Графы деревья порядок дерева

Поиск значения в BST занимает O(log n) времени. Это означает, что можно очень быстро найти требуемое значение среди миллионов или даже миллиардов записей.
Предположим, мы ищем узел со значением x. Чтобы быстро найти его в BST, воспользуемся следующим алгоритмом:
- Начать с корня дерева.
- Если x = значению узла: остановиться.
- Если x < значения узла: перейти к левому дочернему узлу.
- Если x > значения узла: перейти к правому дочернему узлу.
- Перейти к шагу 2.
При отсутствии уверенности в существовании искомого узла, необходимо изменить шаги 3 и 4 для остановки поиска.
Если хочешь подтянуть свои знания по алгоритмам, загляни на наш курс «Алгоритмы и структуры данных», на котором ты:
- углубишься в теорию структур данных;
- научишься решать сложные алгоритмические задачи;
- научишься применять алгоритмы и структуры данных при разработке программ.
Реализация
Создание узла TreeNode идентично созданию узла ListNode . Единственное отличие в том, что вместо одного атрибута у нас два: left и right , которые ссылаются на левые и правые дочерние узлы.
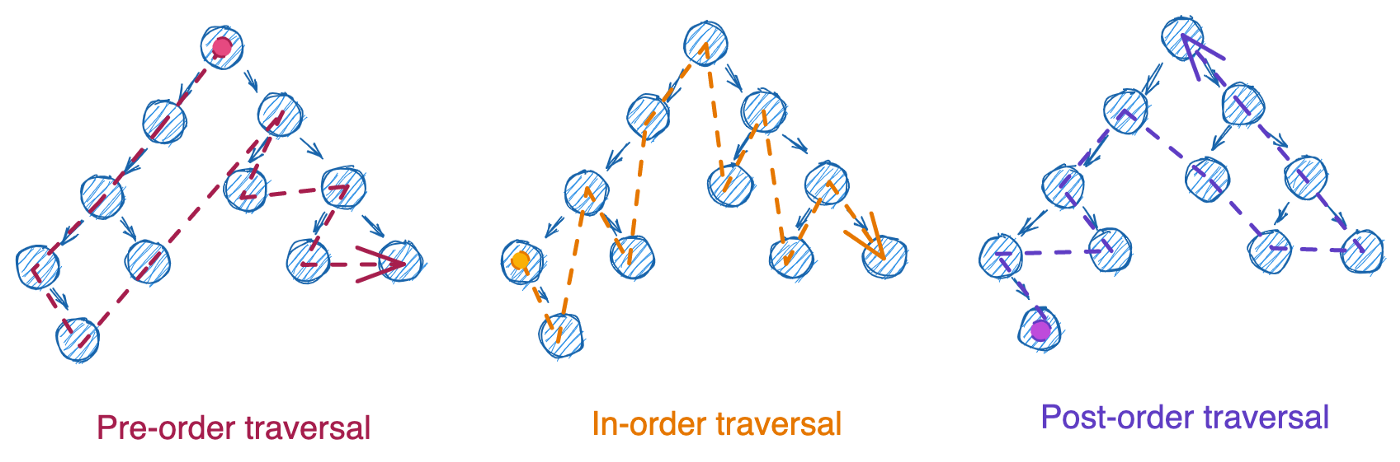
Эти три типа обхода могут быть реализованы следующими методами:
- с итерацией – использование цикла while и стека. В этом случае удаление данных возможно только с конца.
- с рекурсией – использование функции, которая вызывает сама себя.
Есть четвертый тип обхода – порядок уровней (level-order traversal). Этот способ использует очередь (queue). Удаление данных здесь возможно только с начала.
