Дерево разбора
Графическим способом отображения процесса разбора цепочек является дерево разбора (или дерево вывода).
Определение 3.4. Деревом разбора грамматики называется дерево, которое соответствует некоторой цепочке вывода и удовлетворяет следующим условиям:
- каждая вершина дерева обозначается символом грамматики ;
- корнем дерева является вершина, обозначенная начальным символом грамматики S;
- листьями дерева (концевыми вершинами) являются вершины, обозначенные терминальными символами грамматики или символом пустой строки e;
- если некоторый узел дерева обозначен символом , а связанные с ним узлы – символами , то в грамматике существует правило .
Дерево разбора можно построить двумя способами: сверху вниз и снизу вверх.
Нисходящее дерево разбора
При построении дерева вывода сверху вниз построение начинается с начального символа грамматики, который помещается в корень дерева. Затем в грамматике выбирается необходимое правило, и на первом шаге вывода корневой символ раскрывается на несколько символов первого уровня. На втором шаге среди всех концевых вершин дерева выбирается крайняя (крайняя левая для левостороннего вывода, крайняя правая для правостороннего) вершина, обозначенная нетерминальным символом, для этой вершины выбирается нужное правило грамматики, и она раскрывается на несколько вершин следующего уровня. Построение дерева заканчивается, когда все концевые вершины обозначены терминальными символами, в противном случае надо вернуться ко второму шагу и продолжить построение.
Восходящее дерево разбора
Построение дерева вывода снизу вверх начинается с листьев дерева. В качестве листьев выбираются терминальные символы конечной цепочки вывода, которые на первом шаге построения образуют последний уровень (слой) дерева. Построение дерева идет по слоям. На втором шаге построения в грамматике выбирается правило, правая часть которого соответствует крайним символам в слое дерева (крайним правым символам при правостороннем выводе и крайним левым при левостороннем). Выбранные вершины слоя соединяются с новой вершиной, которая выбирается из левой части правила. Новая вершина попадает в слой дерева вместо выбранных вершин. Построение дерева закончено, если достигнута корневая вершина (обозначенная начальным символом), иначе следует вернуться ко второму шагу и повторить его над полученным слоем дерева.
Пример 3.2. Нисходящее дерево вывода строки a+b+a в грамматике G (пример 3.1) показано на рисунке 3.1.
Процесс построения восходящего дерева разбора показан на рисунке 3.2.
Рисунок 3.2 – Процесс построения восходящего дерева разбора
Источник
Дерево вывода
- целевой символ грамматики помещается в вершину дерева;
- в грамматике выбирается необходимое правило и целевой символ раскрывается на несколько символов первого уровня;
- среди всех концевых вершин дерева выбирается крайняя (левая для левостороннего вывода, правая – для правостороннего вывода) вершина, обозначенная нетерминальным символом;
- для неё выбирается нужное правило и она снова раскрывается на несколько вершин следующего уровня;
- если все концевые вершины обозначены терминальными символами, процесс закончен. Иначе – возврат на шаг 3.
