- Дерево решений против случайных лесов: в чем разница?
- Плюсы и минусы: деревья решений против случайных лесов
- Когда использовать деревья решений против случайных лесов
- Дополнительные ресурсы
- Алгоритм классификации Random Forest на Python
- Алгоритм Random Forest
- Как работает случайный лес?
- Поиск важных признаков
- Сравнение случайных лесов и деревьев решений
- Создание классификатора с использованием Scikit-learn
Дерево решений против случайных лесов: в чем разница?
Дерево решений — это тип модели машинного обучения, который используется, когда связь между набором переменных-предикторов и переменной отклика нелинейна.
Основная идея дерева решений состоит в том, чтобы построить «дерево» с использованием набора переменных-предикторов, которые предсказывают значение некоторой переменной ответа с использованием правил принятия решений.
Например, мы можем использовать предикторные переменные «количество лет игры» и «среднее количество хоум-ранов», чтобы предсказать годовую зарплату профессиональных бейсболистов.
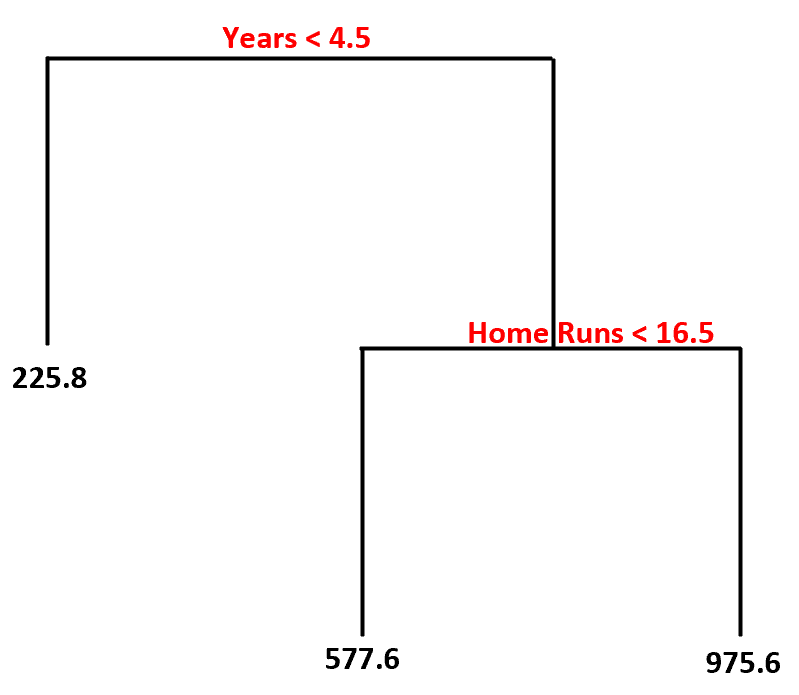
Используя этот набор данных, вот как может выглядеть модель дерева решений:

Вот как мы интерпретируем это дерево решений:
- Прогнозируемая зарплата игроков, игравших менее 4,5 лет, составляет 225,8 тысяч долларов .
- Прогнозируемая зарплата игроков со стажем игры более или равным 4,5 года и средним показателем хоумранов менее 16,5 имеет прогнозируемую зарплату в размере 577,6 тыс.долларов.
- Прогнозируемая зарплата игроков со стажем игры не менее 4,5 лет и средним показателем хоумранов не менее 16,5 имеет прогнозируемую зарплату в размере 975,6 тыс.долларов.
Основное преимущество дерева решений заключается в том, что его можно быстро подогнать к набору данных, а окончательную модель можно аккуратно визуализировать и интерпретировать с помощью «древовидной» диаграммы, подобной приведенной выше.
Основным недостатком является то, что дерево решений склонно к переоснащению обучающего набора данных, а это означает, что оно может плохо работать с невидимыми данными. На него также могут сильно влиять выбросы в наборе данных.
Расширением дерева решений является модель, известная как случайный лес , которая по сути представляет собой набор деревьев решений.
Вот шаги, которые мы используем для построения модели случайного леса:
1. Возьмите загрузочные образцы из исходного набора данных.
2. Для каждой выборки с начальной загрузкой постройте дерево решений, используя случайное подмножество переменных-предикторов.
3. Усредните прогнозы каждого дерева, чтобы получить окончательную модель.
Преимущество случайных лесов заключается в том, что они, как правило, работают намного лучше, чем деревья решений, на невидимых данных и менее подвержены выбросам.
Недостатком случайных лесов является то, что нет возможности визуализировать окончательную модель, и их создание может занять много времени, если у вас недостаточно вычислительной мощности или если набор данных, с которым вы работаете, чрезвычайно велик.
