Обход DOM элементов в js
Вот пример реализации ( универсальный, для подобных структур ):
tab_buff = []; function tab( level ) < if ( tab_buff[level] ) return tab_buff[level]; var i, res = []; for (i = 0; i < level; i++ ) res.push("|"); res.push("-"); return tab_buff[level] = res.join(''); >function print_tree( root, child_prop, next_prop ) < var stack = [], level = 0, curr = root, res = [], type = true; while( curr )< if ( type ) res.push( tab(level) + curr.tagName ); if ( type && curr[child_prop] )< type = true; level++; stack.push( curr ); curr = curr[child_prop]; >else if ( curr[next_prop] ) < type = true; curr = curr[next_prop]; >else < type = false; level--; curr = stack.pop(); >> return res.join("\n"); > res = print_tree( document.getElementsByTagName('html')[0], 'firstElementChild', 'nextElementSibling' ); в итоге в res будет что-то типа:
-HTML |-HEAD ||-TITLE ||-STYLE ||-SCRIPT ||-SCRIPT |-BODY ||-TABLE |||-TBODY ||||-TR |||||-TD ||||||-A ||||-TR |||||-TD ||||||-FORM |||||||-INPUT |||||||-INPUT |||||||-INPUT ||-SCRIPT Надеялся на наличие унифицированного способа, функции. Но по видимому придётся-таки обходить через цикл.
Например вы хотите обойти все элементы с тегом «a», то есть все ссылки. Тогда код будет иметь следующий вид:
var tag = 'a',//присваиваем переменной tag название нашего тега elems = document.getElementsByTagName(tag), //присваиваем переменной elems все элементы с название тега 'a' elem,//объявляем переменную elem, в ней будем хранить каждый элемент массива при его обходе k;//переменная k будет содержать порядковый номер элемента в массиве начиная с 0 for (k in elems) //для < elem=elems[k]; //здесь может быть ваш код. >Напишите, что именно вам нужно, тогда я смогу ответить более конкретно.
Источник
Навигация по DOM-элементам
Материал на этой странице устарел, поэтому скрыт из оглавления сайта.
Более новая информация по этой теме находится на странице https://learn.javascript.ru/dom-navigation.
DOM позволяет делать что угодно с HTML-элементом и его содержимым, но для этого нужно сначала нужный элемент получить.
Доступ к DOM начинается с объекта document . Из него можно добраться до любых узлов.
Так выглядят основные ссылки, по которым можно переходить между узлами DOM:
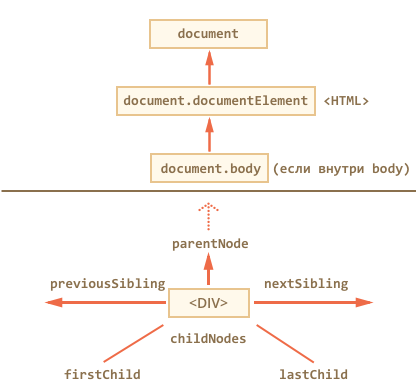
Посмотрим на них повнимательнее.
Сверху documentElement и body
Самые верхние элементы дерева доступны напрямую из document .
= document.documentElement Первая точка входа – document.documentElement . Это свойство ссылается на DOM-объект для тега . = document.body Вторая точка входа – document.body , который соответствует тегу .
В современных браузерах (кроме IE8-) также есть document.head – прямая ссылка на
Нельзя получить доступ к элементу, которого ещё не существует в момент выполнения скрипта.
В частности, если скрипт находится в , то в нём недоступен document.body .
Поэтому в следующем примере первый alert выведет null :
В мире DOM в качестве значения, обозначающего «нет такого элемента» или «узел не найден», используется не undefined , а null .
Дети: childNodes, firstChild, lastChild
Здесь и далее мы будем использовать два принципиально разных термина.
- Дочерние элементы (или дети) – элементы, которые лежат непосредственно внутри данного. Например, внутри обычно лежат и .
- Потомки – все элементы, которые лежат внутри данного, вместе с их детьми, детьми их детей и так далее. То есть, всё поддерево DOM.
Псевдо-массив childNodes хранит все дочерние элементы, включая текстовые.
Пример ниже последовательно выведет дочерние элементы document.body :
Обратим внимание на маленькую деталь. Если запустить пример выше, то последним будет выведен элемент . На самом-то деле в документе есть ещё текст (обозначенный троеточием), но на момент выполнения скрипта браузер ещё до него не дошёл.
Пробельный узел будет в итоговом документе, но его ещё нет на момент выполнения скрипта.
