- Обход дерева предварительного заказа — итеративный и рекурсивный
- Рекурсивная реализация
- 3.7.2. Рекурсивные функции обхода бинарных деревьев
- 3.7.3. Нерекурсивные функции обхода бинарных деревьев
- Двоичное дерево поиска — рекурсивная реализация
- Замена циклов на рекурсию
- Рекурсивные операции с пересборкой дерева
Обход дерева предварительного заказа — итеративный и рекурсивный
Имея двоичное дерево, напишите итеративное и рекурсивное решение для обхода дерева с использованием обхода в прямом порядке в C++, Java и Python.
В отличие от связанных списков, одномерных массивов и других линейных структур данных, обход которых осуществляется в линейном порядке, по деревьям можно перемещаться несколькими способами. глубина первого порядка (предварительный заказ, в целях, а также постзаказ) или же ширина первого порядка (обход порядка уровней). Помимо этих основных обходов, возможны различные более сложные или гибридные схемы, такие как поиск с ограничением по глубине, например итеративный поиск в глубину с углублением. В этом посте подробно обсуждается обход дерева предварительного заказа.
Обход дерева включает в себя итерацию по всем узлам тем или иным образом. Поскольку дерево не является линейной структурой данных, может быть более одного возможного следующего узла от данного узла, поэтому некоторые узлы должны быть отложены, т. е. каким-то образом сохранены для последующего посещения. Обход может выполняться итеративно, когда отложенные узлы хранятся в stack, или это можно сделать с помощью рекурсия, где отложенные узлы неявно хранятся в стек вызовов.
Для обхода (непустого) бинарного дерева в предварительном порядке мы должны сделать эти три вещи для каждого узла. n начиная с корня дерева:
(N) Процесс n сам.
(L) Рекурсивно обходим его левое поддерево. Когда этот шаг будет завершен, мы вернемся к n опять таки.
(R) Рекурсивно обходим его правое поддерево. Когда этот шаг будет завершен, мы вернемся к n опять таки.
В обычном обходе в предварительном порядке посетите левое поддерево перед правым поддеревом. Если мы посещаем правое поддерево перед посещением левого поддерева, это называется обходом в обратном порядке.
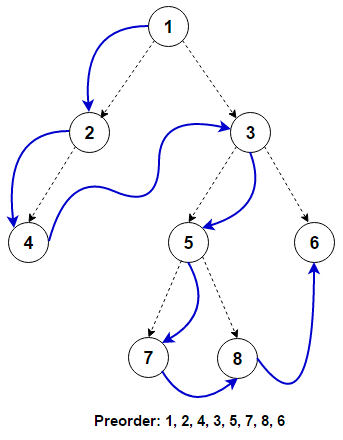
Рекурсивная реализация
Как мы видим, только после обработки любого узла обрабатывается левое поддерево, а за ним правое поддерево. Эти операции могут быть определены рекурсивно для каждого узла. Рекурсивная реализация называется Поиск в глубину (DFS), так как дерево поиска максимально углубляется для каждого дочернего элемента, прежде чем перейти к следующему родственному элементу.
Ниже приведена программа на C++, Java и Python, которая демонстрирует это:
Источник
3.7.2. Рекурсивные функции обхода бинарных деревьев
Первые три порядка обхода, которые приводятся в таблице 3.5, легко реализуются рекурсиным вызовом функции обхода для левого и правого поддеревьев в том порядке, которого требует алгоритм. Требуется только пояснить шаг «посетить корень». Поскольку обходы деревьев могут потребоваться для любой обработки значений, находящихся в узлах, то будем считать, что этот шаг обозначает именно ту обработку, которая нужна для конкретной задачи.
Функции имеют очень компактный код, который приведен в листинге 3.4, а для простоты предполагается, что вся обработка состоит только в выводе на экран значения, которое хранится в узле. Для того, чтобы сделать данные функции универсальными, можно добавить еще один параметр— внешнюю функцию Visit, в которой будет сосредоточена вся обработка узла.
Листинг 3.4. Реализация рекурсивных обходов бинарного дерева
// Дополнение к файлу bintree.cpp
void forward(bt t)//прямой порядок обхода
void reverse(bt t)// обратный порядок обхода
void central(bt t)// центрированный порядок обхода
Заметим, что обход в ширину не имеет простой рекурсивной реализации. Ниже мы приведем алгоритм обхода в ширину с использованием вспомогательной структуры данных — очереди.
3.7.3. Нерекурсивные функции обхода бинарных деревьев
Учитывая важность эффективной реализации обходов бинарных деревьев, рассмотрим нерекурсивный способ обходов, использующий цикл обхода по дереву. Вспомним, что рекурсивные функции используют внутренний (системный) стек программы, в который при каждом рекурсивном вызове помещается параметр (в данном случае указатель на узел) и адрес возврата. Следовательно, для реализации нерекурсивных алгоритмов логично использовать вспомогательный (внешний) стек, которая будет использоваться для тех же целей, что и системный стек программы в рекурсивных способах.
