Теория графов. Термины и определения в картинках

В этой статье мы познакомимся с основными терминами и определениями Теории графов. Каждый термин схематично показан на картинках.
Самый объёмный модуль на курсе «Алгоритмы и структуры данных» посвящён теории графов.
Граф — это топологичекая модель, которая состоит из множества вершин и множества соединяющих их рёбер. При этом значение имеет только сам факт, какая вершина с какой соединена.
Например, граф на рисунке состоит из 8 вершин и 8 рёбер.

Очень многие задачи могут быть решены используя богатую библиотеку алгоритмов теории графов. Для этого достаточно лишь принять объекты за вершины, а связь между ними — за рёбра, после чего весь арсенал алгоритмов теории графов к вашим услугам: нахождение маршрута от одного объекта к другому, поиск связанных компонент, вычисление кратчайших путей, поиск сети максимального потока и многое другое.
В этой статье мы познакомимся с основными терминами и определениями теории графов. На курсе “Алгоритмы и Структуры данных” в компании Отус “Теория графов” изучается в самом объёмном модуле из 6 вебинаров, где мы изучаем десяток самых популярных алгоритмов.
Вершина — точка в графе, отдельный объект, для топологической модели графа не имеет значения координата вершины, её расположение, цвет, вкус, размер; однако при решении некоторых задачах вершины могут раскрашиваться в разные цвета или сохранять числовые значения.
Ребро — неупорядоченная пара двух вершин, которые связаны друг с другом. Эти вершины называются концевыми точками или концами ребра. При этом важен сам факт наличия связи, каким именно образом осуществляется эта связь и по какой дороге — не имеет значения; однако рёбра может быть присвоен “вес”, что позволит говорить о “нагруженном графе” и решать задачи оптимизации.
Инцидентность — вершина и ребро называются инцидентными, если вершина является для этого ребра концевой. Обратите внимание, что термин “инцидентность” применим только к вершине и ребру.
Смежность вершин — две вершины называются смежными, если они инцидентны одному ребру.
Смежность рёбер — два ребра называются смежными, если они инцедентны одной вершине.
Говоря проще — две вершины смежные, если они соединены ребром, два ребра смежные — если они соединены вершиной.

Петля — ребро, инцидентное одной вершине. Ребро, которое замыкается на одной вершине.
Псевдограф — граф с петлями. С такими графами не очень удобно работать, потому что переходя по петле мы остаёмся в той же самой вершине, поэтому у него есть своё название.

Кратные рёбра — рёбра, имеющие одинаковые концевые вершины, по другому их называют ещё параллельными.
Мультиграф — граф с кратными рёбрами.
Псевдомультиграф — граф с петлями и кратными рёбрами.

Степень вершины — это количество рёбер, инцидентных указанной вершине. По-другому — количество рёбер, исходящих из вершины. Петля увеливает степень вершины на 2.
Изолированная вершина — вершина с нулевой степенью.
Висячая вершина — вершина со степенью 1.

Подграф. Если в исходном графе выделить несколько вершин и несколько рёбер (между выбранными вершинами), то мы получим подграф исходного графа.

Идея подграфов используется во многих алгоритмах, например, сначала создаётся подграф их всех вершин без рёбер, а потом дополняется выбранными рёбрами.
Полный граф — это граф, в котором каждые две вершины соединены одним ребром.

Сколько рёбер в полном графе? Это известная задача о рукопожатиях: собралось N человек (вершин) и каждый с каждым обменялся рукопожатием (ребро), сколько всего было рукопожатий? Вычисляется как сумма чисел от 1 до N — каждый новый участник должен пожать руку всем присутствующим, вычисляется по формуле: N * (N — 1) / 2.
Регулярный граф — граф, в котором степени всех вершин одинаковые.