Скажем больше – все навигационные свойства, которые перечислены в этой главе – только для чтения. Нельзя просто заменить элемент присвоением childNodes[i] = . .
Изменение DOM осуществляется другими методами, которые мы рассмотрим далее, все навигационные ссылки при этом обновляются автоматически.
Свойства firstChild и lastChild обеспечивают быстрый доступ к первому и последнему элементу.
При наличии дочерних узлов всегда верно:
elem.childNodes[0] === elem.firstChild elem.childNodes[elem.childNodes.length - 1] === elem.lastChildКоллекции – не массивы
DOM-коллекции, такие как childNodes и другие, которые мы увидим далее, не являются JavaScript-массивами.
В них нет методов массивов, таких как forEach , map , push , pop и других.
var elems = document.documentElement.childNodes; elems.forEach(function(elem) < // нет такого метода! /* . */ >);Именно поэтому childNodes и называют «коллекция» или «псевдомассив».
Это возможно, основных варианта два:
- Применить метод массива через call/apply :
var elems = document.documentElement.childNodes; [].forEach.call(elems, function(elem) < alert( elem ); // HEAD, текст, BODY >);var elems = document.documentElement.childNodes; elems = Array.prototype.slice.call(elems); // теперь elems - массив elems.forEach(function(elem) < alert( elem.tagName ); // HEAD, текст, BODY >);Ранее мы говорили, что не рекомендуется использовать для перебора массива цикл for..in .
Коллекции – наглядный пример, почему нельзя. Они похожи на массивы, но у них есть свои свойства и методы, которых в массивах нет.
К примеру, код ниже должен перебрать все дочерние элементы . Их, естественно, два: и . Максимум, три, если взять ещё и текст между ними.
Но в примере ниже alert сработает не три, а целых 5 раз!
var elems = document.documentElement.childNodes; for (var key in elems) < alert( key ); // 0, 1, 2, length, item >Цикл for..in выведет не только ожидаемые индексы 0 , 1 , 2 , по которым лежат узлы в коллекции, но и свойство length (в коллекции оно enumerable), а также функцию item(n) – она никогда не используется, возвращает n-й элемент коллекции, проще обратиться по индексу [n] .
В реальном коде нам нужны только элементы, мы же будем работать с ними, а служебные свойства – не нужны. Поэтому желательно использовать for(var i=0; i
Соседи и родитель
Доступ к элементам слева и справа данного можно получить по ссылкам previousSibling / nextSibling .
Родитель доступен через parentNode . Если долго идти от одного элемента к другому, то рано или поздно дойдёшь до корня DOM, то есть до document.documentElement , а затем и document .
Навигация только по элементам
Навигационные ссылки, описанные выше, равно касаются всех узлов в документе. В частности, в childNodes сосуществуют и текстовые узлы и узлы-элементы и узлы-комментарии, если есть.
Но для большинства задач текстовые узлы нам не интересны.
Поэтому посмотрим на дополнительный набор ссылок, которые их не учитывают:
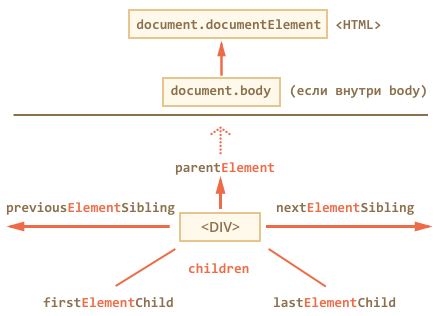
Эти ссылки похожи на те, что раньше, только в ряде мест стоит слово Element :
- children – только дочерние узлы-элементы, то есть соответствующие тегам.
- firstElementChild , lastElementChild – соответственно, первый и последний дети-элементы.
- previousElementSibling , nextElementSibling – соседи-элементы.
- parentElement – родитель-элемент.
Свойство elem.parentNode возвращает родитель элемента.
Оно всегда равно parentElement , кроме одного исключения:
alert( document.documentElement.parentNode ); // document alert( document.documentElement.parentElement ); // nullИногда это имеет значение, если хочется перебрать всех предков и вызвать какой-то метод, а на документе его нет.
Модифицируем предыдущий пример, применив children вместо childNodes .
Теперь он будет выводить не все узлы, а только узлы-элементы:
elem.firstElementChild === elem.children[0] elem.lastElementChild === elem.children[elem.children.length - 1]Других навигационных свойств в этих браузерах нет. Впрочем, как мы увидим далее, можно легко сделать полифил, и они, всё же, будут.
