Критерии качества для построения решающих деревьев
На предыдущем занятии мы с вами познакомились с общей идеей логических методов. Здесь же продолжим эту тему и подробнее поговорим о бинарных решающих деревьях. Приведу пример такого дерева из предыдущего занятия:
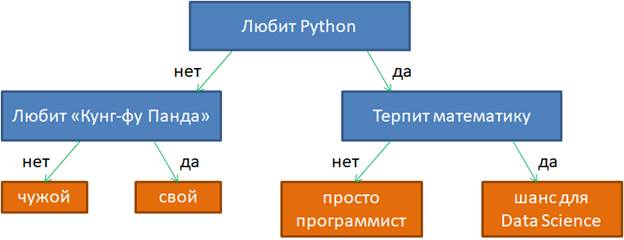
Фактически это связный ациклический граф, в котором есть корень, внутренние вершины и листы (вершины без потомков). Причем, каждая внутренняя вершина имеет ровно два ответвления, соответствующие стрелкам «да» и «нет». Именно поэтому дерево с такой структурой называют бинарным.
Если у нас есть уже построенное дерево по множеству данных, то логический вывод делается очень просто. Предположим, мы классифицируем вектор
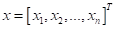
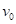
с n признаками. Тогда, начиная с корневой вершины , проверяем предикат:
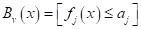
То есть, мы смотрим на j-й признак для вектора 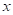 и сравниваем его с порогом
и сравниваем его с порогом 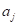 . Если условие выполняется, идем по стрелке с отметкой 1, иначе – по стрелке с отметкой 0.
. Если условие выполняется, идем по стрелке с отметкой 1, иначе – по стрелке с отметкой 0.
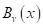
В следующей промежуточной вершине повторяем этот процесс и с помощью предиката проверяем значение другого j-го признака (или того же самого). В зависимости от ответа, переходим или по стрелке 1, или по стрелке 0.
Как только дошли до листа, относим вектор к тому классу, который прописан в текущем листе. Процесс логического вывода на этом завершается. Именно поэтому листовые вершины еще называют терминальными.
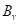
Однако, чтобы проделать такой вывод, мы с вами должны знать структуру дерева, набор предикатов для каждой промежуточной вершины и иметь правильные значения в листовых вершинах. Листы дерева, как правило, хранят определенные числа. Они могут означать или номер (метку) класса, или константное значение функции при решении задач регрессии. Но пока будем полагать, что в них записаны метки класса.
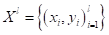
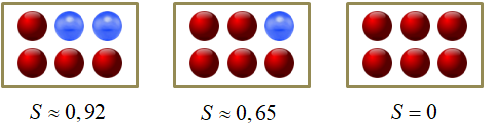
Итак, главный вопрос, как построить бинарное решающее дерево по множеству данных обучающей выборки ? Чтобы лучше понимать этот процесс, давайте возьмем очень простой пример разбиения последовательности красных и синих шаров, собственно, на красные и синие:

