Динамические структуры данных: бинарные деревья
Аннотация: В лекции рассматриваются определения, свойства и виды деревьев, элементы, характеристики и способы объявления деревьев в программах, основные операции над элементами деревьев, понятие и виды обходов деревьев, приводятся примеры реализации основных операций над бинарными деревьями в виде рекурсивных функций.
Цель лекции: изучить понятие, формирование, особенности доступа к данным и работы с памятью в бинарных деревьях, научиться решать задачи с использованием рекурсивных функций и алгоритмов обхода бинарных деревьев в языке C++.
Дерево является одним из важнейших и интересных частных случаев графа. Древовидная модель оказывается довольно эффективной для представления динамических данных с целью быстрого поиска информации .
Деревья являются одними из наиболее широко распространенных структур данных в информатике и программировании, которые представляют собой иерархические структуры в виде набора связанных узлов.
Дерево – это структура данных , представляющая собой совокупность элементов и отношений, образующих иерархическую структуру этих элементов ( рис. 31.1). Каждый элемент дерева называется вершиной (узлом) дерева. Вершины дерева соединены направленными дугами, которые называют ветвями дерева. Начальный узел дерева называют корнем дерева, ему соответствует нулевой уровень. Листьями дерева называют вершины, в которые входит одна ветвь и не выходит ни одной ветви.
Каждое дерево обладает следующими свойствами:
- существует узел, в который не входит ни одной дуги (корень);
- в каждую вершину, кроме корня, входит одна дуга.
Деревья особенно часто используют на практике при изображении различных иерархий. Например, популярны генеалогические деревья.
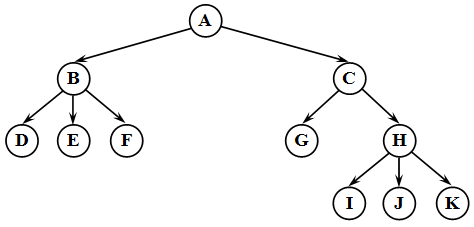
Все вершины, в которые входят ветви, исходящие из одной общей вершины, называются потомками, а сама вершина – предком. Для каждого предка может быть выделено несколько. Уровень потомка на единицу превосходит уровень его предка. Корень дерева не имеет предка, а листья дерева не имеют потомков.
Высота (глубина) дерева определяется количеством уровней, на которых располагаются его вершины. Высота пустого дерева равна нулю, высота дерева из одного корня – единице. На первом уровне дерева может быть только одна вершина – корень дерева , на втором – потомки корня дерева, на третьем – потомки потомков корня дерева и т.д.
Поддерево – часть древообразной структуры данных, которая может быть представлена в виде отдельного дерева.
Степенью вершины в дереве называется количество дуг, которое из нее выходит. Степень дерева равна максимальной степени вершины, входящей в дерево . При этом листьями в дереве являются вершины, имеющие степень нуль. По величине степени дерева различают два типа деревьев:
Упорядоченное дерево – это дерево , у которого ветви, исходящие из каждой вершины, упорядочены по определенному критерию.
Деревья являются рекурсивными структурами, так как каждое поддерево также является деревом. Таким образом, дерево можно определить как рекурсивную структуру, в которой каждый элемент является:
Действия с рекурсивными структурами удобнее всего описываются с помощью рекурсивных алгоритмов.
Списочное представление деревьев основано на элементах, соответствующих вершинам дерева. Каждый элемент имеет поле данных и два поля указателей: указатель на начало списка потомков вершины и указатель на следующий элемент в списке потомков текущего уровня. При таком способе представления дерева обязательно следует сохранять указатель на вершину, являющуюся корнем дерева .
Для того, чтобы выполнить определенную операцию над всеми вершинами дерева необходимо все его вершины просмотреть. Такая задача называется обходом дерева.
Обход дерева – это упорядоченная последовательность вершин дерева, в которой каждая вершина встречается только один раз.
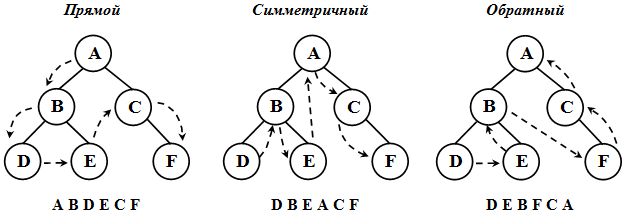
При обходе все вершины дерева должны посещаться в определенном порядке. Существует несколько способов обхода всех вершин дерева. Выделим три наиболее часто используемых способа обхода дерева ( рис. 31.2):
Существует большое многообразие древовидных структур данных. Выделим самые распространенные из них: бинарные (двоичные) деревья, красно-черные деревья, В-деревья, АВЛ-деревья , матричные деревья, смешанные деревья и т.д.
Бинарные деревья
Бинарные деревья являются деревьями со степенью не более двух.
Бинарное (двоичное) дерево – это динамическая структура данных , представляющее собой дерево , в котором каждая вершина имеет не более двух потомков ( рис. 31.3). Таким образом, бинарное дерево состоит из элементов, каждый из которых содержит информационное поле и не более двух ссылок на различные бинарные поддеревья. На каждый элемент дерева имеется ровно одна ссылка .