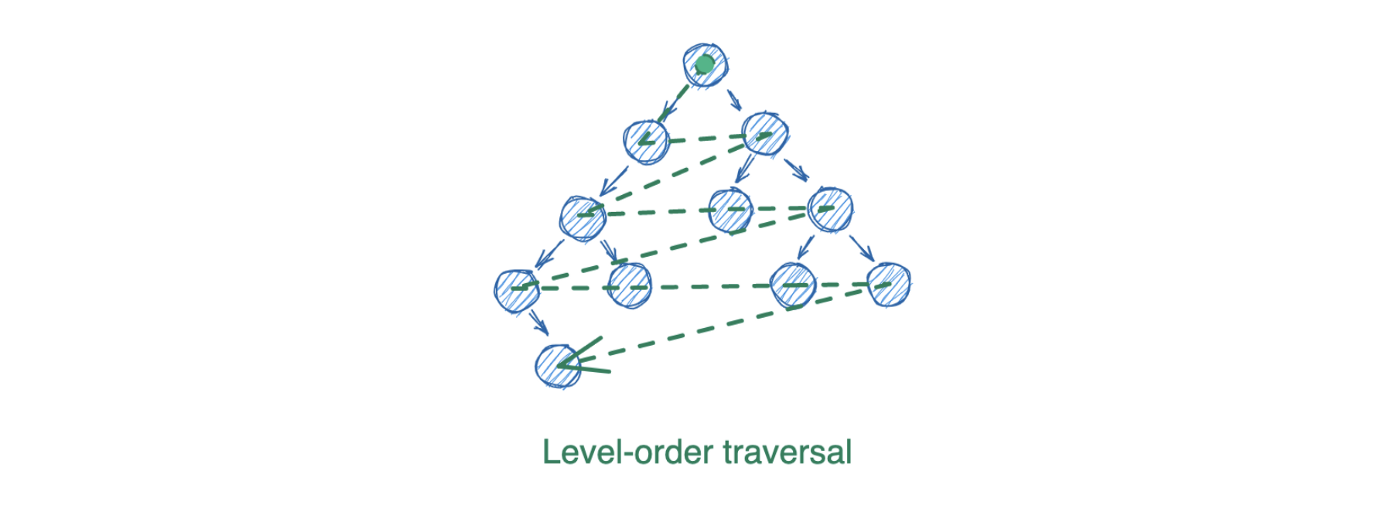
Для первых трех типов обработки узлов паттерны практически идентичны. Просто выберем обход в порядке возрастания. Ниже разберем итеративный и рекурсивный методы для LC 94: Binary Tree Inorder Traversal, начиная с итеративной версии:
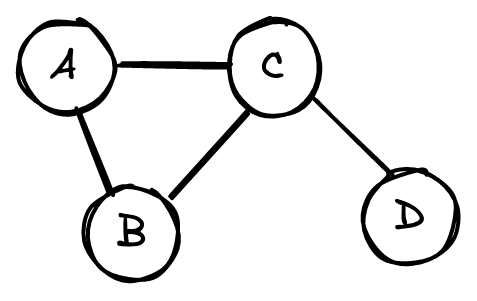
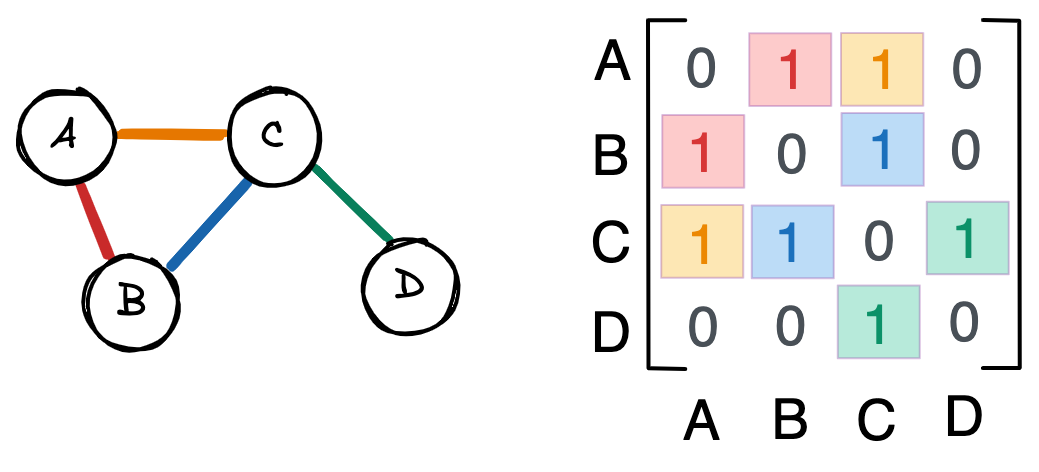
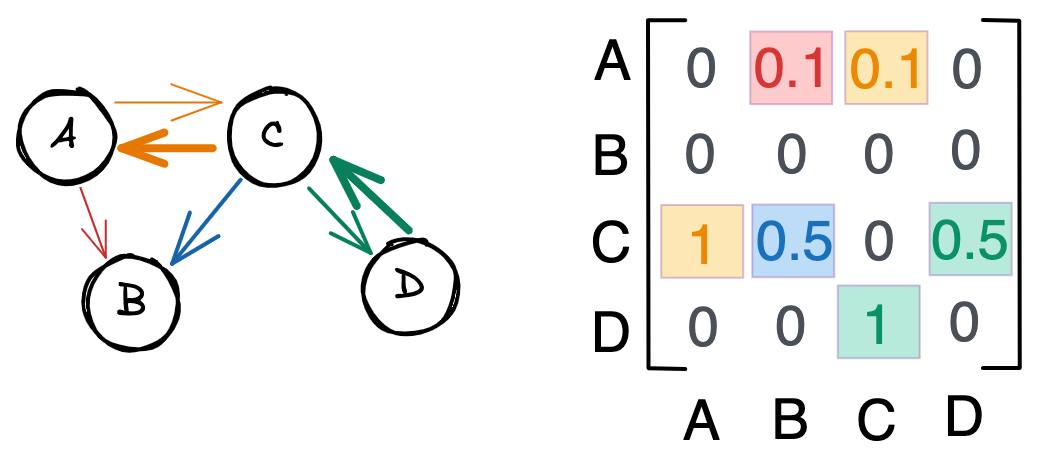
Как правило, графы представлены в виде матриц смежности (adjacency matrix). Так, у приведенного выше графа будет следующая матрица.

Каждая строка и столбец представляют собой узел. Единица в строке i и столбце j , или A_=1 , означает связь между узлом i и узлом j .
A_=0 означает, что узлы i и j не связаны.
Ни один из узлов в этом графе не связан с самим собой. Следовательно, диагональ матрицы равна нулю. Аналогично, A_ = A_ , потому что связи ненаправленны. То есть если узел A связан с узлом B , то B связан с A . В результате матрица смежности симметрична по диагонали.
Рассмотрим пример, который поможет нам понять описанную выше теорию.
На представленных рисунках мы видим взвешенный граф с направленными ребрами. Обратите внимание, что связи больше не симметричны – вторая строка матрицы смежности пуста, потому что у B нет исходящих связей. Числа от 0 до 1 отражают силу связи. Например, граф C влияет на граф A сильнее, чем A на C .
Реализация
Реализуем невзвешенный и неориентированный граф. Основной структурой класса является список списков Python. Каждый из них – это строка. Индексы в списке представляют собой столбцы. При создании объекта Graph необходимо указать количество узлов n, чтобы создать список списков. Затем мы можем получить доступ к соединению между узлами a и b с помощью self.graph[a][b] .
