- Методы программирования
- Теория
- Обход дерева в глубину
- Обход дерева в ширину
- Двоичные деревья поиска
- Сбалансированные деревья
- Формулировка задания
- а. Реализация простых двоичных деревьев поиска
- Примеры
- b. ** Реализация сбалансированных деревьев
- c. Реализация префиксного, инфиксного и постфиксного обходов двоичного дерева
- 2. Двоичные деревья
- Inf : Elem;
- 3. Основные операции с двоичными деревьями
Методы программирования
Задание состоит из трех частей, первая и третья обязательны для выполнения, вторая выполняется по желанию студента. Срок сдачи задания — 17 октября.
Теория
Двоичное дерево задается следующей структурой:
typedef struct _t int data; /* данные в узле */
struct _t *left, *right; /* указатели на левого и правого сыновей */
> t;
t *root; /* корень дерева */
Таким образом, каждый элемент дерева содержит некоторые данные и два указателя на потомков (на левого сына и на правого). Сам узел будем называть отцом этих двух потомков. Определение дерева требует, чтобы у каждого узла, кроме корня, был ровно один отец. Указатель на корень дерева хранится в переменной root , она равна нулю, если дерево пусто.
Левым и правым поддеревьями узла t ( t != 0 ) будем называть деревья (возможно, пустые), корнями которых являются соответственно t->left и t->right .
Основные операции на деревьях: поиск элемента, добавление элемента, удаление элемента. Для поиска элемента в произвольном бинарном дереве необходимо обойти все элементы этого дерева. Существует два основных способа обхода дерева: в глубину и в ширину.
Обход дерева в глубину
Обход в глубину производится рекурсивно либо с использованием стека. В обоих случаях можно обходить узлы дерева в различной последовательности. Обход начинается от корня. Выделяют три наиболее важных порядка обхода в глубину:
- префиксный (прямой) обход — сначала обрабатывается текущий узел, затем левое и правое поддеревья;
- инфиксный (симметричный) обход — сначала обрабатывается левое поддерево текущего узла, затем корень, затем правое поддерево;
- постфиксный (обратный) обход — сначала обрабатываются левое и правое поддеревья текущего узла, затем сам узел.
В качестве примера рассмотрим следующее дерево:
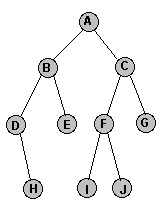
- префиксный обход: A, B, D, H, E, C, F, I, J, G
- инфиксный обход: D, H, B, E, A, I, F, J, C, G
- постфиксный обход: H, D, E, B, I, J, F, G, C, A
Запишем в качестве примера рекурсивную процедуру, выводящую на экран узлы дерева в порядке префиксного обхода.
void prefix(t *curr)
if (!curr)
return;
printf(«%d «, curr->data);
prefix(curr->left);
prefix(curr->right);
>
Обход дерева в ширину
Обход в ширину производится с помощью очереди. Первоначально в очередь помещается корень, затем, пока очередь не пуста, выполняются следующие действия:
- Из очереди выталкивается очередной узел;
- Этот узел обрабатывается;
- В очередь добавляются оба сына этого узла.
Узлы дерева на рисунке перечисляются в порядке обхода в ширину следующим образом: A, B, C, D, E, F, G, H, I, J. Заметим, что перечисление узлов происходит в порядке удаления от корня, что делает поиск в ширину удобным, например, для поиска узла дерева со значением k , наиболее близкого к корню, и т.д.
Приведем пример процедуры, которая выводит на экран узлы дерева в порядке обхода в ширину. Считаем, что определены три функции:
void add(t *elem); /* добавляет в конец очереди элемент elem */
t *del(); /* удаляет из очереди первый элемент и возвращает указатель на него */
int empty(); /* возвращает 1, если очередь пуста, и 0 в противном случае */
Тогда процедура обхода будет иметь следующий вид:
void width(t *root)
if (!root)
return;
add(root);
while (!empty()) t *curr = del();
printf(«%d «, curr->data);
if (curr->left)
add(curr->left);
if (curr->right)
add(curr->right);
>
>
Двоичные деревья поиска
Для поиска узла в таком дереве можно использовать как рекурсивную функцию, так и простой цикл. Ниже приведен пример функции, которая ищет узел со значением k в двоичном дереве поиска с корнем root . Этот код весьма напоминает обычный бинарный поиск:
t *search(t *root, int k)
t *curr = root;
while (curr) if (k == curr->data)
return (curr);
if (k < curr->data)
curr = curr->left;
else
curr = curr->right;
>
return (0);
>
Добавление узла в двоичное дерево поиска напоминает добавление элемента в середину связанного списка: выполняется проход по дереву с запоминанием указателя на узел, предшествующий текущему, и добавление узла к предыдущему, как только текущий указатель станет равным нулю. Необходимо отдельно обработать случай пустого дерева.
