- Дерево решений против случайных лесов: в чем разница?
- Плюсы и минусы: деревья решений против случайных лесов
- Когда использовать деревья решений против случайных лесов
- Дополнительные ресурсы
- Деревья решений случайный лес
- Порядок действий в алгоритме
- Теоретическая составляющая алгоритма случайного дерева
- Реализация алгоритма Random Forest
- Недостатки алгоритма
- Заключение
Дерево решений против случайных лесов: в чем разница?
Дерево решений — это тип модели машинного обучения, который используется, когда связь между набором переменных-предикторов и переменной отклика нелинейна.
Основная идея дерева решений состоит в том, чтобы построить «дерево» с использованием набора переменных-предикторов, которые предсказывают значение некоторой переменной ответа с использованием правил принятия решений.
Например, мы можем использовать предикторные переменные «количество лет игры» и «среднее количество хоум-ранов», чтобы предсказать годовую зарплату профессиональных бейсболистов.
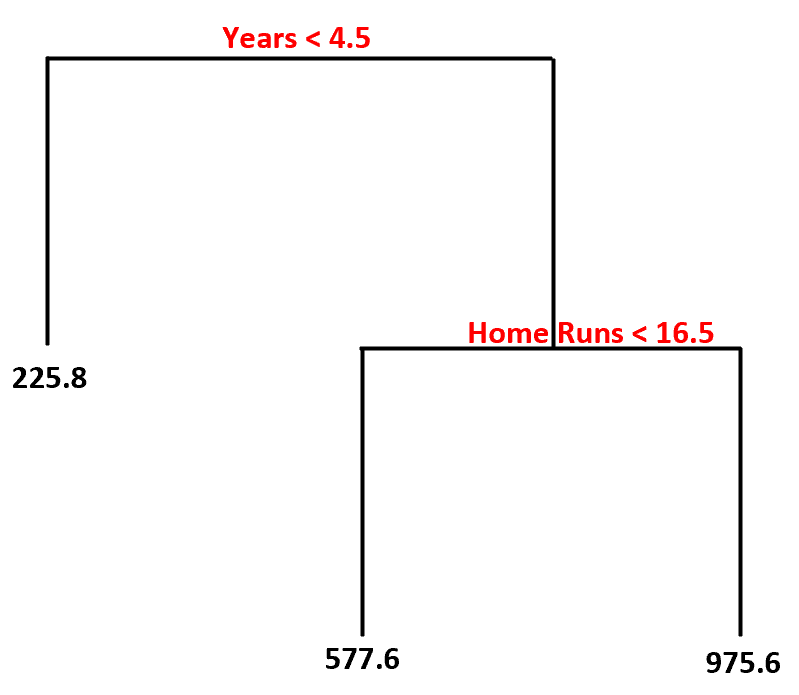
Используя этот набор данных, вот как может выглядеть модель дерева решений:

Вот как мы интерпретируем это дерево решений:
- Прогнозируемая зарплата игроков, игравших менее 4,5 лет, составляет 225,8 тысяч долларов .
- Прогнозируемая зарплата игроков со стажем игры более или равным 4,5 года и средним показателем хоумранов менее 16,5 имеет прогнозируемую зарплату в размере 577,6 тыс.долларов.
- Прогнозируемая зарплата игроков со стажем игры не менее 4,5 лет и средним показателем хоумранов не менее 16,5 имеет прогнозируемую зарплату в размере 975,6 тыс.долларов.
Основное преимущество дерева решений заключается в том, что его можно быстро подогнать к набору данных, а окончательную модель можно аккуратно визуализировать и интерпретировать с помощью «древовидной» диаграммы, подобной приведенной выше.
Основным недостатком является то, что дерево решений склонно к переоснащению обучающего набора данных, а это означает, что оно может плохо работать с невидимыми данными. На него также могут сильно влиять выбросы в наборе данных.
Расширением дерева решений является модель, известная как случайный лес , которая по сути представляет собой набор деревьев решений.
Вот шаги, которые мы используем для построения модели случайного леса:
1. Возьмите загрузочные образцы из исходного набора данных.
2. Для каждой выборки с начальной загрузкой постройте дерево решений, используя случайное подмножество переменных-предикторов.
3. Усредните прогнозы каждого дерева, чтобы получить окончательную модель.
Преимущество случайных лесов заключается в том, что они, как правило, работают намного лучше, чем деревья решений, на невидимых данных и менее подвержены выбросам.