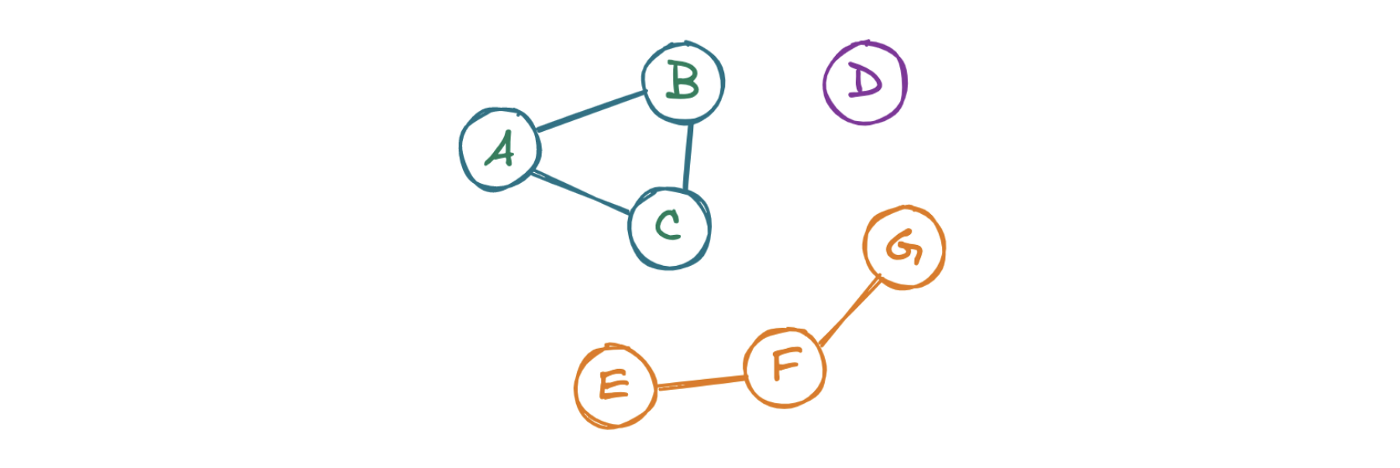
Чтобы ответить на вопрос LC 323: Количество связных компонентов, изучим каждый узел графа. Далее «посетим» соседние графы. Повторяем операцию до тех пор, пока не встретим только те узлы, которые уже были замечены программой. После этого проверим наличие в графе узлов, которые еще не были замечены. Если такие узлы присутствуют, то существует еще как минимум один кластер, поэтому нужно взять новый узел и повторить процесс.
def get_n_components(self, mat: List[List[int]]) -> int: """ Учитывая матрицу смежности, возвращает количество связанных компонентов """ q = [] unseen = [*range(len(mat))] answer = 0 while q or unseen: # Если все соседние узлы прошли через цикл, переходим к новому кластеру if not q: q.append(unseen.pop(0)) answer += 1 # Выбираем узел из текущего кластера focal = q.pop(0) i = 0 # Поиск связей во всех оставшихся узлах while i < len(unseen): node = unseen[i] # Если узел подключен к центру, добавляем его в очередь # чтобы перебрать его соседей # из невидимых узлов и избежать бесконечного цикла if mat[focal][node] == 1: q.append(node) unseen.remove(node) else: i += 1 return answer- Строки 5-8: Создаем очередь ( q ), список узлов ( unseen ) и количество компонентов ( answer ).
- Строка 10: Запускаем цикл while , который выполняем до тех пор, пока в очереди есть узлы, которые нужно обработать или узлы, которые не были замечены.
- Строки 13-15: Если очередь пуста, удаляем первый узел из непросмотренных и увеличиваем количество компонентов.
- Строки 18-19: Выбираем следующий доступный узел в очереди ( focal ).
- Строка 22: Запускаем цикл while , который выполняем до тех пор, пока не обработаем все оставшиеся узлы.
- Строка 23: Даем имя текущему узлу для оптимизации кода.
- Строки 28-30: Если текущий узел подключен к центру, добавляем его в очередь узлов текущего кластера. Удаляем его из списка тех узлов, которые могут находиться в невидимом кластере. Благодаря этому действию, мы избегаем бесконечного цикла.
- Строки 31-32: Если текущий узел не подключен к focal (центру), переходим к следующему узлу.
Заключение
Графы и деревья – основные структуры данных. Спектр их применения огромен. Например, графы используются там, где необходим алгоритм поиска решений. Реальный пример их использования – sea-of-nodes JIT-компилятора.
Деревья используются тогда, когда мы должны произвести быстрое добавление/удаление объекта с поиском по ключу. Например, в различных словарях и индексах БД (Баз данных). Кроме того, деревья являются неотъемлемой частью случайного леса – алгоритма машинного обучения.
