Дерево отрезков. Построение
Дерево отрезков (англ. Segment tree) — это структура данных, которая позволяет за асимптотику [math]O(\log n)[/math] реализовать любые операции, определяемые на множестве, на котором данная операция ассоциативна, и существует нейтральный элемент относительно этой операции, то есть на моноиде. Например, суммирование на множестве натуральных чисел, поиск минимума на любом числовом множестве, перемножение матриц на множестве матриц размера [math]N*N[/math] , объединение множеств, поиск наибольшего общего делителя на множестве целых чисел и многочленов.
При этом дополнительно возможно изменение элементов массива: как изменение значения одного элемента, так и изменение элементов на целом подотрезке массива, например разрешается присвоить всем элементам [math]a[l \ldots r][/math] какое-либо значение, либо прибавить ко всем элементам массива какое-либо число. Структура занимает [math]O(n)[/math] памяти, а ее построение требует [math]O(n)[/math] времени.
Структура
Структура представляет собой дерево, листьями которого являются элементы исходного массива. Другие вершины этого дерева имеют по [math]2[/math] ребенка и содержат результат операции от своих детей (например минимум или сумму). Таким образом, корень содержит результат искомой функции от всего массива [math][0\ldots n-1][/math] , левый ребёнок корня содержит результат функции на [math][0\ldots\dfrac][/math] , а правый, соответственно результат на [math][\dfrac+1\ldots n-1][/math] . И так далее, продвигаясь вглубь дерева.
Построение дерева
Пусть исходный массив [math]a[/math] состоит из [math]n[/math] элементов. Для удобства построения увеличим длину массива [math]a[/math] так, чтобы она равнялась ближайшей степени двойки, т.е. [math]2^k[/math] , где [math]2^k \geqslant n[/math] . Это сделано, для того чтобы не допустить обращение к несуществующим элементам массива при дальнейшем процессе построения. Пустые элементы необходимо заполнить нейтральными элементами моноида. Тогда для хранения дерева отрезков понадобится массив [math]t[/math] из [math]2^[/math] элементов, поскольку в худшем случае количество вершин в дереве можно оценить суммой [math]n+\dfrac+\dfrac \ldots +1 \lt 2n[/math] , где [math]n=2^k[/math] . Таким образом, структура занимает линейную память.
Выделяют два основных способа построения дерева отрезков: построение снизу и построение сверху. При построении снизу алгоритм поднимается от листьев к корню (Просто начинаем заполнять элементы массива [math]t[/math] от большего индекса к меньшему, таким образом при заполнении элемента [math] i [/math] его дети [math]2i+1[/math] и [math]2i+2[/math] уже будут заполнены, и мы с легкостью посчитаем бинарную операцию от них), а при построении сверху спускается от корня к листьям. Особенные изменения появляются в реализации запросов к таким деревьям отрезков.
Реализация построения сверху:
function treeBuild(T a[], int i, int tl, int tr): // мы находимся в вершине с номером i, который отвечает за полуинтервал [tl, tr) if tr - tl == 1 t[i] = a[tl] else tm = (tl + tr) / 2 // середина отрезка treeBuild(a, 2 * i + 1, tl, tm) treeBuild(a, 2 * i + 2, tm, tr) t[i] = t[2 * i + 1] t[2 * i + 2] Реализация построения снизу:
function treeBuild(T a[]): for i = 0 to n - 1 t[n - 1 + i] = a[i] for i = n - 2 downto 0 t[i] = t[2 * i + 1] t[2 * i + 2] См. также
Источники информации
Источник
Дерево отрезков
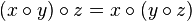
Я расскажу о структуре под названием дерево отрезков и приведу его простую реализацию на языке С++. Эта структура весьма полезна в случаях, когда необходимо часто искать значение какой-то функции на отрезках линейного массива и иметь возможность быстро изменять значения группы подряд идущих элементов.
Типичный пример задачи на дерево отрезков:
Есть линейный массив, изначально заполненный некоторыми данными. Далее приходят 2 типа запросов:
1й тип — найти значение максимального элемента на отрезке массива [a..b].
2й тип — заменить iй элемент массива на x.
Возможен запрос «добавить х ко всем элементам на отрезке [a..b]», но в данной статье я его не рассматриваю.
С помощью дерева отрезков можно искать не только максимум чисел, но и любую функцию, удовлетворяющую свойству ассоциативности.
Это ограничение связано с тем, что используется предпросчет значений для некоторых отрезков.
Так же можно искать, например, не значения, а порядковые номера элементов.
Желательно, что бы функция имела «нейтральный» аргумент, который не оказывает влияния на результат. Например, для суммы это число 0: (a + 0 = a), а для максимума это бесконечность: max(a, -inf) = a.
Итак, поехали.
Самый простой (и медленный) способ решать представленную выше задачу, это завести линейный массив, и покорно делать то, что от нас хотят.
при такой реализации время нахождения ответа на запрос имеет порядок О(n). в среднем, придется пройтись по половине массива что бы найти максимум. Хотя есть и положительные моменты — изменение значения какого-либо элемента требует O(1) времени. Этот алгоритм можно ускорить в 2 раза, если выполнить небольшой предпросчет: для каждой пары элементов найдем значение максимального из них, и запишем в другой массив. Тогда при поиске максимума на отрезке, для каждой пары элементов уже известно значение большего, и сравнивать придется только с ним. остается только аккуратно проверить граничные элементы, так как граница запрашиваемого отрезка не обязательно четная.