Введем вспомогательный стек s. При использовании языков высокого уровня мы не сможем в точности воспроизвести в нем содержимое системного стека, да это и не нужно. В литературе [8,10,14] приводятся различные алгоритмы нерекурсивного обхода, в которых вспомогательный стек используется только для хранения указателей на узлы дерева. Различные способы обхода различаются порядком, в котором эти указатели заталкиваются в стек и извлекаются из него.
Предположим, что уже имеется реализация шаблона стека с типом данных bt — указатель на узел бинарного дерева (для этого можно воспользоваться реализацией типа stack, которая была рассмотрена в предыдущей главе). Напомним базовые функции (методы) структуры stack:
push(p) – заталкиваем p в стек
pop() – извлекаем элемент с вершины стека
isnull() – проверяем стек на пустоту.
Наиболее прост в реализации алгоритм прямого обхода, который приводится в [14]. Напомним, что любая функция обхода получает в качестве параметра корень дерева. Поместим его в стек. Затем на каждом шаге итерации сначала извлекаем элемент с верхушки стека. При прямом обходе корень обрабатывается первым, после чего указатель на корень уже не нужен, а в стек помещается сначала указатель на правое поддерево, а затем на левое (пустые указатели в стек не помещаются). На следующем шаге итерации из стека извлекается и обрабатывается именно корень левого поддерева (он на вершине), после чего в стек заталкиваются указатели на его правое и левое поддеревья. Цикл повторяется до тех пор, пока стек не опустеет (это произойдет после извлечения крайнего правого листа). В листинге 3.5. приведена функция прямого обхода.
Листинг 3.5. Нерекурсивная реализация прямого обхода
void forwardstack(bt t) // нерекурсивный обход в прямом порядке
< stacks; // структура stack должна быть реализована!
Проанализируем выполнение данной функции, поскольку алгоритм достаточно универсален и его можно приспособить и для некоторых других видов обхода. Пусть функция применяется к дереву из семи узлов, которое изображено на рис.3.9. Тогда будет выполнено семь шагов цикла (итераций), а последовательность извлекаемых элементов и содержимое стека в начале каждого шага представлены в табл. 3.6. На каждом шаге итерации в стек добавляются поддеревья очередного узла (1,2 или 0 в зависимости от их количества) и извлекается ровно один узел с вершины.
Содержимое стека при прямом порядке обхода
Источник
Двоичное дерево поиска — рекурсивная реализация
Теги: Двоичное дерево поиска. БДП. Рекурсивные алгоритмы работы с двоичным деревом поиска. Узел без ссылки на родителя.
Д ля двоичного дерева, как и для списка, можно дать простое рекурсивное определение. Двоичное дерево либо пусто, либо состоит из узла, каждая ветвь которого является деревом. Под пустым деревом будем понимать NULL. Соответственно, его наследников либо нет (тогда указатель равен NULL), либо наследники являются узлами, у каждого из которых есть свои наследники. В двоичном дереве поиска элемент меньше корня находятся слева, а больше — справа. Этот порядок сохраняется и далее, так что каждый из наследников корневого узла также является двоичным деревом поиска. Соответственно, если мы применяем какой-то алгоритм к дереву, он же может быть применён и к поддереву, так как оно продолжает обладать всеми теми же свойствами.
Реализовать операции поиска, вставки и удаления рекурсивно можно двумя способами. Первый, самый простой, заменить все циклы на рекурсивный вызов. Таким образом, все операции, где текущий узел подменяется на своего правого или левого потомка, заменяется на вызов функции с соответствующим аргументом.
Второй подход несколько иной. Вместо вставки и удаления будем производить ПЕРЕСБОРКУ дерева. Так как новых узлов при этом не будет создаваться, то утечки памяти происходить не будет.
Замена циклов на рекурсию
В ставка нового узла будет завершаться в том случае, если текущий узел равен NULL, то есть искать место для узла дальше некуда. Проблемой будет являться то, что обратиться к родительскому узлу в таком случае будет уже невозможно. Поэтому будем передавать родительский узел, к которому нужно добавить новый, как параметр функции.
void insertRec(Node **root, Node* parent, T value) < Node *tmp = NULL; //Если это корень, то у него нет родителя if (*root == NULL) < *root = getNode(value, parent); return; >tmp = (*root); if (CMP_GT(value, tmp->data)) < insertRec(&(tmp->right), tmp, value); > else if (CMP_LT(value, tmp->data)) < insertRec(&(tmp->left), tmp, value); > else < exit(2); >>
Поиск узла выгладит следующим образом: если текущий узел меньше, то вызываем функцию поиска, передавая в качестве аргумента правое поддерево, если больше, то левое.