В следующей части материала мы приступим к изучению хэш-таблиц.
Базовый и продвинутый курс «Алгоритмы и структуры данных» включает в себя:
- Живые вебинары 2 раза в неделю.
- 47 видеолекций и 150 практических заданий.
- Консультации с преподавателями курса.
Материалы по теме
Источник
Тема 3.7 Деревья
Определение: Деревом называется связный, ориентированный граф без петель и кратных ребер, не содержащий в себе циклов, удовлетворяющий следующим условиям:
- имеется в точности один узел, называемый корнем, в который не входит ни одно ребро,
- В каждый узел, кроме корня, входит ровно одно ребро,
- Из корня к каждому узлу идет путь ( который, как легко показать единственный).
Деревья являются простейшим видом связных графов. Любое дерево с n вершинами содержит n-1 ребер. Число различных деревьев, которые можно построить на n вершинах равно  Определение Дерево с одной выделенной вершиной называется корневым деревом. Определение Ориентированный граф, состоящий из нескольких деревьев, называется лесом. Определение: Пусть G=(Х, Г) – граф, являющийся лесом. Если дуга (v,w) принадлежит Г, то v называется отцом узла w, а w – сыном узла v. Определение: Если есть путь из v в w, то v называется предком узла w, а w – потомком узла v. Определение: Узел без потомков называется листом. Определение: Узел v и его потомки вместе образуют поддерево леса G, и узел v называется корнем этого поддерева. Определение:Глубина узла v в дереве – это длина пути из корня в v. Определение:Высота узла в дереве – это длина самого длинного пути из этого узла в какой-нибудь лист. Определение:Высотой дерева называется высота его корня. Пример
Определение Дерево с одной выделенной вершиной называется корневым деревом. Определение Ориентированный граф, состоящий из нескольких деревьев, называется лесом. Определение: Пусть G=(Х, Г) – граф, являющийся лесом. Если дуга (v,w) принадлежит Г, то v называется отцом узла w, а w – сыном узла v. Определение: Если есть путь из v в w, то v называется предком узла w, а w – потомком узла v. Определение: Узел без потомков называется листом. Определение: Узел v и его потомки вместе образуют поддерево леса G, и узел v называется корнем этого поддерева. Определение:Глубина узла v в дереве – это длина пути из корня в v. Определение:Высота узла в дереве – это длина самого длинного пути из этого узла в какой-нибудь лист. Определение:Высотой дерева называется высота его корня. Пример  Глубина узла b, в данном примере, = 1, а его высота = 2. Высота дерева = 3. Определение:Упорядоченным деревом называется дерево, в котором множество сыновей каждого узла упорядоченно. При изображении упорядоченного дерева, как правило, считается, что множество сыновей каждого узла упорядоченно слева направо. Определение:Бинарным деревом называется такое упорядоченное дерево, что
Глубина узла b, в данном примере, = 1, а его высота = 2. Высота дерева = 3. Определение:Упорядоченным деревом называется дерево, в котором множество сыновей каждого узла упорядоченно. При изображении упорядоченного дерева, как правило, считается, что множество сыновей каждого узла упорядоченно слева направо. Определение:Бинарным деревом называется такое упорядоченное дерево, что
- Каждый сын произвольного узла идентифицируется либо как левый сын, либо как правый сын.
- Каждый узел имеет не более одного левого и не более одного правого сына.