Удаление узла из двоичного дерева поиска является менее тривиальной операцией: необходимо поддерживать выполнение условия расположения элементов («слева меньше, справа больше»). Одним из возможных способов является следующий:
- если у удаляемого узла нет сыновей, его удаление не представляет проблемы (освобождаем память и зануляем указатель на нее у его отца);
- если у удаляемого узла есть ровно один сын, удаляем узел, а указатель на него у отца заменяем указателем на этого сына;
- если у удаляемого узла есть оба сына, ищем в правом поддереве узел с минимальным значением (у него по определению будет отсутствовать левый сын) и ставим этот узел на место удаляемого, аккуратно поменяв все необходимые указатели.
Сбалансированные деревья
При работе с двоичными деревьями поиска возможен случай, когда дерево по сути примет вид линейного связанного списка (например, если элементы подавались на вход в порядке возрастания). В таком случае поиск элемента в дереве будет занимать линейное время. Одним из способов предотвращения подобной ситуации является балансировка дерева по мере добавления элементов.
Сбалансированным деревом (AVL-деревом) называется двоичное дерево поиска, удовлетворяющее следующему условию: для любого узла глубина левого поддерева отличается от глубины правого поддерева не более чем на 1. В сбалансированном дереве поиск элемента выполняется за время O(log2N), где N — количество узлов (Адельсон-Вельский, Ландис, 1962). Алгоритм построения сбалансированных деревьев можно найти в сети и в литературе (Вирт, Кнут, . ), поэтому подробное описание его здесь не приводится.
Формулировка задания
а. Реализация простых двоичных деревьев поиска
Во входном файле input.txt в первой строке находится количество записей N , в следующих N строках находятся записи вида имя значение , причем имена могут повторяться. В файл output.txt выдать итоговые значения всех переменных в алфавитном порядке. Хранение записей организовать в виде двоичного дерева поиска.
Примеры
b. ** Реализация сбалансированных деревьев
Задание аналогично предыдущему, но требуется поддерживать дерево сбалансированным. Задание не является обязательным.
c. Реализация префиксного, инфиксного и постфиксного обходов двоичного дерева
Необходимо реализовать функции обхода дерева в порядке префиксного, инфиксного и постфиксного обходов. Дерево задается произвольным образом.
Источник
2. Двоичные деревья

Особенно важную роль играют упорядоченные деревья второй степени. Их называют двоичными или бинарными деревьями. Определим двоичное дерево как конечное множество элементов – узлов, которое или пусто, или состоит из корня и двух непересекающихся двоичных деревьев, называемых левым и правым поддеревьями данного корня. Заметим, что двоичное дерево не является частным случаем дерева, хотя эти два понятия связаны между собой. Основные отличия между ними: 1) Дерево никогда не бывает пустым, т.е. имеет, по меньшей мере, один узел, а двоичное дерево может быть пустым. 2) Двоичное дерево — упорядоченное дерево, т.е. делается различие между левым и правым поддеревом, даже в том случае, когда узел имеет лишь одного потомка. В графическом изображении дерева (рисунок 4) “наклон” ветвей важен. Реализация таких рекурсивных структур, как двоичные деревья, приводит к использованию ссылок (указателей). Ссылки на пустые деревья будут обозначаться nil. Из определения двоичных деревьев следует естественный способ их описания ( и представления в компьютере ) : для этого достаточно иметь две связи L и R в каждом узле и переменную связи T, которая является указателем на это дерево. Если дерево пусто, то T = nil ; в противном случае T — адрес корня этого дерева, а L и R — указатели соответственно на левое и правое поддеревья этого корня. На языке Паскаль узлы бинарного дерева описываются как записи с одним или несколькими информационными полями и двумя полями – указателями. Если Elem — тип информационной части узлов дерева, то компоненты дерева ( узел и ссылка на узел ) имеют такие типы: type Tree = ^Node; < указатель на узел >Node = record < узел дерева >
Inf : Elem;
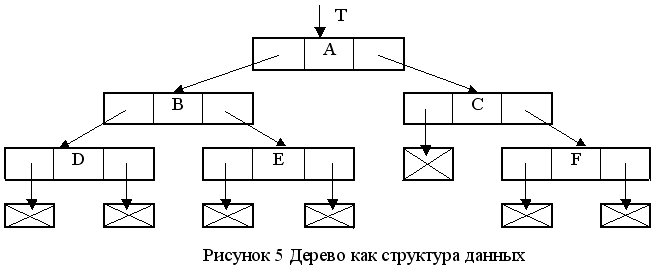
L, R : Tree end; Таким образом, дерево на рисунке 4 б) можно представить так, как на рисунке 5. Далее будем иметь дело только с двоичными деревьями, поэтому термин “дерево” будет означать двоичное дерево.