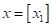
Здесь вектор состоит из одной компоненты и представляет собой число – номер позиции шара. Это единственный признак, по которому можно выполнять разбиение данной последовательности. В каждой промежуточной вершине бинарного решающего дерева будет использован предикат вида:
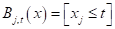
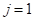
И, так как признак всего один, то . Остается найти только нужные пороги t.
Если бы разбиение делал я сам, то предложил бы следующее решающее дерево:
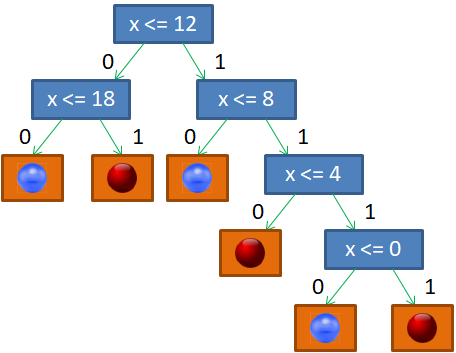
Почему именно так? В действительности, можно было бы придумать и другие варианты. Я руководствовался простым принципом: в каждой вершине порог t следует выбирать так, чтобы в одной части было как можно больше представителей только одного какого-либо класса (шаров одного цвета), а в другой – все оставшиеся. То есть, это некий критерий здравого смысла, естественная эвристика, которая сокращает глубину дерева. Но вы можете сказать, а зачем нам минимизировать глубину решающего дерева? Пусть оно получается таким, каким сделает его алгоритм. Например, будем поочередно перебирать пороги t от 0 до 19 и рано или поздно гарантированно разобьем последовательность шаров на красные и синие. Да, дерево будет значительно глубже, ну и что? Однако, здесь всегда следует помнить, что данная последовательность всего лишь обучающая выборка. Мы предполагаем использовать это дерево и для других подобных последовательностей с несколько другим распределением синих и красных шаров. Иначе, это была бы не задача машинного обучения, а просто разбиение конкретной выборки. Так вот, можно заметить, что чем меньше глубина решающего дерева, тем меньше используется порогов разбиения и тем выше, в среднем, обобщающая способность такого дерева. Именно поэтому стараются строить деревья минимальной глубины.
Но как это сделать? В самом простом варианте можно выполнить полный перебор всех возможных разбиений и выбрать дерево минимальной глубины. Для нашей задачи это еще как-то можно было бы реализовать. Но, как вы понимаете, в общем случае, это займет так много времени, что не хватит и жизни всего человечества. Поэтому здесь нужно искать другие подходы.
Если вернуться к моему варианту бинарного дерева, то, как я отмечал, в каждой промежуточной вершине старался порог t выбирать так, чтобы в одной части было как можно больше представителей одного класса (шаров одного цвета), а в другой как получится, т.е. все оставшиеся. Это некая эвристика. Наша цель, наделить алгоритм примерно такой же эвристикой. Как это сделать? Математики обратили свои взоры в ранние наработки самых разных формул и представили миру несколько критериев качества предикатов. Одним из популярных стала энтропия:
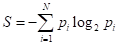
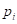
где — вероятность i-го класса; N – общее число классов (в нашем примере – цветов шаров). Известно, что эта величина является некой характеристикой хаотичности системы. Чем больше разнообразия, тем выше энтропия, и наоборот, чем больше порядка, тем она меньше. Ее можно естественным образом использовать для оценки характеристики текущего разбиения каждой вершины. Например:
Такую характеристику в решающих деревьях называют impurity (информативностью). Чем она меньше, тем лучше (качественнее) набор данных в вершине. И, наоборот, чем она больше, тем разнообразнее (хаотичнее) данные в вершине.
Вернемся, теперь, к примеру разбиения последовательности красных и синих шаров. Последовательность состоит из N=2 классов с вероятностями появления каждого из них:
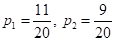
Следовательно, impurity (в данном случае энтропия) корневой вершины дерева, равна:
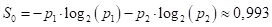
Далее, мы выбираем предикат с порогом t = 12:
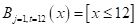
и получаем две подвыборки с impurity (энтропиями):
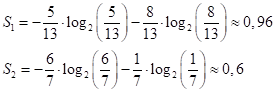
Величина 0,6 значительно меньше начального значения 0,993, а значит, во второй последовательности больше порядка, чем в исходной. И это очень хорошо. Именно этого мы и добиваемся, выбирая порог t.
Теперь, нам нужно на основе величин сформировать единый критерий (одно число), по которому мы бы судили о качестве разбиения выборки на две подвыборки. Это также можно выполнить различными способами, но часто используется следующая формула под названием информационный выигрыш (information gain):
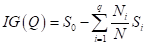
где  — число групп (подвыборок) после разбиения;
— число групп (подвыборок) после разбиения; 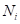 — число элементов в i-й группе после разбиения; Q – критерий разбиения (предикат). Для нашего примера оценки качества разбиения корневой вершины с порогом t=12, имеем:
— число элементов в i-й группе после разбиения; Q – критерий разбиения (предикат). Для нашего примера оценки качества разбиения корневой вершины с порогом t=12, имеем:
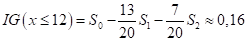
Если посчитать этот критерий для других порогов t, то окажется, что при t = 12 имеем наибольшее значение. А, значит, наилучшее разбиение с точки зрения выбранных критериев: энтропии и информационного выигрыша.
Математически поиск наилучшего предиката в текущей вершине дерева, можно записать так:
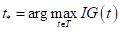
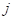
Или, в общем случае, учитывая, что мы подбираем не только пороги, но и признаки , по которым делятся объекты на две подвыборки, имеем:
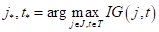
А в качестве impurity, помимо энтропии также используют:
- критерий Джини (Gini impurity):
 , здесь — вероятность (частота) появления объектов k-го класса в вершине дерева;
, здесь — вероятность (частота) появления объектов k-го класса в вершине дерева; - ошибка классификации (misclassification error): .
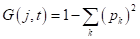 , здесь
, здесь 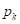 — вероятность (частота) появления объектов k-го класса в вершине дерева;
— вероятность (частота) появления объектов k-го класса в вершине дерева;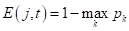 .
. (Критерий Джини не следует путать с индексом Джини, о котором мы ранее говорили – это две совершенно разные характеристики.) На практике критерий Джини работает почти также, как и энтропия. Это хорошо видно из графиков данных критериев при бинарной классификации: 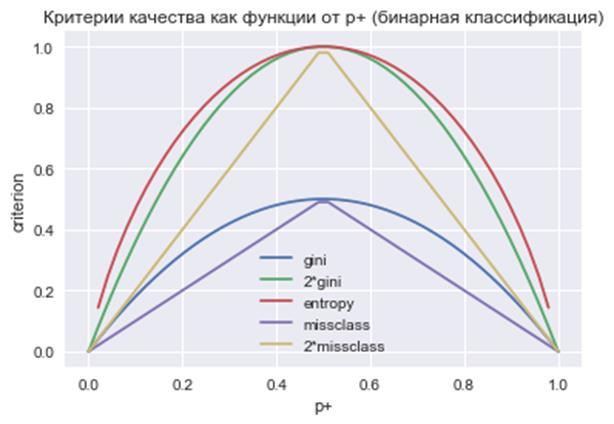 Здесь по оси абсцисс (горизонтальной оси) отложена вероятность
Здесь по оси абсцисс (горизонтальной оси) отложена вероятность 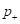 положительного класса, а по оси ординат – значения критериев. Как видите, графики критерия Джини и энтропии практически совпадают. Поэтому они и приводят к похожим конструкциям решающих деревьев. На следующем занятии мы рассмотрим два алгоритма построения решающих деревьев, используя рассмотренные критерии качества разбиения.
положительного класса, а по оси ординат – значения критериев. Как видите, графики критерия Джини и энтропии практически совпадают. Поэтому они и приводят к похожим конструкциям решающих деревьев. На следующем занятии мы рассмотрим два алгоритма построения решающих деревьев, используя рассмотренные критерии качества разбиения.
Источник
01b — Логические методы классификации