Обратите внимание, что бинарное дерево не является частным случаем дерева, это совершенно иное, хотя и тесно связанное понятие. Н апример: Указанные бинарные деревья различны между собой ( в первом случае корень имеет пустое правое поддерево, а во втором левое поддерево пусто), хотя как деревья они изоморфны, и мы можем рассматривать их как одно дерево. Определение: Бинарное дерево называется полным, если для некоторого целого числа K каждый узел, глубины меньшей k имеет как левого, так и правого сына, и каждый узел глубины k является листом. Полное дерево глубины k имеет
апример: Указанные бинарные деревья различны между собой ( в первом случае корень имеет пустое правое поддерево, а во втором левое поддерево пусто), хотя как деревья они изоморфны, и мы можем рассматривать их как одно дерево. Определение: Бинарное дерево называется полным, если для некоторого целого числа K каждый узел, глубины меньшей k имеет как левого, так и правого сына, и каждый узел глубины k является листом. Полное дерево глубины k имеет  узлов. Очень часто используются алгоритмы, которые проходят дерево (посещают каждый его узел) в некотором порядке. Известно несколько способов сделать это. Мы рассмотрим три широко известных способа: прохождение дерева в прямом порядке, обратном порядке и внутреннем. Будем считать, что Т – дерево с корнем r и сыновьями при k >=0. При k = 0 это дерево состоит из единственного узла r.
узлов. Очень часто используются алгоритмы, которые проходят дерево (посещают каждый его узел) в некотором порядке. Известно несколько способов сделать это. Мы рассмотрим три широко известных способа: прохождение дерева в прямом порядке, обратном порядке и внутреннем. Будем считать, что Т – дерево с корнем r и сыновьями при k >=0. При k = 0 это дерево состоит из единственного узла r.
Прохождение дерева т в прямом порядке определяется следующим алгоритмом:
- Посетить корень r
- Посетить слева на право поддеревья с корнями v1 . . . vk в указанной последовательности.
П ример Прохождение дерева Т в обратном порядке определяется следующим алгоритмом: Посетить в обратном порядке поддеревья с корнями v1 . . . vk в указанной последовательности. Посетить корень r П
ример Прохождение дерева Т в обратном порядке определяется следующим алгоритмом: Посетить в обратном порядке поддеревья с корнями v1 . . . vk в указанной последовательности. Посетить корень r П ример Прохождение дерева Т во внутреннем порядке определяется следующим алгоритмом: Посетить во внутреннем порядке левое поддерево корня (если оно существует). Посетить корень Посетить во внутреннем порядке правое поддерево корня (если оно существует). Пример П
ример Прохождение дерева Т во внутреннем порядке определяется следующим алгоритмом: Посетить во внутреннем порядке левое поддерево корня (если оно существует). Посетить корень Посетить во внутреннем порядке правое поддерево корня (если оно существует). Пример П режде чем дать описание одного из этих алгоритмов на некотором формальном языке программирования, поговорим о способах задания и хранения деревьев и бинарных деревьев. Очень многие объекты представимы в виде деревьев. Например: сложная нумерация глав лекций – типичный информационный объект, сохраняемый и обрабатываемый в виде дерева. 1. Теория графов 1.1. Основные определения теории графа 1.2. Операции над графами 1.2.1. Одноместные операции 1.2.2. Двуместные операции 1.3. Отношения 1.3.1. Отношение порядка 1.3.2. Отношение эквивалентности
режде чем дать описание одного из этих алгоритмов на некотором формальном языке программирования, поговорим о способах задания и хранения деревьев и бинарных деревьев. Очень многие объекты представимы в виде деревьев. Например: сложная нумерация глав лекций – типичный информационный объект, сохраняемый и обрабатываемый в виде дерева. 1. Теория графов 1.1. Основные определения теории графа 1.2. Операции над графами 1.2.1. Одноместные операции 1.2.2. Двуместные операции 1.3. Отношения 1.3.1. Отношение порядка 1.3.2. Отношение эквивалентности