Недостатком случайных лесов является то, что нет возможности визуализировать окончательную модель, и их создание может занять много времени, если у вас недостаточно вычислительной мощности или если набор данных, с которым вы работаете, чрезвычайно велик.
Плюсы и минусы: деревья решений против случайных лесов
В следующей таблице приведены плюсы и минусы деревьев решений по сравнению со случайными лесами:
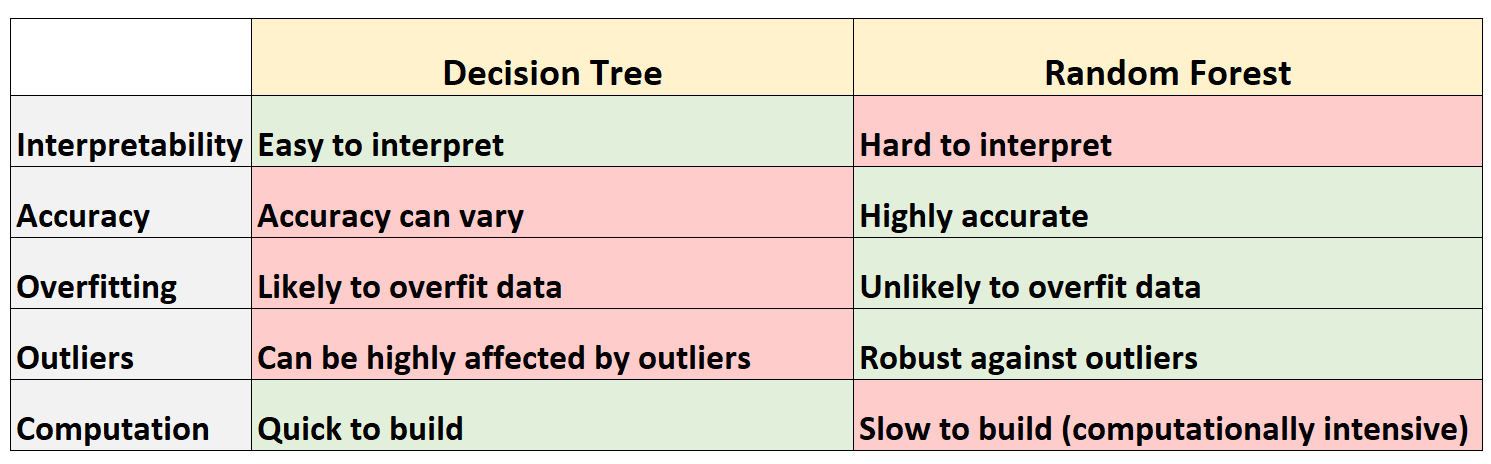
Вот краткое объяснение каждой строки в таблице:
1. Интерпретируемость
Деревья решений легко интерпретировать, потому что мы можем создать древовидную диаграмму, чтобы визуализировать и понять окончательную модель.
И наоборот, мы не можем визуализировать случайный лес, и часто бывает трудно понять, как окончательная модель случайного леса принимает решения.
Поскольку деревья решений, скорее всего, будут соответствовать обучающему набору данных, они, как правило, работают хуже, чем на невидимых наборах данных.
И наоборот, случайные леса, как правило, очень точны для невидимых наборов данных, поскольку они избегают переобучения обучающих наборов данных.
3. Переобучение
Как упоминалось ранее, деревья решений часто превосходят обучающие данные — это означает, что они, скорее всего, соответствуют «шуму» в наборе данных, а не истинному базовому шаблону.
И наоборот, поскольку случайные леса используют только некоторые переменные-предикторы для построения каждого отдельного дерева решений, окончательные деревья, как правило, декоррелированы, что означает, что модели случайного леса вряд ли будут соответствовать наборам данных.
Деревья решений очень подвержены влиянию выбросов.
И наоборот, поскольку модель случайного леса строит множество отдельных деревьев решений, а затем берет среднее значение предсказаний этих деревьев, гораздо меньше вероятность того, что на нее повлияют выбросы.
Деревья решений можно быстро адаптировать к наборам данных.
И наоборот, случайные леса требуют гораздо больше вычислительных ресурсов, и их создание может занять много времени в зависимости от размера набора данных.
Когда использовать деревья решений против случайных лесов
Как правило большого пальца:
Вам следует использовать дерево решений, если вы хотите быстро построить нелинейную модель и хотите иметь возможность легко интерпретировать, как модель принимает решения.
Тем не менее, вам следует использовать случайный лес , если у вас достаточно вычислительных способностей и вы хотите построить модель, которая, вероятно, будет очень точной, не беспокоясь о том, как ее интерпретировать.