Двудольный граф — если все вершины графа можно разделить на два множества таким образом, что каждое ребро соединяет вершины из разных множеств, то такой граф называется двудольным. Например, клиент-серверное приложение содержит множество запросов (рёбер) между клиентом и сервером, но нет запросов внутри клиента или внутри сервера.

Планарный граф. Если граф можно разместить на плоскости таким образом, чтобы рёбра не пересекались, то он называется “планарным графом” или “плоским графом”.

Если это невозможно сделать, то граф называется “непланарным”.
Минимальные непланарные графы — это полный граф К5 из 5 вершин и полный двудольный граф К3,3 из 3+3 вершин (известная задача о 3 соседях и 3 колодцах). Если какой-либо граф в качестве подграфа содержит К5 или К3,3, то он является непланарным.

Путь или Маршрут — это последовательность смежных рёбер. Обычно путь задаётся перечислением вершин, по которым он пролегает.
Длина пути — количество рёбер в пути.
Цепь — маршрут без повторяющихся рёбер.
Простая цепь — цепь без повторяющихся вершин.

Цикл или Контур — цепь, в котором последняя вершина совпадает с первой.
Длина цикла — количество рёбер в цикле.
Самый короткий цикл — это петля.

Цикл Эйлера — цикл, проходящий по каждому ребру ровно один раз. Эйлер доказал, что такой цикл существует тогда, и только тогда, когда все вершины в связанном графе имеют чётную степень.

Цикл Гамильтона — цикл, проходящий через все вершины графа по одному разу. Другими словами — это простой цикл, в который входят все вершины графа.

Взвешенный граф — граф, в котором у каждого ребра и/или каждой вершины есть “вес” — некоторое число, которое может обозначать длину пути, его стоимость и т. п. Для взвешенного графа составляются различные алгоритмы оптимизации, например поиск кратчайшего пути.

Пока ещё не придуман алгоритм, который за полиномиальное время нашёл бы кратчайший цикл Гамильтона в полном нагруженном графе, однако есть несколько приближённых алгоритмов, которые за приемлимое время находят если не кратчайший, то очень короткий цикл, эти алгоритмы мы также рассматриваем на курсе Отуса — “Алгоритмы и структуры данных”.
Связный граф — граф, в котором существует путь между любыми двумия вершинами.
Дерево — связный граф без циклов.
Между любыми двумя вершинами дерева существует единственный путь.
Деревья часто используются для организации иерархической структуры данных, например, при создании двоичных деревьев поиска или кучи, в этом случае одну вершину дерева называют корнем.

Лес — граф, в котором несколько деревьев.

Ориентированный граф или Орграф — граф, в котором рёбра имеют направления.
Дуга — направленные рёбра в ориентированном графе.

Полустепень захода вершины — количество дуг, заходящих в эту вершину.
Исток — вершина с нулевой полустепенью захода.
Полустепень исхода вершины — количество дуг, исходящих из этой вершины
Сток — вершина с нулевой полустепенью исхода.

Компонента связности — множество таких вершин графа, что между любыми двумя вершинами существует маршрут.

Компонента сильной связности — максимальное множество вершин орграфа, между любыми двумя вершинами которого существует путь по дугам.
Компонента слабой связности — максимальное множество вершин орграфа, между любыми двумя вершинами которого существует путь по дугам без учёта направления (по дугам можно двигаться в любом направлении).

Мост — ребро, при удалении которого, количество связанных компонент графа увеличивается.

Это только основные термины и определения теории графов, которые мы рассматриваем на первом вебинаре модуля “Теория графов”. Цель статьи — дать наглядное и понятное представление об этих терминах, для чего и были нарисованы эти картинки.
Источник
Деревья как виды графов

