- 10 типов структур данных, которые нужно знать + видео и упражнения
- Связные списки
- Упражнения от freeCodeCamp
- Стеки
- Упражнения от freeCodeCamp
- Очереди
- Упражнения от freeCodeCamp
- Множества
- Упражнения от freeCodeCamp
- Map
- Деревья
- Зачем нужны деревья
- Части дерева
- Другие понятия
- Виды деревьев
- Обход дерева
- Где используются
10 типов структур данных, которые нужно знать + видео и упражнения
Екатерина Малахова, редактор-фрилансер, специально для блога Нетологии адаптировала статью Beau Carnes об основных типах структур данных.
«Плохие программисты думают о коде. Хорошие программисты думают о структурах данных и их взаимосвязях», — Линус Торвальдс, создатель Linux.
Структуры данных играют важную роль в процессе разработки ПО, а еще по ним часто задают вопросы на собеседованиях для разработчиков. Хорошая новость в том, что по сути они представляют собой всего лишь специальные форматы для организации и хранения данных.
В этой статье я покажу вам 10 самых распространенных структур данных. Для каждой из них приведены видео и примеры их реализации на JavaScript. Чтобы вы смогли попрактиковаться, я также добавил несколько упражнений из бета-версии новой учебной программы freeCodeCamp.
Обратите внимание, что некоторые структуры данных включают временную сложность в нотации «большого О». Это относится не ко всем из них, так как иногда временная сложность зависит от реализации. Если вы хотите узнать больше о нотации «большого О», посмотрите это видео от Briana Marie.
В статье я привожу примеры реализации этих структур данных на JavaScript: они также пригодятся, если вы используете низкоуровневый язык вроде С. В многие высокоуровневые языки, включая JavaScript, уже встроены реализации большинства структур данных, о которых пойдет речь. Тем не менее, такие знания станут серьезным преимуществом при поиске работы и пригодятся при написании высокопроизводительного кода.
Связные списки
Связный список — одна из базовых структур данных. Ее часто сравнивают с массивом, так как многие другие структуры можно реализовать с помощью либо массива, либо связного списка. У этих двух типов есть преимущества и недостатки.
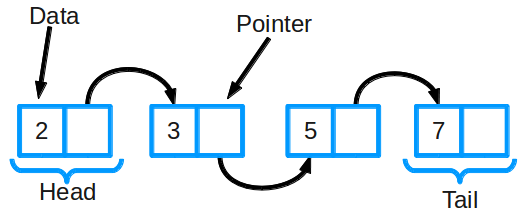
Так устроен связный список
Связный список состоит из группы узлов, которые вместе образуют последовательность. Каждый узел содержит две вещи: фактические данные, которые в нем хранятся (это могут быть данные любого типа) и указатель (или ссылку) на следующий узел в последовательности. Также существуют двусвязные списки: в них у каждого узла есть указатель и на следующий, и на предыдущий элемент в списке.
Основные операции в связном списке включают добавление, удаление и поиск элемента в списке.
Временная сложность связного списка ╔═══════════╦═════════════════╦═══════════════╗ ║ Алгоритм ║Среднее значение ║ Худший случай ║ ╠═══════════╬═════════════════╬═══════════════╣ ║ Space ║ O(n) ║ O(n) ║ ║ Search ║ O(n) ║ O(n) ║ ║ Insert ║ O(1) ║ O(1) ║ ║ Delete ║ O(1) ║ O(1) ║ ╚═══════════╩═════════════════╩═══════════════╝ Упражнения от freeCodeCamp
Стеки
Стек — это базовая структура данных, которая позволяет добавлять или удалять элементы только в её начале. Она похожа на стопку книг: если вы хотите взглянуть на книгу в середине стека, сперва придется убрать лежащие сверху.
Стек организован по принципу LIFO (Last In First Out, «последним пришёл — первым вышел») . Это значит, что последний элемент, который вы добавили в стек, первым выйдет из него.

Так устроен стек
В стеках можно выполнять три операции: добавление элемента (push), удаление элемента (pop) и отображение содержимого стека (pip).
Временная сложность стека ╔═══════════╦═════════════════╦═══════════════╗ ║ Алгоритм ║Среднее значение ║ Худший случай ║ ╠═══════════╬═════════════════╬═══════════════╣ ║ Space ║ O(n) ║ O(n) ║ ║ Search ║ O(n) ║ O(n) ║ ║ Insert ║ O(1) ║ O(1) ║ ║ Delete ║ O(1) ║ O(1) ║ ╚═══════════╩═════════════════╩═══════════════╝ Упражнения от freeCodeCamp
Очереди
Эту структуру можно представить как очередь в продуктовом магазине. Первым обслуживают того, кто пришёл в самом начале — всё как в жизни.