На рисунке выделены элементы, которые необходимо проверять.

Понятно, что над этими массивами можно ввести еще один, что бы поиск был еще в 2 раза быстрее, а над ним еще один… и так до тех пор, пока самый верхний массив не будет состоять из одного элемента. Как не трудно догадаться, значение единственного элемента в самом верхнем массиве – это значение максимального элемента.

Некоторые пояснения: число рядом с вершиной дерева — это положение этой вершины в реальном массиве. При такой реализации хранения дерева очень удобно искать предка и потомков вершины: предок вершины i имеет номер i/2, а потомки номера i*2 и i*2+1. Из рисунка видно, что необходимо, что бы длинна массива была степенью двойки. Если это не так, то массив можно в конце дополнить нейтральными элементами. Расход памяти на хранение структуры от 2n до 4n, (n — количество элементов).
Алгоритм поиска «сверху» (есть еще и «снизу») весьма прост и в понимании и в реализации (хотя тех, кто не знаком с рекурсией, это всё может озадачить).
Алгоритм таков:
Начинаем опрос с вершины 1 (самая верхняя).
1.пусть текущая вершина знает максимум на промежутке l..r.
«пересекаются области [a..b] и [l..r] ?»
возможные варианты:
a. вообще не пересекаются.
что бы не влиять на результат вычисления, вернем нейтральный элемент (-бесконечность).
b. область [l..r] полностью лежит внутри [a..b].
вернуть предпросчитанное значение в текущей вершине.
с. другой вариант перекрытия областей.
спросить то же самое у детей текущей вершины и вычислить максимум среди них (смотрите код, если непонятно).
Как видно, алгоритм короткий, но рекурсивный. Временная сложность O(logN), что намного луче, чем О(N). например, при массиве длинной 10^9 элементов, необходимо примерно 32 сравнения.
Изменить число в этой структуре еще проще — надо пройти по всем вершинам от заданной до 1й, и если значение в текущей меньше чем новое, то заменить его. Это так же занимает O(log N) времени.
Реализация алгоритма.
Предполагается, что количество элементов массива не более 1024 (номера 0..1023).
- #include
- #include
- using namespace std ;
- #define INF 1000000000 // предпологаем, что чисел больше такого не будет.
- #define TREE_REAL_DATA 1024 // максимальное допустимое количество элементов
- int tree_data [ TREE_REAL_DATA * 2 ] ;
- // основная функция поиска.
- // аргументы: p — текушая вершина(пронумерованы согласно рисунку).
- // l, p — левая и правая границы отрезка, для которого tree_data[p] является максимумом.
- // вообще можно было обойтись без этих параметров, и определять их исходя из p, но так проще и понятней.
- // a, b — левая и правая границы отрезка, для которого необходимо найти минимум.
- int __tree_find_max ( int p, int l, int r, int a, int b )
- if ( b < l || r < a ) return - INF ;
- if ( a
- int r1 = __tree_find_max ( p * 2 , l, ( l + r ) / 2 , a, b ) ; // опрос левого предка
- int r2 = __tree_find_max ( p * 2 + 1 , ( l + r ) / 2 + 1 , r, a, b ) ; // опрос правого предка
- return max ( r1, r2 ) ; // нахождение большего из левого и правого поддеревьев
- >
- // более юзабильная оболочка для функции выше.
- int tree_find_max ( int a, int b )
- return __tree_find_max ( 1 , 0 , TREE_REAL_DATA — 1 , a, b ) ;
- >
- // обновление элемента № р.
- void tree_update ( int p, int x )
- p + = TREE_REAL_DATA ; // преобразование позиции p к позиции в самом нижнем массве,
- // в котором реально находится массив со значениями.
- tree_data [ p ] = x ;
- for ( p / = 2 ; p ; p / = 2 )
- if ( tree_data [ p * 2 ] > tree_data [ p * 2 + 1 ] )
- tree_data [ p ] = tree_data [ p * 2 ] ;
- else tree_data [ p ] = tree_data [ p * 2 + 1 ] ;
- >
- >
- // простейшая инициализация — установка всех значений в -INF
- void tree_init ( )
- for ( int i = 0 ; i < TREE_REAL_DATA * 2 ; i ++ )
- tree_data [ i ] = — INF ;
- >
- int main ( )
- tree_init ( ) ;
- while ( 1 )
- char c ;
- scanf ( «%c» , & c ) ;
- if ( c == ‘Q’ ) return 0 ; // выход
- if ( c == ‘F’ ) < // найти максимум на интервале a..b
- int a, b ;
- scanf ( «%d%d» , & a, & b ) ;
- printf ( «%d \n » , tree_find_max ( a, b ) ) ;
- >
- if ( c == ‘U’ ) < // установить значение элемента p равым x.
- int p, x ;
- scanf ( «%d%d» , & p, & x ) ;
- tree_update ( p, x ) ;
- >
- >
- >
Вот, в общем, и все, что необходимо в первую очередь знать о дереве отрезков.
Для разнообразия можно еще разобраться с алгоритмом вычисления «снизу» (он, кстати, нерекурсивный), хотя я нахожу его менее симпатичным. Ну и, конечно же, стоит разобраться с быстрым добавлением суммы ко всем элементам на отрезке (тоже за O(log N)), но это будет слишком утомительно для человека, который впервые разбирается с деревом отрезков.
Источник