Плюсы и минусы: деревья решений против случайных лесов
В следующей таблице приведены плюсы и минусы деревьев решений по сравнению со случайными лесами:
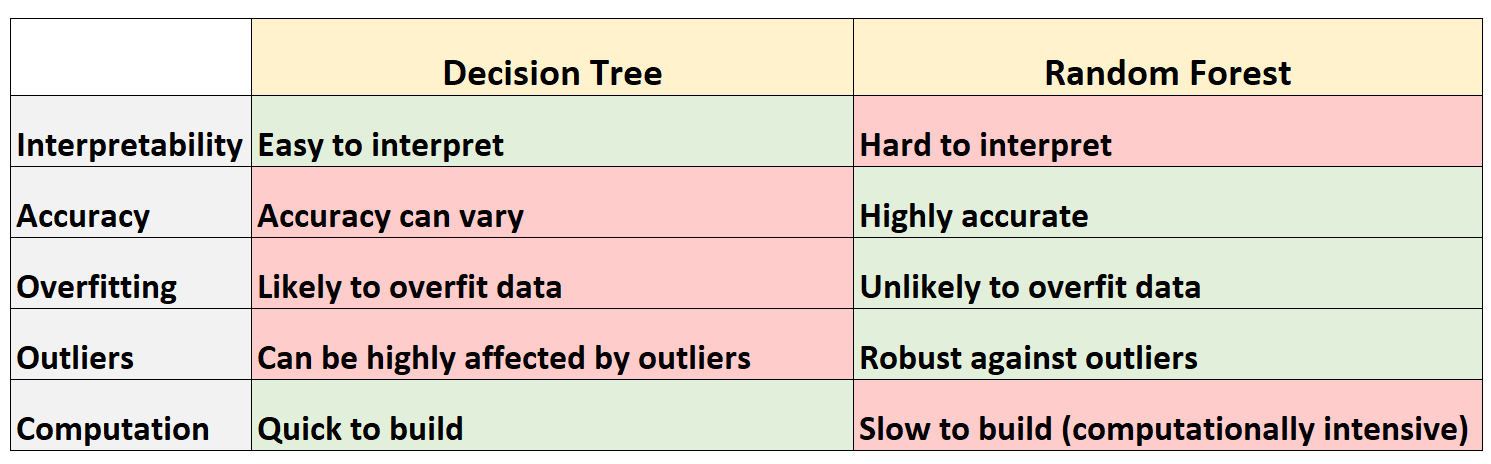
Вот краткое объяснение каждой строки в таблице:
1. Интерпретируемость
Деревья решений легко интерпретировать, потому что мы можем создать древовидную диаграмму, чтобы визуализировать и понять окончательную модель.
И наоборот, мы не можем визуализировать случайный лес, и часто бывает трудно понять, как окончательная модель случайного леса принимает решения.
Поскольку деревья решений, скорее всего, будут соответствовать обучающему набору данных, они, как правило, работают хуже, чем на невидимых наборах данных.
И наоборот, случайные леса, как правило, очень точны для невидимых наборов данных, поскольку они избегают переобучения обучающих наборов данных.
3. Переобучение
Как упоминалось ранее, деревья решений часто превосходят обучающие данные — это означает, что они, скорее всего, соответствуют «шуму» в наборе данных, а не истинному базовому шаблону.
И наоборот, поскольку случайные леса используют только некоторые переменные-предикторы для построения каждого отдельного дерева решений, окончательные деревья, как правило, декоррелированы, что означает, что модели случайного леса вряд ли будут соответствовать наборам данных.
Деревья решений очень подвержены влиянию выбросов.
И наоборот, поскольку модель случайного леса строит множество отдельных деревьев решений, а затем берет среднее значение предсказаний этих деревьев, гораздо меньше вероятность того, что на нее повлияют выбросы.
Деревья решений можно быстро адаптировать к наборам данных.
И наоборот, случайные леса требуют гораздо больше вычислительных ресурсов, и их создание может занять много времени в зависимости от размера набора данных.
Когда использовать деревья решений против случайных лесов
Как правило большого пальца:
Вам следует использовать дерево решений, если вы хотите быстро построить нелинейную модель и хотите иметь возможность легко интерпретировать, как модель принимает решения.
Тем не менее, вам следует использовать случайный лес , если у вас достаточно вычислительных способностей и вы хотите построить модель, которая, вероятно, будет очень точной, не беспокоясь о том, как ее интерпретировать.
В реальном мире инженеры по машинному обучению и специалисты по данным часто используют случайные леса, потому что они очень точны, а современные компьютеры и системы часто могут обрабатывать большие наборы данных, которые раньше не могли обрабатываться.
Дополнительные ресурсы
Следующие руководства содержат введение как в деревья решений, так и в модели случайного леса:
В следующих руководствах объясняется, как подогнать деревья решений и случайные леса в R:
Источник
Алгоритм классификации Random Forest на Python
Случайный лес (Random forest, RF) — это алгоритм обучения с учителем. Его можно применять как для классификации, так и для регрессии. Также это наиболее гибкий и простой в использовании алгоритм. Лес состоит из деревьев. Говорят, что чем больше деревьев в лесу, тем он крепче. RF создает деревья решений для случайно выбранных семплов данных, получает прогноз от каждого дерева и выбирает наилучшее решение посредством голосования. Он также предоставляет довольно эффективный критерий важности показателей (признаков).