Поиск значения в BST занимает O(log n) времени. Это означает, что можно очень быстро найти требуемое значение среди миллионов или даже миллиардов записей.
Предположим, мы ищем узел со значением x. Чтобы быстро найти его в BST, воспользуемся следующим алгоритмом:
- Начать с корня дерева.
- Если x = значению узла: остановиться.
- Если x < значения узла: перейти к левому дочернему узлу.
- Если x > значения узла: перейти к правому дочернему узлу.
- Перейти к шагу 2.
При отсутствии уверенности в существовании искомого узла, необходимо изменить шаги 3 и 4 для остановки поиска.
Если хочешь подтянуть свои знания по алгоритмам, загляни на наш курс «Алгоритмы и структуры данных», на котором ты:
- углубишься в теорию структур данных;
- научишься решать сложные алгоритмические задачи;
- научишься применять алгоритмы и структуры данных при разработке программ.
Реализация
Создание узла TreeNode идентично созданию узла ListNode . Единственное отличие в том, что вместо одного атрибута у нас два: left и right , которые ссылаются на левые и правые дочерние узлы.
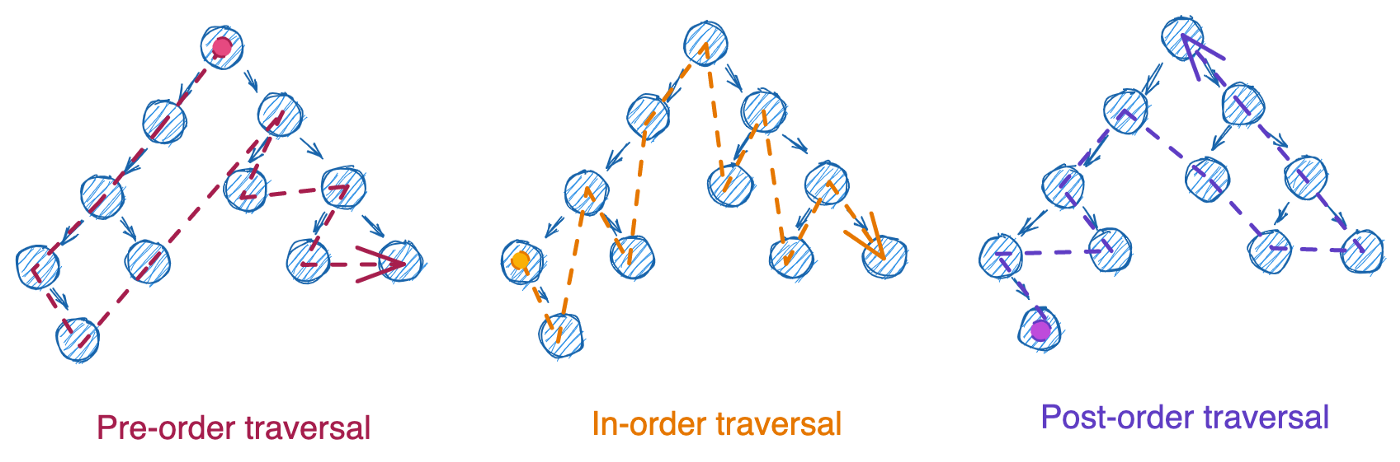
Эти три типа обхода могут быть реализованы следующими методами:
- с итерацией – использование цикла while и стека. В этом случае удаление данных возможно только с конца.
- с рекурсией – использование функции, которая вызывает сама себя.
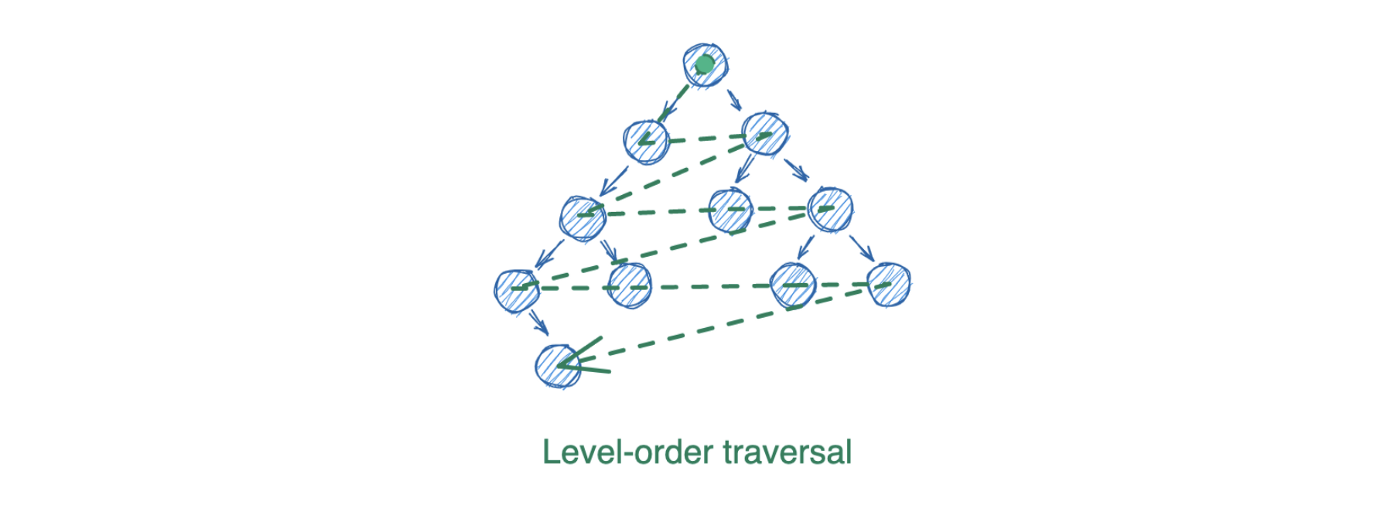
Есть четвертый тип обхода – порядок уровней (level-order traversal). Этот способ использует очередь (queue). Удаление данных здесь возможно только с начала.
Для первых трех типов обработки узлов паттерны практически идентичны. Просто выберем обход в порядке возрастания. Ниже разберем итеративный и рекурсивный методы для LC 94: Binary Tree Inorder Traversal, начиная с итеративной версии:
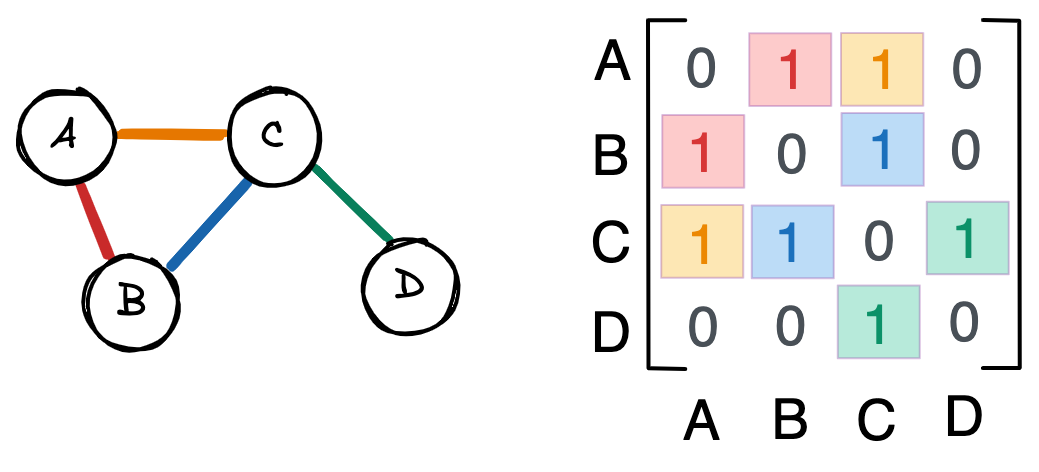
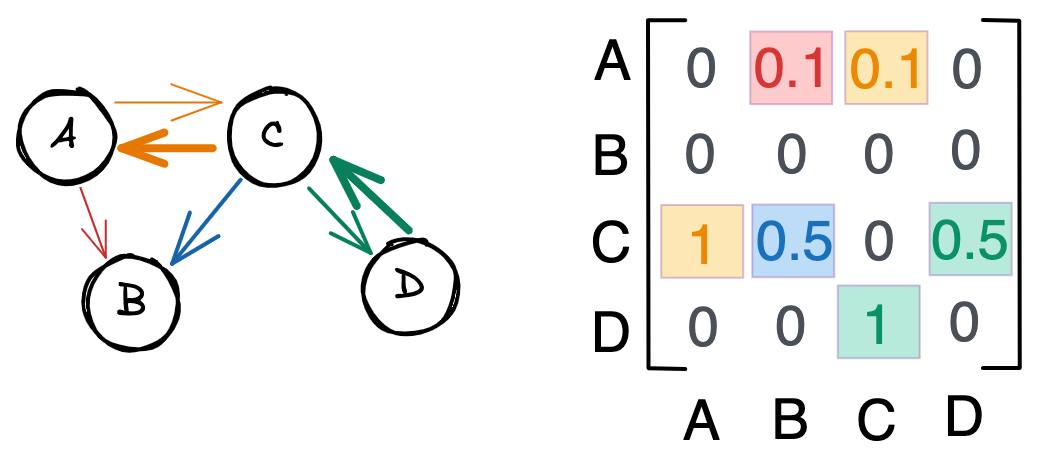
Как правило, графы представлены в виде матриц смежности (adjacency matrix). Так, у приведенного выше графа будет следующая матрица.