С точки зрения стандарта это ошибка, но IE8- также включает в children узлы, соответствующие HTML-комментариям.
Это может привести к сюрпризам при использовании свойства children , поэтому HTML-комментарии либо убирают либо используют фреймворк, к примеру, jQuery, который даёт свои методы перебора и отфильтрует их.
Особые ссылки для таблиц
У конкретных элементов DOM могут быть свои дополнительные ссылки для большего удобства навигации.
Здесь мы рассмотрим таблицу, так как это важный частный случай и просто для примера.
В списке ниже выделены наиболее полезные:
- table.rows – коллекция строк TR таблицы.
- table.caption/tHead/tFoot – ссылки на элементы таблицы CAPTION , THEAD , TFOOT .
- table.tBodies – коллекция элементов таблицы TBODY , по спецификации их может быть несколько.
- tbody.rows – коллекция строк TR секции.
- tr.cells – коллекция ячеек TD/TH
- tr.sectionRowIndex – номер строки в текущей секции THEAD/TBODY
- tr.rowIndex – номер строки в таблице
- td.cellIndex – номер ячейки в строке
один два три четыре
Даже если эти свойства не нужны вам прямо сейчас, имейте их в виду на будущее, когда понадобится пройтись по таблице.
Конечно же, таблицы – не исключение.
Аналогичные полезные свойства есть у HTML-форм, они позволяют из формы получить все её элементы, а из них – в свою очередь, форму. Мы рассмотрим их позже.
Интерактивное путешествие
Для того, чтобы убедиться, что вы разобрались с навигацией по DOM-ссылкам – вашему вниманию предлагается интерактивное путешествие по DOM.
Ниже вы найдёте документ (в ифрейме), и кнопки для перехода по нему.
Изначальный элемент – . Попробуйте по ссылкам найти «информацию». Или ещё чего-нибудь.
Вы также можете открыть документ в отдельном окне и походить по нему в браузерной консоли разработчика, чтобы лучше понять разницу между показанным там DOM и реальным.
Источник
Traverse the DOM tree
As most (all?) PHP libraries that do HTML sanitization such as HTML Purifier are heavily dependant on regex, I thought trying to write a HTML sanitizer that uses the DOMDocument and related classes would be a worthwhile experiment. While I’m at a very early stage with this, the project so far shows some promise. My idea revolves around a class that uses the DOMDocument to traverse all nodes in the supplied markup, compare them to a white list, and remove anything not on the white list. (first implementation is very basic, only removing nodes based on their type but I hope to get more sophisticated and analyse the node’s attributes, whether links address items in a different domain, etc in the future). My question is how do I traverse the DOM tree? As I understand it, DOM* objects have a childNodes attribute, so would I need to recurse over the whole tree? Also, early experiments with DOMNodeLists have shown you need to be very careful about the order you remove things otherwise you might leave items behind or trigger exceptions. If anyone has experience with manipulating a DOM tree in PHP I’d appreciate any feedback you may have on the topic. EDIT: I’ve built the following method for my HTML cleaning class. It recursively walks the DOM tree and checks whether the found elements are on the whitelist. If they aren’t, they are removed. The problem I was hitting was that if you delete a node, the indexes of all subsequent nodes in the DOMNodeList changes. Simply working from bottom to top avoids this problem. It’s still a very basic approach currently, but I think it shows promise. It certainly works a lot faster than HTMLPurifier, though admittedly Purifier does a lot more stuff.
/** * Recursivly remove elements from the DOM that aren't whitelisted * @param DOMNode $elem * @return array List of elements removed from the DOM * @throws Exception If removal of a node failed than an exception is thrown */ private function cleanNodes (DOMNode $elem) < $removed = array (); if (in_array ($elem ->nodeName, $this -> whiteList)) < if ($elem ->hasChildNodes ()) < /* * Iterate over the element's children. The reason we go backwards is because * going forwards will cause indexes to change when elements get removed */ $children = $elem ->childNodes; $index = $children -> length; while (--$index >= 0) < $removed = array_merge ($removed, $this ->cleanNodes ($children -> item ($index))); > > > else < // The element is not on the whitelist, so remove it if ($elem ->parentNode -> removeChild ($elem)) < $removed [] = $elem; >else < throw new Exception ('Failed to remove node from DOM'); >> return ($removed); > The software already present is stuff like HTMLPurifier, which is slow as hell, and is based on regex. I’m doing this partially because I want to see if there’s a better method, and partially because I want to use the exercise as a learning experience
Источник