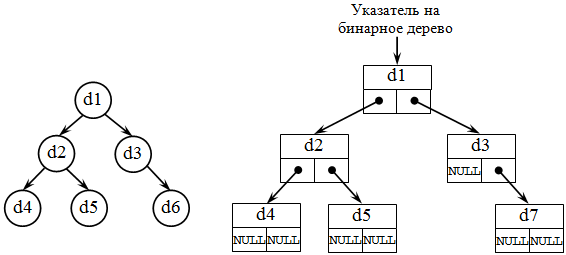
Каждая вершина бинарного дерева является структурой, состоящей из четырех видов полей. Содержимым этих полей будут соответственно:
- информационное поле (ключ вершины);
- служебное поле (их может быть несколько или ни одного);
- указатель на левое поддерево ;
- указатель на правое поддерево .
По степени вершин бинарные деревья делятся на ( рис. 31.4):
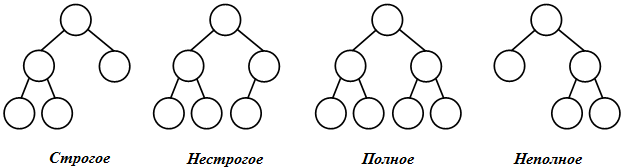
- строгие – вершины дерева имеют степень ноль (у листьев) или два (у узлов);
- нестрогие – вершины дерева имеют степень ноль (у листьев), один или два (у узлов).
В общем случае у бинарного дерева на k -м уровне может быть до 2 k-1 вершин. Бинарное дерево называется полным, если оно содержит только полностью заполненные уровни. В противном случае оно является неполным.
Дерево называется сбалансированным, если длины всех путей от корня к внешним вершинам равны между собой. Дерево называется почти сбалансированным, если длины всевозможных путей от корня к внешним вершинам отличаются не более, чем на единицу.
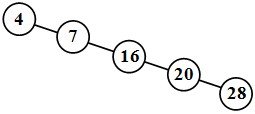
Бинарное дерево может представлять собой пустое множество . Бинарное дерево может выродиться в список ( рис. 31.5).
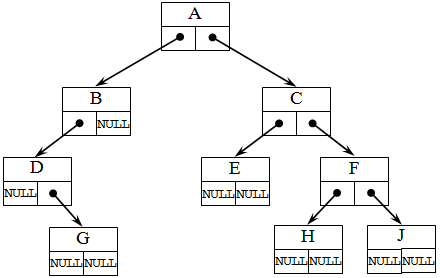
Структура дерева отражается во входном потоке данных так: каждой вводимой пустой связи соответствует условный символ, например, ‘*’ (звездочка). При этом сначала описываются левые потомки, затем, правые. Для структуры бинарного дерева , представленного на следующем рисунке 6, входной поток имеет вид: ABD*G***CE**FH**J** .
Бинарные деревья могут применяться для поиска данных в специально построенных деревьях ( базы данных ), сортировки данных, вычислений арифметических выражений , кодирования (метод Хаффмана) и т.д.
Источник
Дерево
Дерево – структура данных, представляющая собой древовидную структуру в виде набора связанных узлов.
Бинарное дерево — это конечное множество элементов, которое либо пусто, либо содержит элемент ( корень ), связанный с двумя различными бинарными деревьями, называемыми левым и правым поддеревьями . Каждый элемент бинарного дерева называется узлом . Связи между узлами дерева называются его ветвями .

Способ представления бинарного дерева:
Корень дерева расположен на уровне с минимальным значением.
Узел D , который находится непосредственно под узлом B , называется потомком B . Если D находится на уровне i , то B – на уровне i-1 . Узел B называется предком D .
Максимальный уровень какого-либо элемента дерева называется его глубиной или высотой .
Если элемент не имеет потомков, он называется листом или терминальным узлом дерева.
Остальные элементы – внутренние узлы (узлы ветвления).
Число потомков внутреннего узла называется его степенью . Максимальная степень всех узлов есть степень дерева.
Число ветвей, которое нужно пройти от корня к узлу x , называется длиной пути к x . Корень имеет длину пути равную 0 ; узел на уровне i имеет длину пути равную i .
Бинарное дерево применяется в тех случаях, когда в каждой точке вычислительного процесса должно быть принято одно из двух возможных решений.
Имеется много задач, которые можно выполнять на дереве.
Распространенная задача — выполнение заданной операции p с каждым элементом дерева. Здесь p рассматривается как параметр более общей задачи посещения всех узлов или задачи обхода дерева.
Если рассматривать задачу как единый последовательный процесс, то отдельные узлы посещаются в определенном порядке и могут считаться расположенными линейно.
Способы обхода дерева
Пусть имеем дерево, где A — корень, B и C — левое и правое поддеревья.

Существует три способа обхода дерева:
- Обход дерева сверху вниз (в прямом порядке): A, B, C — префиксная форма.
- Обход дерева в симметричном порядке (слева направо): B, A, C — инфиксная форма.