3. Основные операции с двоичными деревьями
3.1. Обход дерева Наиболее распространенная задача обработки древовидных структур – выполнение некоторой определенной операции над каждым элементом дерева. При этом происходит “посещение” всех вершин, т.е. обход дерева. При обходе каждый узел проходится, по меньшей мере, один раз, а, вообще говоря, три раза. Полное прохождение дерева дает линейную расстановку узлов. Если, обходя дерево, обрабатывать вершины при первой встрече, то ( см. рис. 4 б) ) получим последовательность A, B, D, E, C, F ; если при второй встрече, то получим D, B, E, A, C, F ; если при третьей встрече, то получим D, E, B, F, C, A. Эти три способа обхода называются соответственно – обходом сверху вниз (в прямом порядке, префиксным обходом, preorder); – обходом слева направо (в обратном порядке, инфиксным обходом, inorder); – обходом снизу вверх (в концевом порядке, постфиксным обходом, postorder или endorder). Способы прохождения деревьев определяются рекурсивно. Если дерево пусто, то никаких действий не выполняется, в противном случае обход выполняется в три этапа
| Префиксный обход | Инфиксный обход |
| Обработать узел | Пройти левое поддерево |
| Пройти левое поддерево | Обработать узел |
| Пройти правое поддерево | Пройти правое поддерево |
Постфиксный обход Пройти левое поддерево Пройти правое поддерево Обработать узел Обход слева направо (инфиксный обход) часто используется при сортировке (см. раздел 4 ). Префиксный и постфиксный способы обхода дерева играют важную роль при анализе текстов на языках программирования. Все три метода легко представляются как рекурсивные процедуры. Пример 3.1. Префиксный обход дерева : procedure PreOrder(T : Tree); begin if T <> nil then begin < операция обработки узла дерева , например, writeln( T^.inf );> PreOrder (T^.L); PreOrder (T^.R) end end; PreOrder > Пример 3.2. Инфиксный обход дерева : procedure InOrder(T : Tree); begin if T <> nil then begin InOrder (T^.L); < операция обработки узла дерева , например, writeln( T^.inf );> InOrder (T^.R) end end; Пример 3.3. Постфиксный обход дерева : procedure PostOrder(T : Tree); begin if T <> nil then begin PostOrder (T^.L); PostOrder (T^.R) < операция обработки узла дерева , например, writeln( T^.inf );> end end; PostOrder > Замечание. Ссылка T передается как параметр — значение, т.е. в процедуре используется ее локальная копия. При реализации нерекурсивных процедур обхода дерева обычно используют вспомогательный стек и операции работы с ним: – очистить стек (создать пустой стек); – проверить, является ли стек пустым; – добавить в стек элемент; – извлечь элемент из стека. В стеке запоминаются ссылки на вершины (поддеревья), обработка которых временно откладывается. Пример 3.4. Описать нерекурсивную процедуру префиксного обхода дерева. Описание вспомогательного стека : type Stack = ^Rec; Rec = record
Источник