Так устроена очередь
Очередь устроена по принципу FIFO (First In First Out, «первый пришёл — первый вышел»). Это значит, что удалить элемент можно только после того, как были убраны все ранее добавленные элементы.
Очередь позволяет выполнять две основных операции: добавлять элементы в конец очереди (enqueue) и удалять первый элемент (dequeue).
Временная сложность очереди ╔═══════════╦═════════════════╦═══════════════╗ ║ Алгоритм ║Среднее значение ║ Худший случай ║ ╠═══════════╬═════════════════╬═══════════════╣ ║ Space ║ O(n) ║ O(n) ║ ║ Search ║ O(n) ║ O(n) ║ ║ Insert ║ O(1) ║ O(1) ║ ║ Delete ║ O(1) ║ O(1) ║ ╚═══════════╩═════════════════╩═══════════════╝ Упражнения от freeCodeCamp
Множества
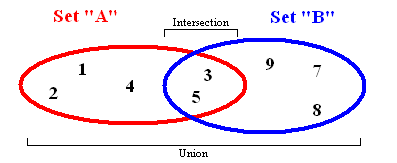
Так выглядит множество
Множество хранит значения данных без определенного порядка, не повторяя их. Оно позволяет не только добавлять и удалять элементы: есть ещё несколько важных функций, которые можно применять к двум множествам сразу.
- Объединение комбинирует все элементы из двух разных множеств, превращая их в одно (без дубликатов).
- Пересечение анализирует два множества и создает еще одно из тех элементов, которые присутствуют в обоих изначальных множествах.
- Разность выводит список элементов, которые есть в одном множестве, но отсутствуют в другом.
- Подмножество выдает булево значение, которое показывает, включает ли одно множество все элементы другого множества.
Упражнения от freeCodeCamp
- Create a Set Class
- Remove from a Set
- Size of the Set
- Perform a Union on Two Sets
- Perform an Intersection on Two Sets of Data
- Perform a Difference on Two Sets of Data
- Perform a Subset Check on Two Sets of Data
- Create and Add to Sets in ES6
- Remove items from a set in ES6
- Use .has and .size on an ES6 Set
- Use Spread and Notes for ES5 Set() Integration
Map
Map — это структура, которая хранит данные в парах ключ/значение, где каждый ключ уникален. Иногда её также называют ассоциативным массивом или словарём. Map часто используют для быстрого поиска данных. Она позволяет делать следующие вещи:
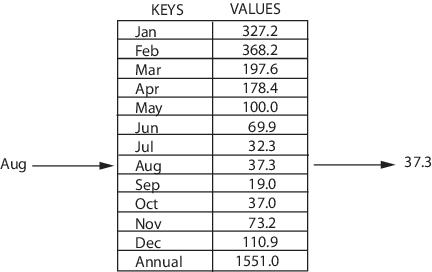
- добавлять пары в коллекцию;
- удалять пары из коллекции;
- изменять существующей пары;
- искать значение, связанное с определенным ключом.
Так устроена структура map
Источник
Деревья
Дерево — это нелинейная иерархическая структура данных. Она состоит из узлов и ребер, которые соединяют узлы.

Зачем нужны деревья
Другие структуры данных, например, массивы, списки, стеки и очереди, линейные. Это значит, что данные в них хранятся последовательно. Когда мы выполняем любую операцию в линейной структуре данных, временная сложность растет с увеличением размера данных. В современном мире это не очень круто.
Разные древовидные структуры позволяют быстрее и легче получать доступ к данным, поскольку дерево — структура нелинейная.
Части дерева
- Узел — это объект, в котором есть ключ или значение и указатели на дочерние узлы.
Узлы, у которых нет дочерних узлов, называют листами или терминальными узлами.
Узлы, у которых есть хотя бы один дочерний узел, называются внутренними. - Ребро связывает два узла.
- Корень — это самый верхний узел дерева. Его ещё иногда называют корневым узлом.
.png)
Другие понятия
- Высота узла — это максимальная длина пути от этого узла к самому нижнему узлу (листу).
- Глубина вложенности узла — длина пути от корня до этого узла.
- Высота дерева — это высота корневого узла или глубина самого глубокого узла.
- Степень узла — это общее количество ребер, которые соединены с этим узлом.

- Лес — множество непересекающихся деревьев. Например, если «срезать» корень, получится лес.

Виды деревьев
Обход дерева
Чтобы выполнить какую-либо операцию с деревом, нужно добраться до определенного узла. Для этого и существуют алгоритмы обхода дерева. Они помогают «дойти» до необходимого узла.
Где используются
- Деревья двоичного поиска помогают быстро проверить наличие элемента в наборе.
- Куча — это тоже своеобразное дерево. Кучи используют в алгоритме сортировки кучей.
- Префиксные деревья используются в маршрутизаторах, они хранят информацию о маршруте.
- Большинство популярных баз данных основаны на B-деревья и T-деревья.
- Компиляторы используют абстрактное синтаксическое дерево, чтобы находить синтаксические ошибки в ваших программах.
СodeСhick.io — простой и эффективный способ изучения программирования.
2023 © ООО «Алгоритмы и практика»
Источник