- Числовые характеристики графа
1.5. Понятие обхода графа 1.5.1. Эйлеров цикл 1.5.2. Гамильтонов цикл
- Изоморфизм графов
- Понятие дерева
- Бинарные деревья
- Алгоритмы нумерации узлов графа
- Нумерация в прямом порядке
- Нумерация в обратном порядке
- Нумерация во внутреннем порядке
Подобная система нумерации часто называется десятичной системой обозначения Дьюи. В ведем интуитивное понятие линейного списка. Мы еще не раз будем говорить об этом способе представления и хранения информации. Одним из распространенных способов хранения деревьев является массив списков. Это одномерный массив, размерностиn – количество узлов дерева. Каждый элемент этого массива – это упорядоченный или неупорядоченный список сыновей этого отца. Например Бинарные деревья, как правило, хранятся посредством двух массивов ЛЕВЫЙСЫН и ПРАВЫЙСЫН, где номер элемента массива – это номер узла, а значение этого элемента – номер левого или правого узла – сына. Если элемент - сын отсутствует, то значение равно 0. Пример Теперь опишем алгоритм нумерации узлов двоичного дерева в соответствии с внутренним порядком. Для этого будем пользоваться неким подобием языка программирования, специально предназначенного для прозрачного и понятного описания алгоритмов. Вход: Двоичное дерево, представленное массивами ЛЕВЫЙСЫН и ПРАВЫЙСЫН. Выход: Массив, называемый НОМЕР, такой, что НОМЕР[i] – номер i – того узла во внутреннем порядке. Метод: Будем использовать глобальную переменную СЧЕТ, значение которой – номер очередного узла в соответствии с внутренним порядком. Начальное значение переменной СЧЕТ = 1. Программа выглядит так: begin СЧЕТ 1 ВНУТРПОРЯДОК(КОРЕНЬ) EndProcedure ВНУТРПОРЯДОК(УЗЕЛ) Begin 1. if ЛЕВЫЙСЫН[УЗЕЛ]0 then ВНУТРПОРЯДОК(ЛЕВЫЙСЫН[УЗЕЛ]); 2. НОМЕР[УЗЕЛ] СЧЕТ;
ведем интуитивное понятие линейного списка. Мы еще не раз будем говорить об этом способе представления и хранения информации. Одним из распространенных способов хранения деревьев является массив списков. Это одномерный массив, размерностиn – количество узлов дерева. Каждый элемент этого массива – это упорядоченный или неупорядоченный список сыновей этого отца. Например Бинарные деревья, как правило, хранятся посредством двух массивов ЛЕВЫЙСЫН и ПРАВЫЙСЫН, где номер элемента массива – это номер узла, а значение этого элемента – номер левого или правого узла – сына. Если элемент - сын отсутствует, то значение равно 0. Пример Теперь опишем алгоритм нумерации узлов двоичного дерева в соответствии с внутренним порядком. Для этого будем пользоваться неким подобием языка программирования, специально предназначенного для прозрачного и понятного описания алгоритмов. Вход: Двоичное дерево, представленное массивами ЛЕВЫЙСЫН и ПРАВЫЙСЫН. Выход: Массив, называемый НОМЕР, такой, что НОМЕР[i] – номер i – того узла во внутреннем порядке. Метод: Будем использовать глобальную переменную СЧЕТ, значение которой – номер очередного узла в соответствии с внутренним порядком. Начальное значение переменной СЧЕТ = 1. Программа выглядит так: begin СЧЕТ 1 ВНУТРПОРЯДОК(КОРЕНЬ) EndProcedure ВНУТРПОРЯДОК(УЗЕЛ) Begin 1. if ЛЕВЫЙСЫН[УЗЕЛ]0 then ВНУТРПОРЯДОК(ЛЕВЫЙСЫН[УЗЕЛ]); 2. НОМЕР[УЗЕЛ] СЧЕТ;
- СЧЕТ СЧЕТ+1
4. if ПРАВЫЙСЫН[УЗЕЛ]0 then ВНУТРПОРЯДОК(ПРАВЫЙСЫН[УЗЕЛ]); End Такая процедура, которая явно или неявно вызывает сама себя, называется рекурсивной. Применение рекурсии часто дает возможность давать более прозрачное и сжатое описание алгоритма, чем это же можно было бы сделать, не используя рекурсию. Если бы приведенный алгоритм не был записан рекурсивно, надо было бы строить явный механизм для прохождения дерева. Двигаться вниз по дереву нетрудно, но чтобы обеспечить возможность вернуться к предку, надо запомнить всех предков в стеке, а операторы работы со стеком усложнили бы алгоритм, лишив его наглядности.
Источник