Node* getByValueRec(Node* root, T value) < if (!root) < return NULL; >if (CMP_GT(root->data, value)) < getByValueRec(root->left, value); > else if (CMP_LT(root->data, value)) < getByValueRec(root->right, value); > else < return root; >>
Поиск минимального и максимального элемента также тривиальны
Node* findMaxNodeRec(Node *root) < if (root == NULL) < exit(4); >if (root->right) < return findMaxNodeRec(root->right); > return root; > Node* findMinNodeRec(Node* root) < if (root == NULL) < exit(3); >if (root->left) < return findMinNodeRec(root->left); > return root; >
Удаление элемента выглядит похоже на итеративное удаление. Здесь также будем передавать указатель на родителя в качестве одного из аргументов.
void removeNodeRec(Node *target, T value, Node *parent) < if (target == NULL) < return; >if (CMP_GT(target->data, value)) < removeNodeRec(target->left, value, target); > else if (CMP_LT(target->data, value)) < removeNodeRec(target->right, value, target); > else < if (target->left && target->right) < >else if (target->left) < Node* localMax = findMaxNodeRec(target->left); target->data = localMax->data; removeNodeRec(target->left, localMax->data, target); > else if (target->right) < if (target->left == parent) < parent->left = target->right; > else < parent->right = target->right; > free(target); > else < if (parent->left == target) < parent->left = NULL; > else < parent->right = NULL; > free(target); > > >
Заметьте: теперь нам вообще не нужен указатель на родительский элемент! Каждый раз мы храним указатель на родителя в предыдущем вызове, передавая его в качестве аргумента в следующий, поэтому в определении узла можно отказаться от использования parent. Заодно нужно переписать функцию getNode, чтобы она не получала указатель на родителя.
Вообще, можно было сделать это и в итеративной реализации. То есть отказ от указателя на родителя не связан с использованием рекурсивного подхода.
Рекурсивные операции с пересборкой дерева
П ри рекурсивной пересборке дерева мы не нуждаемся в указателе на родителя. Родитель «при нас», это текущий элемент, так что мы можем контролировать дельнейшие действия.
Определение узла и функции, которая возвращает новый узел.
typedef int T; #define CMP_EQ(a, b) ((a) == (b)) #define CMP_LT(a, b) ((a) < (b)) #define CMP_GT(a, b) ((a) >(b)) typedef struct Node < T data; struct Node *left; struct Node *right; >Node; Node *getNode(T value) < Node* tmp = (Node*) malloc(sizeof(Node)); tmp->left = tmp->right = NULL; tmp->data = value; return tmp; >
Функция вставки нового элемента возвращает новое дерево. Это дерево построено из старого, в которое добавлен новый узел. Причём процесс пересборки в тоже время производит поиск места, в которое нужно произвести вставку.
Если функция получает NULL в качестве аргумента, то она возвращает новый узел. Если узел больше значения, которое мы хотим вставить, то левой ветви присваиваем значение, которое возвращает наша же функция insert, то есть она «дособирает» левую ветвь. Аналогично, если значение узла меньше, то мы «дособираем» правую ветвь и возвращаем узел.
Node* insert(Node* root, T value) < if (root == NULL) < return getNode(value); >if (CMP_GT(root->data, value)) < root->left = insert(root->left, value); return root; > else if (CMP_LT(root->data, value)) < root->right = insert(root->right, value); return root; > else < exit(3); >>
Удаление элемента состоит из пересборки дерева, во время которого мы пропускаем добавление удаляемого узла. При этом сам процесс является ещё и нахождением нужного нам узла (того, который мы хотим удалить).
Когда мы доходим до конца дерева, то логично закончить работу и вернуть NULL.
Теперь проверяем, если текущий узел не равен удаляемому значению, то продолжаем сборку левой и правой ветвей.
if (CMP_GT(root->data, value)) < root->left = deleteNode(root->left, value); return root; > else if (CMP_LT(root->data, value)) < root->right = deleteNode(root->right, value); return root; > else < //Магия здесь >>
Если же мы наткнулись на узел, который хотим удалить, то есть несколько ситуаций.
if (root->left && root->right) < //Заменить значение текущего узла на максимум левой подветви //Удалить максимум левой подветви //Вернуть собранное значение >else if (root->left) < //Удалить узел и вернуть его левую подветвь >else if (root->right) < //Удалить узел и вернуть его правую подветвь >else < //Удалить узел и вернуть NULL >
Node* deleteNode(Node* root, T value) < if (root == NULL) < return NULL; >if (CMP_GT(root->data, value)) < root->left = deleteNode(root->left, value); return root; > else if (CMP_LT(root->data, value)) < root->right = deleteNode(root->right, value); return root; > else < if (root->left && root->right) < Node* locMax = findMaxNode(root->left); root->data = locMax->data; root->left = deleteNode(root->left, locMax->data); return root; > else if (root->left) < Node *tmp = root->left; free(root); return tmp; > else if (root->right) < Node *tmp = root->right; free(root); return tmp; > else < free(root); return NULL; >> >
Функции нахождения узла, максимум и минимума не изменятся.

Всё ещё не понятно? – пиши вопросы на ящик
Источник