В реальном мире инженеры по машинному обучению и специалисты по данным часто используют случайные леса, потому что они очень точны, а современные компьютеры и системы часто могут обрабатывать большие наборы данных, которые раньше не могли обрабатываться.
Дополнительные ресурсы
Следующие руководства содержат введение как в деревья решений, так и в модели случайного леса:
В следующих руководствах объясняется, как подогнать деревья решений и случайные леса в R:
Источник
Деревья решений случайный лес

Здесь мы на основе классификации просто добавляем метод для отбора признаков.
Порядок действий в алгоритме
- Загрузите ваши данные.
- В заданном наборе данных определите случайную выборку.
- Далее алгоритм построит по выборке дерево решений.
- Дерево строится, пока в каждом листе не более n объектов, или пока не будет достигнута определенная высота.
- Затем будет получен результат прогнозирования из каждого дерева решений.
- На этом этапе голосование будет проводиться для каждого прогнозируемого результата: мы выбираем лучший признак, делаем разбиение в дереве по нему и повторяем этот пункт до исчерпания выборки.
- В конце выбирается результат прогноза с наибольшим количеством голосов. Это и есть окончательный результат прогнозирования.
Теоретическая составляющая алгоритма случайного дерева
По сравнению с другими методами машинного обучения, теоретическая часть алгоритма Random Forest проста. У нас нет большого объема теории, необходима только формула итогового классификатора a(x) :
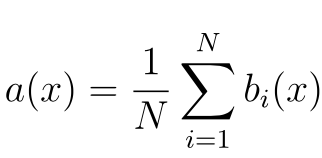
- N – количество деревьев;
- i – счетчик для деревьев;
- b – решающее дерево;
- x – сгенерированная нами на основе данных выборка.
Стоит также отметить, что для задачи классификации мы выбираем решение голосованием по большинству, а в задаче регрессии – средним.
Реализация алгоритма Random Forest
Реализуем алгоритм на простом примере для задачи классификации, используя библиотеку scikit-learn:

- Имеет высокую точность предсказания, которая сравнима с результатами градиентного бустинга.
- Не требует тщательной настройки параметров, хорошо работает из коробки.
- Практически не чувствителен к выбросам в данных из-за случайного семплирования (random sample).
- Не чувствителен к масштабированию и к другим монотонным преобразованиям значений признаков.
- Редко переобучается. На практике добавление деревьев только улучшает композицию.
- В случае наличия проблемы переобучения, она преодолевается путем усреднения или объединения результатов различных деревьев решений.
- Способен эффективно обрабатывать данные с большим числом признаков и классов.
- Хорошо работает с пропущенными данными – сохраняет хорошую точность даже при их наличии.
- Одинаково хорошо обрабатывает как непрерывные, так и дискретные признаки
- Высокая параллелизуемость и масштабируемость.
Недостатки алгоритма

- Для реализации алгоритма случайного дерева требуется значительный объем вычислительных ресурсов.
- Большой размер моделей.
- Построение случайного леса отнимает больше времени, чем деревья решений или линейные алгоритмы.
- Алгоритм склонен к переобучению на зашумленных данных.
- Нет формальных выводов, таких как p-values, которые используются для оценки важности переменных.
- В отличие от более простых алгоритмов, результаты случайного леса сложнее интерпретировать.
- Когда в выборке очень много разреженных признаков, таких как тексты или наборы слов (bag of words), алгоритм работает хуже чем линейные методы.
- В отличие от линейной регрессии, Random Forest не обладает возможностью экстраполяции. Это можно считать и плюсом, так как в случае выбросов не будет экстремальных значений.
- Если данные содержат группы признаков с корреляцией, которые имеют схожую значимость для меток, то предпочтение отдается небольшим группам перед большими, что ведет к недообучению.
- Процесс прогнозирования с использованием случайных лесов очень трудоемкий по сравнению с другими алгоритмами.
Заключение
Метод случайного дерева (Random Forest) – это универсальный алгоритм машинного обучения с учителем. Его можно использовать во множестве задач, но в основном он применяется в проблемах классификации и регрессии.
Действенный и простой в понимании, алгоритм имеет значительный недостаток – заметное замедление работы при определенной настройке параметров внутри него.
Вы можете использовать случайный лес, если вам нужны чрезвычайно точные результаты или у вас есть огромный объем данных для обработки, и вам нужен достаточно сильный алгоритм, который позволит вам эффективно обработать все данные.
Дополнительные материалы:
Источник