Каждая строка и столбец представляют собой узел. Единица в строке i и столбце j , или A_=1 , означает связь между узлом i и узлом j .
A_=0 означает, что узлы i и j не связаны.
Ни один из узлов в этом графе не связан с самим собой. Следовательно, диагональ матрицы равна нулю. Аналогично, A_ = A_ , потому что связи ненаправленны. То есть если узел A связан с узлом B , то B связан с A . В результате матрица смежности симметрична по диагонали.
Рассмотрим пример, который поможет нам понять описанную выше теорию.
На представленных рисунках мы видим взвешенный граф с направленными ребрами. Обратите внимание, что связи больше не симметричны – вторая строка матрицы смежности пуста, потому что у B нет исходящих связей. Числа от 0 до 1 отражают силу связи. Например, граф C влияет на граф A сильнее, чем A на C .
Реализация
Реализуем невзвешенный и неориентированный граф. Основной структурой класса является список списков Python. Каждый из них – это строка. Индексы в списке представляют собой столбцы. При создании объекта Graph необходимо указать количество узлов n, чтобы создать список списков. Затем мы можем получить доступ к соединению между узлами a и b с помощью self.graph[a][b] .
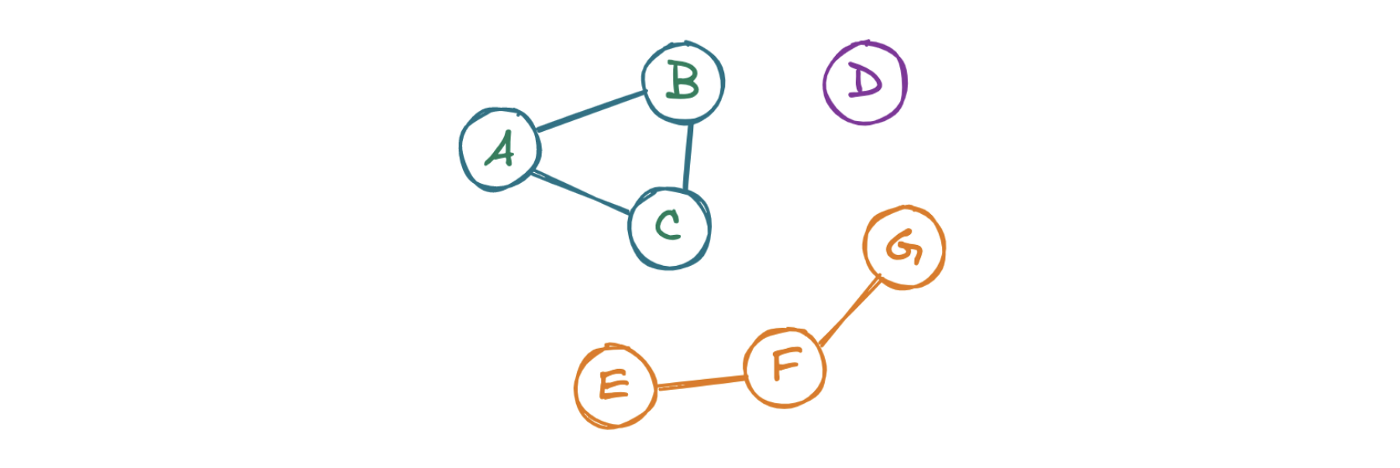
Чтобы ответить на вопрос LC 323: Количество связных компонентов, изучим каждый узел графа. Далее «посетим» соседние графы. Повторяем операцию до тех пор, пока не встретим только те узлы, которые уже были замечены программой. После этого проверим наличие в графе узлов, которые еще не были замечены. Если такие узлы присутствуют, то существует еще как минимум один кластер, поэтому нужно взять новый узел и повторить процесс.
def get_n_components(self, mat: List[List[int]]) -> int: """ Учитывая матрицу смежности, возвращает количество связанных компонентов """ q = [] unseen = [*range(len(mat))] answer = 0 while q or unseen: # Если все соседние узлы прошли через цикл, переходим к новому кластеру if not q: q.append(unseen.pop(0)) answer += 1 # Выбираем узел из текущего кластера focal = q.pop(0) i = 0 # Поиск связей во всех оставшихся узлах while i < len(unseen): node = unseen[i] # Если узел подключен к центру, добавляем его в очередь # чтобы перебрать его соседей # из невидимых узлов и избежать бесконечного цикла if mat[focal][node] == 1: q.append(node) unseen.remove(node) else: i += 1 return answer- Строки 5-8: Создаем очередь ( q ), список узлов ( unseen ) и количество компонентов ( answer ).
- Строка 10: Запускаем цикл while , который выполняем до тех пор, пока в очереди есть узлы, которые нужно обработать или узлы, которые не были замечены.
- Строки 13-15: Если очередь пуста, удаляем первый узел из непросмотренных и увеличиваем количество компонентов.
- Строки 18-19: Выбираем следующий доступный узел в очереди ( focal ).
- Строка 22: Запускаем цикл while , который выполняем до тех пор, пока не обработаем все оставшиеся узлы.
- Строка 23: Даем имя текущему узлу для оптимизации кода.
- Строки 28-30: Если текущий узел подключен к центру, добавляем его в очередь узлов текущего кластера. Удаляем его из списка тех узлов, которые могут находиться в невидимом кластере. Благодаря этому действию, мы избегаем бесконечного цикла.
- Строки 31-32: Если текущий узел не подключен к focal (центру), переходим к следующему узлу.
Заключение
Графы и деревья – основные структуры данных. Спектр их применения огромен. Например, графы используются там, где необходим алгоритм поиска решений. Реальный пример их использования – sea-of-nodes JIT-компилятора.
Деревья используются тогда, когда мы должны произвести быстрое добавление/удаление объекта с поиском по ключу. Например, в различных словарях и индексах БД (Баз данных). Кроме того, деревья являются неотъемлемой частью случайного леса – алгоритма машинного обучения.
В следующей части материала мы приступим к изучению хэш-таблиц.
Базовый и продвинутый курс «Алгоритмы и структуры данных» включает в себя:
- Живые вебинары 2 раза в неделю.
- 47 видеолекций и 150 практических заданий.
- Консультации с преподавателями курса.
Материалы по теме
Источник