, чем значение текущего узла
Если при этом правый узел не пустой, то за корень теперь считаем правую ветвь и начинаем цикл сначала
if (tmp->right) < tmp = tmp->right; continue;
Если правой ветви нет, то вставляем узел справа
> else < tmp->right = getFreeNode(value, tmp); return; >
Также обрабатываем левую ветвь
> else if (CMP_LT(value, tmp->data)) < if (tmp->left) < tmp = tmp->left; continue; > else < tmp->left = getFreeNode(value, tmp); return; > > else < exit(2); >>
void insert(Node **head, int value) < Node *tmp = NULL; Node *ins = NULL; if (*head == NULL) < *head = getFreeNode(value, NULL); return; >tmp = *head; while (tmp) < if (CMP_GT(value, tmp->data)) < if (tmp->right) < tmp = tmp->right; continue; > else < tmp->right = getFreeNode(value, tmp); return; > > else if (CMP_LT(value, tmp->data)) < if (tmp->left) < tmp = tmp->left; continue; > else < tmp->left = getFreeNode(value, tmp); return; > > else < exit(2); >> >
Рассмотрим результат вставки узлов в дерево. Очевидно, что структура дерева будет зависеть от порядка вставки элементов. Иными словами, форма дерева зависит от порядка вставки элементов.
Если элементы не упорядочены и их значения распределены равномерно, то дерево будет достаточно сбалансированным, то есть путь от вершины до всех листьев будет одинаковый. В таком случае максимальное время доступа до листа равно log(n), где n – это число узлов, то есть равно высоте дерева.
Но это только в самом благоприятном случае. Если же элементы упорядочены, то дерево не будет сбалансировано и растянется в одну сторону, как список; тогда время доступа до последнего узла будет порядка n. Это слабая сторона ДДП, из-за чего применение этой структуры ограничено.
Дерево, которое получили вставкой чередующихся возрастающей и убывающей последовательностей (слева) и полученное при вставке упорядоченной последовательности (справа)
Для решения этой проблемы можно производить балансировку дерева, или использовать структуры, которые автоматически проводят самобалансировку во время вставки и удаления.
Поиск в дереве
И звестно, что слева от узла располагается элемент, который меньше чем текущий узел. Из чего следует, что если у узла нет левого наследника, то он является минимумом в дереве. Таким образом, можно найти минимальный элемент дерева
Node* getMinNode(Node *root) < while (root->left) < root = root->left; > return root; >
Аналогично, можно найти максимальный элемент
Node* getMaxNode(Node *root) < while (root->right) < root = root->right; > return root; >
Опять же, если дерево хорошо сбалансировано, то поиск минимума и максимума будет иметь сложность порядка log(n), а в случае плохой балансировки стремится к n.
Поиск нужного узла по значению похож на алгоритм бинарного поиска в отсортированном массиве. Если значения больше узла, то продолжаем поиск в правом поддереве, если меньше, то продолжаем в левом. Если узлов уже нет, то элемент не содержится в дереве.
Node *getNodeByValue(Node *root, T value) < while (root) < if (CMP_GT(root->data, value)) < root = root->left; continue; > else if (CMP_LT(root->data, value)) < root = root->right; continue; > else < return root; >> return NULL; >
Удаление узла
С уществует три возможных ситуации.
- 1) У узла нет наследников (удаляем лист). Тогда он просто удаляется, а его родитель обнуляет указатель на него.
Источник
Удаление из BST (бинарного дерева поиска)
Имея BST, напишите эффективную функцию для удаления заданного ключа в нем.
Существует три возможных случая удаления узла из BST:
Случай 1: Удаление узла без потомков: удалить узел из дерева.
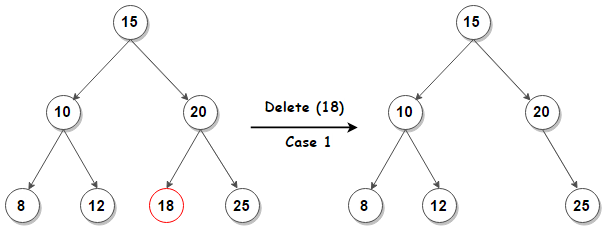
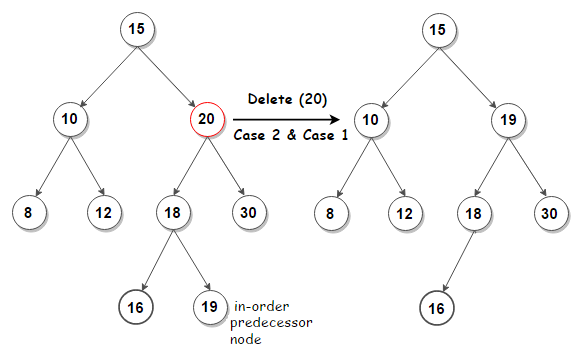
Случай 2: Удаление узла с двумя дочерними элементами: вызовите удаляемый узел N . Не удалять N . Вместо этого выберите либо его в целях преемник узел или его порядок предшественник узел, R . Скопируйте значение R к N , затем рекурсивно вызовите delete на R до достижения одного из первых двух случаев. Если мы выберем неупорядоченного преемника узла, поскольку правое поддерево не равно NULL (наш текущий случай — это узел с двумя дочерними элементами), то его неупорядоченный преемник — это узел с наименьшим значением в его правом поддереве, который будет иметь в максимум 1 поддерево, поэтому его удаление попадет в один из первых 2-х случаев.
Случай 3: Удаление узла с одним дочерним элементом: удалите узел и замените его своим дочерним элементом.
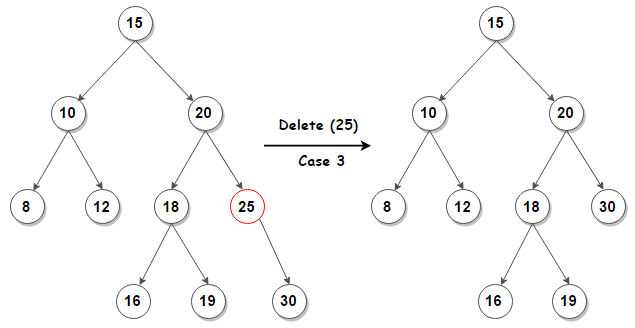
Вообще говоря, узлы с дочерними элементами удалить сложнее. Как и во всех бинарных деревьях, неупорядоченный преемник узла является самым левым дочерним элементом его правого поддерева, а неупорядоченный предшественник узла является самым правым дочерним элементом левого поддерева. В любом случае у этого узла будет ноль или один дочерний элемент. Удалите его в соответствии с одним из двух более простых случаев выше.
Алгоритм может быть реализован следующим образом на C++, Java и Python:
Источник