2.4.3. Кодовые деревья
Рассмотрим реализацию алгоритма Хаффмана с использованием кодовых деревьев.
Кодовое дерево – это бинарное дерево, у которого: – листья помечены символами, для которых разрабатывается кодировка;
– узлы (в том числе корень) помечены суммой вероятностей появления всех символов, соответствующих листьям поддерева, корнем которого является соответствующий узел.
Существует два подхода к построению кодового дерева: от корня к листьям и от листьев к корню. Рассмотрим первый подход в виде процедуры Паскаля. Входными параметрами этой процедуры являются массив используемых символов, отсортированный в порядке убывания вероятности появления символов (вначале идут символы с максимальными вероятностями, а в конце – с минимальными), а также указатель на создаваемое кодовое дерево, описание которого идентично описанию бинарного дерева в виде списков (см. 1.3.4.4), за исключением того, что поле Data здесь принимает символьный тип.
procedure CreateCodeTable(UseSimbol: TUseSimbol;
Current: PTree; SimbolCount: integer; begin
Current^.Left := nil; Current^.Right := nil;
Current^.Left^.Data := UseSimbol[SimbolCount]; Current^.Left^.Left := nil; Current^.Left^.Right := nil; new(Current^.Right); Current := Current^.Right;
Current^.Left := nil; Current^.Right := nil; SimbolCount := SimbolCount + 1; end;
Пример построения кодового дерева приведен на рис. 39.
Исходная последовательность символов: aabbbbbbbbcccdeeeee
Исходный объем: 20 байт (160 бит) Вероятности появления

Оптимальный префиксный код
Сжатый код: 111011100000000011011011011111010101010 Объем сжатого кода: 37 бит ( ~ 24,5% исходного)
Рис. 39. Создание оптимальных префиксных кодов
Созданное кодовое дерево может быть использовано для кодирования и декодирования текста. Как осуществляется кодирование уже говорилось выше. Теперь рассмотрим процесс декодирования. Алгоритм распаковки кода можно сформулировать следующим образом:
procedure DecodeHuffman(CodeTree: PTree; var ResultStr:
CurrentSimbol: integer; FlagOfEnd: boolean;
FlagOfEnd := false; CurrentSimbol := 1; Current := CodeTree; while not FlagOfEnd do begin while (Current^.Left <> nil) and (Current^.Right <> nil) and
not FlagOfEnd do begin CurrentBit := ReadBynary(FlagOfEnd); if CurrentBit = 0 then Current := Current^.Left
else Current := Current^.Right; end;
ResultStr[CurrentSimbol] := Current^.Data; CurrentSimbol := CurrentSimbol + 1; Current := CodeTree; end; end;
В приведенном алгоритме используется функция ReadBinary, которая читает битовую последовательность и возвращает целое значение 0, если текущий бит равен 0 и возвращает 1, если бит равен 1. Кроме того, она формирует флаг конца битовой последовательности: он принимает значение true, если последовательность исчерпана.
Для осуществления распаковки необходимо иметь кодовое дерево, которое приходится хранить вместе со сжатыми данными. Это приводит к некоторому незначительному увеличению объема сжатых данных. Используются самые различные форматы, в которых хранят это дерево. Здесь следует отметить, что узлы кодового дерева являются пустыми. Иногда хранят не само дерево, а исходные данные для его формирования, т. е. сведения о вероятностях появления символов (или их количествах). При этом процесс декодирования предваряется построением нового кодового дерева, которое будет таким же, как и при кодировании.
Источник
§10. Сжатие на основе статистических свойств данных и неравномерные коды
Методы такого сжатия изучаются в специальном разделе теории информации (подразделе теоретической информатики), который называется теорией экономного или эффективного кодирования. Экономное кодирование основано на использовании систем кодирования с переменной длиной кодового слова.