- Обход дерева в обратном порядке (снизу вверх): B, C, A — постфиксная форма.
Реализация дерева
Узел дерева можно описать как структуру:
struct tnode <
int field; // поле данных
struct tnode *left; // левый потомок
struct tnode *right; // правый потомок
>;
При этом обход дерева в префиксной форме будет иметь вид
void treeprint(tnode *tree) <
if (tree!= NULL ) < //Пока не встретится пустой узел
cout field; //Отображаем корень дерева
treeprint(tree->left); //Рекурсивная функция для левого поддерева
treeprint(tree->right); //Рекурсивная функция для правого поддерева
>
>
Обход дерева в инфиксной форме будет иметь вид
void treeprint(tnode *tree) <
if (tree!= NULL ) < //Пока не встретится пустой узел
treeprint(tree->left); //Рекурсивная функция для левого поддерева
cout field; //Отображаем корень дерева
treeprint(tree->right); //Рекурсивная функция для правого поддерева
>
>
Обход дерева в постфиксной форме будет иметь вид
void treeprint(tnode *tree) <
if (tree!= NULL ) < //Пока не встретится пустой узел
treeprint(tree->left); //Рекурсивная функция для левого поддерева
treeprint(tree->right); //Рекурсивная функция для правого поддерева
cout field; //Отображаем корень дерева
>
>
Бинарное (двоичное) дерево поиска – это бинарное дерево, для которого выполняются следующие дополнительные условия (свойства дерева поиска):
- оба поддерева – левое и правое, являются двоичными деревьями поиска;
- у всех узлов левого поддерева произвольного узла X значения ключей данных меньше, чем значение ключа данных самого узла X ;
- у всех узлов правого поддерева произвольного узла X значения ключей данных не меньше, чем значение ключа данных узла X .
Данные в каждом узле должны обладать ключами, на которых определена операция сравнения меньше.
Как правило, информация, представляющая каждый узел, является записью, а не единственным полем данных.
Для составления бинарного дерева поиска рассмотрим функцию добавления узла в дерево.
Добавление узлов в дерево
struct tnode * addnode( int x, tnode *tree) <
if (tree == NULL ) < // Если дерева нет, то формируем корень
tree = new tnode; // память под узел
tree->field = x; // поле данных
tree->left = NULL ;
tree->right = NULL ; // ветви инициализируем пустотой
> else if (x < tree->field) // условие добавление левого потомка
tree->left = addnode(x,tree->left);
else // условие добавление правого потомка
tree->right = addnode(x,tree->right);
return (tree);
>
Удаление поддерева
void freemem(tnode *tree) <
if (tree!= NULL ) <
freemem(tree->left);
freemem(tree->right);
delete tree;
>
>
Пример Написать программу, подсчитывающую частоту встречаемости слов входного потока.
Поскольку список слов заранее не известен, мы не можем предварительно упорядочить его. Неразумно пользоваться линейным поиском каждого полученного слова, чтобы определять, встречалось оно ранее или нет, т.к. в этом случае программа работает слишком медленно.
Один из способов — постоянно поддерживать упорядоченность уже полученных слов, помещая каждое новое слово в такое место, чтобы не нарушалась имеющаяся упорядоченность. Воспользуемся бинарным деревом.
В дереве каждый узел содержит:
- указатель на текст слова;
- счетчик числа встречаемости;
- указатель на левого потомка;
- указатель на правого потомка.
Рассмотрим выполнение программы на примере фразы
now is the time for all good men to come to the aid of their party

При этом дерево будет иметь следующий вид
#include
#include
#include
#include
//#include
#define MAX WORD 100
struct tnode < // узел дерева
char * word; // указатель на строку (слово)
int count; // число вхождений
struct tnode* left; // левый потомок
struct tnode* right; // правый потомок
>;
// Функция добавления узла к дереву
struct tnode* addtree( struct tnode* p, char * w) int cond;
if (p == NULL ) p = ( struct tnode*)malloc( sizeof ( struct tnode));
p->word = _strdup(w);
p->count = 1;
p->left = p->right = NULL ;
>
else if ((cond = strcmp(w, p->word)) == 0)
p->count++;
else if (cond < 0)
p->left = addtree(p->left, w);
else
p->right = addtree(p->right, w);
return p;
>
// Функция удаления поддерева
void freemem(tnode* tree) if (tree != NULL ) freemem(tree->left);
freemem(tree->right);
free(tree->word);
free(tree);
>
>
// Функция вывода дерева
void treeprint( struct tnode* p) if (p != NULL ) treeprint(p->left);
printf( «%d %s\n» , p->count, p->word);
treeprint(p->right);
>
>
int main() struct tnode* root;
char word[MAX WORD ];
root = NULL ;
do scanf_s( «%s» , word, MAX WORD );
if (isalpha(word[0]))
root = addtree(root, word);
> while (word[0] != ‘0’ ); // условие выхода – ввод символа ‘0’
treeprint(root);
freemem(root);
getchar();
getchar();
return 0;
>

Результат выполнения
Комментариев к записи: 19
Источник