критерий Джини показывает, сколько есть пар объектов лежащий в одном и том же классе, которые сместе идут либо в левую дочернюю вершину, либо в правую дочернюю вершину
у эти объектов должны совпадать метки классов и совпадать значения предикатов
можно придумать и противоположную стратегию, когда мы подсчитываем число пар объектов, которые лежали в разных классах, и они ушли в разные ветки
один пошел налево, другой на право
то есть, если критерий Джини меряет, насколько часто объекты одних классов объединяются, то критерий Донского меряет то, насколько данный предикат обладает способностью разделять объекты разных классов
можно проводить эксперименты и смотреть, в каких задачах работает лучше один критерий, в каких работает лучше другой
они строят немного по-разному деревья
есть еще один — энтропийный критерий с достаточно сложной формулой, которая вытекает из теории информации
мы не будем ее разбирать подробно
на практике оказывается, что этот критерий очень похож на критерий Джини
и работает примерно так же
Обработка пропусков. Достоинства и недостатки решающих деревьев.


мы можем по-разному задавать множество предикатов, из которого мы выбираем предикаты во внутренних вершинах
вплоть до того, что это могут быть какие-то другие модели классификации – главное, чтобы они давали ответ да или нет
недостатки вытекают из того, что это жадная стратегия
решения о ветвлении, которые принимаются в каждой внутренней вершине – они локально-оптимальны, но они не оптимальны глобально
мы всегда могли бы полным пребором найти гораздо более компактное решающее дерево, которое решает задачу, может быть, даже с меньшим количеством ошибок
но, поскольку принимая решения о ветвлении во внутренней вершине мы не можем заглянуть далее и понять, насколько хорошо будет идти процесс ветвления дальше, то происходит серия неоптимальных решений о постановке предикатов во внутренних вершинах
а когда мы доходим до вершин, близких к терминальным, мы вообще имеем дело с высокой фрагментацией выборки
туда доходит небольшое число объектов, и решение о том, какой предикат поместить во внутреннюю вершину, или к какому классу отнести объект в терминальной вершине – эти решения становятся статистически ненадежными
они принимаются по выборкам малого объема
ну и наконец, данная процедура очень чувствительна и к составу выборки, и к шумовым признакам
можно показать, что, например, изъятие одного объекта из обучающей выборки часто приводит к тому, что дерево строится совсем другое
в какой-то вершине произошел выбор другого предиката, и дальше все поддерево будет строиться совсем по-другому
еще раз, эти недостатки вытекают из того, что алгоритм жадный
Способы устранения недостатков решающих деревьев

известный пример
синтетическая задача классификации
classification of XOR problem
это пример задачи, которая не решается, например, линейным классификатором
выборка не может быть разделена прямой на два класса без ошибок
решающее дерево глубины два легко разделяет эту выборку
но, однако, нетривиально догадаться, особенно для жадного алгоритма, что на первом шаге деления надо просто произвольным образом провести прямую – вертиальную посередине или горизонтальную посередине
и тогда на втором шаге у нас выборка разделится без ошибок
жадный алгоритм этого не видит
жадный алгоритм на первом же шаге попытается отделить два объекта одного из классов
и весь процесс построения дерева пойдет так, что оптимальное построение двухуровневого дерева будет уже невозможно
строится такое дерево из четырех уровней, которое делит выборку не так, как нам хотелось бы




плохо работают на выборках с большим количеством признаков
Одна вершина дерева может учитывать лишь один признак — значит, для полноценной работы на выборках с десятками тысяч признаков дереву понадобятся десятки тысяч вершин. Чтобы такое дерево не переобучилось, нужна огромная выборка; более того, обучение такого дерева будет очень трудозатратным. Решающие деревья скорее подходят для выборок с небольшим числом признаков.
Источник