В системах равномерного кодирования, как нам уже известно, каждому символу алфавита A=ai>, i=1,…,n, ставится в соответствие кодовое слово с фиксированным числом разрядов. Например, в случае рассмотренного нами посимвольного двоичного кодирования каждому знаку алфавита A соответствует 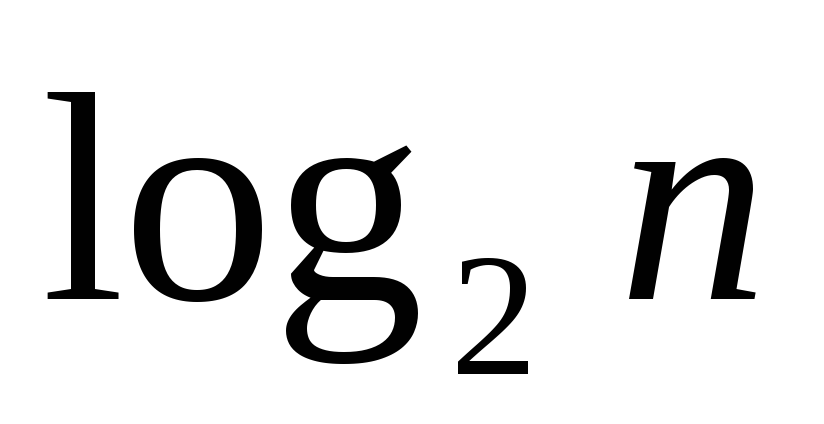 или
или бит (двоичных разрядов). Однако давно известны и системы кодирования, в которых длина кодового слова непостоянна, например, код Морзе.
бит (двоичных разрядов). Однако давно известны и системы кодирования, в которых длина кодового слова непостоянна, например, код Морзе.
При использовании таких неравномерных кодов сразу же возникает проблема выделения кодовых слов из закодированной последовательности символов для однозначного декодирования сообщений. Например, в коде Морзе для этого предусмотрена специальная кодовая комбинация-разделитель (тройная пауза). Однако более экономным является использование при кодировании так называемого условия префиксности кода (условия Фано): никакое кодовое слово не должно являться началом другого кодового слова. Выполнение этого условия гарантирует однозначное разбиение последовательности символов на кодовые слова без применения разделителей: очередное кодовое слово получается последовательным считыванием символов до тех пор, пока получающаяся комбинация не совпадет с одним из кодовых слов.
Пусть, например, A=. Закодируем символы данного алфавита наборами двоичных знаков следующим образом:
Нетрудно видеть, что перед нами – префиксный код. Теперь появляется возможность однозначного декодирования любого сообщения. Например, последовательность 1110110111110100000000110011111110101 допускает лишь одно разбиение на кодовые слова 1110 110 111110 1000 00 00 01 1001 111111 01 01 и соответствует сообщению 65820013911.
Префиксный код называется примитивным, если его нельзя сократить, т.е. при вычеркивании любого знака хотя бы в одном кодовом слове код перестает быть префиксным. Префиксный код, приведенный выше в качестве примера, является примитивным.
§11. Двоичное кодирование и бинарные деревья
Двоичное кодирование удобно представлять в виде бинарного кодового дерева. Если условиться сопоставлять любой левой ветви бинарного дерева нуль, а любой правой – единицу, то каждой вершине дерева будет однозначно соответствовать некоторый набор двоичных знаков, показывающий, в какой последовательности нужно сворачивать налево и направо, добираясь до этой вершины из корня дерева. Любой из таких наборов может быть выбран в качестве кодового слова. Например, рассмотренному выше коду соответствует дерево, приведенное на рис. 1.4.

Пример кодового дерева примитивного префиксного кода
Очевидно, что условие префиксности кода в терминологии бинарных деревьев можно сформулировать следующим образом: никакие две вершины, изображающие некоторую пару кодовых слов, не лежат на одном пути из корня кодового дерева.
Процесс двоичного кодирования можно интерпретировать следующим образом. На каждом шаге движения по кодовому дереву, начиная от корня, происходит выбор одного из двух поддеревьев: правого и левого. Это соответствует разбиению множества знаков алфавита на два подмножества – правое и левое – с присвоением им очередных двоичных знаков (единицы и нуля). Так, в рассмотренном примере множество было разбито на два подмножества и . При дальнейшем движении вправо множество в свою очередь было разбито на два подмножества и , а при движении влево множество было разбито на два подмножества и и т.д. до тех пор, пока во всех подмножествах не осталось по одному элементу.
Таким образом, двоичные коды, соответствующие вершинам кодового дерева, характеризуют «историю» последовательного разбиения исходного множества знаков на правые и левые подмножества.
Источник