Случайный лес имеет множество применений, таких как механизмы рекомендаций, классификация изображений и отбор признаков. Его можно использовать для классификации добросовестных соискателей кредита, выявления мошенничества и прогнозирования заболеваний. Он лежит в основе алгоритма Борута, который определяет наиболее значимые показатели датасета.
Алгоритм Random Forest
Давайте разберемся в алгоритме случайного леса, используя нетехническую аналогию. Предположим, вы решили отправиться в путешествие и хотите попасть в туда, где вам точно понравится.
Итак, что вы делаете, чтобы выбрать подходящее место? Ищите информацию в Интернете: вы можете прочитать множество различных отзывов и мнений в блогах о путешествиях, на сайтах, подобных Кью, туристических порталах, — или же просто спросить своих друзей.
Предположим, вы решили узнать у своих знакомых об их опыте путешествий. Вы, вероятно, получите рекомендации от каждого друга и составите из них список возможных локаций. Затем вы попросите своих знакомых проголосовать, то есть выбрать лучший вариант для поездки из составленного вами перечня. Место, набравшее наибольшее количество голосов, станет вашим окончательным выбором для путешествия.
Вышеупомянутый процесс принятия решения состоит из двух частей.
- Первая заключается в опросе друзей об их индивидуальном опыте и получении рекомендации на основе тех мест, которые посетил конкретный друг. В этой части используется алгоритм дерева решений. Каждый участник выбирает только один вариант среди знакомых ему локаций.
- Второй частью является процедура голосования для определения лучшего места, проведенная после сбора всех рекомендаций. Голосование означает выбор наиболее оптимального места из предоставленных на основе опыта ваших друзей. Весь этот процесс (первая и вторая части) от сбора рекомендаций до голосования за наиболее подходящий вариант представляет собой алгоритм случайного леса.
Технически Random forest — это метод (основанный на подходе «разделяй и властвуй»), использующий ансамбль деревьев решений, созданных на случайно разделенном датасете. Набор таких деревьев-классификаторов образует лес. Каждое отдельное дерево решений генерируется с использованием метрик отбора показателей, таких как критерий прироста информации, отношение прироста и индекс Джини для каждого признака.
Любое такое дерево создается на основе независимой случайной выборки. В задаче классификации каждое дерево голосует, и в качестве окончательного результата выбирается самый популярный класс. В случае регрессии конечным результатом считается среднее значение всех выходных данных ансамбля. Метод случайного леса является более простым и эффективным по сравнению с другими алгоритмами нелинейной классификации.
Как работает случайный лес?
Алгоритм состоит из четырех этапов:
- Создайте случайные выборки из заданного набора данных.
- Для каждой выборки постройте дерево решений и получите результат предсказания, используя данное дерево.
- Проведите голосование за каждый полученный прогноз.
- Выберите предсказание с наибольшим количеством голосов в качестве окончательного результата.
Поиск важных признаков
Random forest также предлагает хороший критерий отбора признаков. Scikit-learn предоставляет дополнительную переменную при использовании модели случайного леса, которая показывает относительную важность, то есть вклад каждого показателя в прогноз. Библиотека автоматически вычисляет оценку релевантности каждого признака на этапе обучения. Затем полученное значение нормализируется так, чтобы сумма всех оценок равнялась 1.
Такая оценка поможет выбрать наиболее значимые показатели и отбросить наименее важные для построения модели.
Случайный лес использует критерий Джини, также известный как среднее уменьшение неопределенности (MDI), для расчета важности каждого признака. Кроме того, критерий Джини иногда называют общим уменьшением неопределенности в узлах. Он показывает, насколько снижается точность модели, когда вы отбрасываете переменную. Чем больше уменьшение, тем значительнее отброшенный признак. Таким образом, среднее уменьшение является необходимым параметром для выбора переменной. Также с помощью данного критерия можете быть отображена общая описательная способность признаков.
Сравнение случайных лесов и деревьев решений
- Случайный лес — это набор из множества деревьев решений.
- Глубокие деревья решений могут страдать от переобучения, но случайный лес предотвращает переобучение, создавая деревья на случайных выборках.
- Деревья решений вычислительно быстрее, чем случайные леса.
- Случайный лес сложно интерпретировать, а дерево решений легко интерпретировать и преобразовать в правила.
Создание классификатора с использованием Scikit-learn
Вы будете строить модель на основе набора данных о цветках ириса, который является очень известным классификационным датасетом. Он включает длину и ширину чашелистика, длину и ширину лепестка, и тип цветка. Существуют три вида (класса) ирисов: Setosa, Versicolor и Virginica. Вы построите модель, определяющую тип цветка из вышеперечисленных. Этот датасет доступен в библиотеке scikit-learn или вы можете загрузить его из репозитория машинного обучения UCI.
Начнем с импорта datasets из scikit-learn и загрузим набор данных iris с помощью load_iris() .
Источник