При построении дерева снизу вверх процесс построения начинается с листьев, в качестве которых выбираются терминальные символы цепочки языка. Они образуют последний уровень дерева; далее в грамматике выбирается соответствующее правило, согласно которому один или несколько символов цепочки могут быть «свёрнуты» в нетерминальный символ – (при левостороннем или правостороннем выводе это крайние символы в слое дерева) они соединяются с новой вершиной; и так до тех пор, пока все вершины не окажутся соединены в корневой вершине. Поскольку компилятор читает программу сверху вниз и слева направо, для построения дерева сверху вниз обычно используется левосторонний вывод. П ример: Рассмотрим деревья вывода для сентенциальных форм (1) и (2). Подробно рассмотрим построение для формы (1). Д
ример: Рассмотрим деревья вывода для сентенциальных форм (1) и (2). Подробно рассмотрим построение для формы (1). Д ерево строится сверху вниз. Номера шагов обозначены цифрами. Процесс начинается с корня (он помечен целевым символом), далее при выводе применялось правило S –T (первый шаг), следовательно, в следующем уровне будут две вершины («–» и «Т»). Вершина «–» помечена терминальным символом, значит, это лист. Вершина «Т» представляет собой нетерминал и вновь раскрывается по правилу T TF согласно ранее построенному выводу (второй шаг). Поскольку вывод левосторонний, каждый раз в цепочке вывода очередное правило применяется к крайнему левому нетерминалу. Поэтому следующим заменяется нетерминал Т, как самый левый в цепочке вывода (она в настоящий момент имеет вид –TF), и это третий шаг… Процесс продолжается до тех пор, пока все вершины не получат в качестве меток терминальные символы. Для формы (2) построение отличается тем, что в качестве начального символа вместо целевого S взят нетерминал Т, а вывод использован правосторонний. П
ерево строится сверху вниз. Номера шагов обозначены цифрами. Процесс начинается с корня (он помечен целевым символом), далее при выводе применялось правило S –T (первый шаг), следовательно, в следующем уровне будут две вершины («–» и «Т»). Вершина «–» помечена терминальным символом, значит, это лист. Вершина «Т» представляет собой нетерминал и вновь раскрывается по правилу T TF согласно ранее построенному выводу (второй шаг). Поскольку вывод левосторонний, каждый раз в цепочке вывода очередное правило применяется к крайнему левому нетерминалу. Поэтому следующим заменяется нетерминал Т, как самый левый в цепочке вывода (она в настоящий момент имеет вид –TF), и это третий шаг… Процесс продолжается до тех пор, пока все вершины не получат в качестве меток терминальные символы. Для формы (2) построение отличается тем, что в качестве начального символа вместо целевого S взят нетерминал Т, а вывод использован правосторонний. П


 остроение дерева снизу вверх является более неоднозначным процессом. Рассмотрим его для вывода формы (4). При этом будем двигаться по цепочке вывода от её конца к началу. Сначала строим листья «2», «6» и «3». Последним шагом было правило F 2. Оно позволяет заменить терминальный символ ‘2’ на ‘F’ (схема 1). Следующие правила T F и F 6 (схема 2). Далее по правилу T TF нетерминалы T и F сворачиваются в T (схема 3). И наконец после применения правил F 3, T TF и S T получается итоговое дерево (схема 4).
остроение дерева снизу вверх является более неоднозначным процессом. Рассмотрим его для вывода формы (4). При этом будем двигаться по цепочке вывода от её конца к началу. Сначала строим листья «2», «6» и «3». Последним шагом было правило F 2. Оно позволяет заменить терминальный символ ‘2’ на ‘F’ (схема 1). Следующие правила T F и F 6 (схема 2). Далее по правилу T TF нетерминалы T и F сворачиваются в T (схема 3). И наконец после применения правил F 3, T TF и S T получается итоговое дерево (схема 4).
- Контрольные вопросы
- За сколько шагов выводима цепочка из цепочки , если в правилах грамматики есть правило ?
- В чём заключается различие понятий выводимости и непосредственной выводимости?
- Какая грамматика является однозначной?
- Какой вывод называется законченным?
- Что такое сентенциальная форма грамматики?
- В чём состоит различие левостороннего и правостороннего выводов для регулярной грамматики?
- Чем отличается дерево вывода от самого вывода?
- Каким символом помечают корень дерева вывода и какими – его листья?
- Распознаватели. Задача разбора
- Общая схема распознавателя
В числе прочих задач компилятор должен определить принадлежность некоторого текста к конкретному языку. В отношении исходной программы компилятор выступает в роли распознавателя, а человек, создавший программу – в роли генератора цепочек этого языка. Распознаватель – это специальный алгоритм, позволяющий для некоторой цепочки символов определить, принадлежит ли она заданному языку. Это один из способов задания языка. Распознаватель входит в состав компилятора и является частью программного обеспечения компьютера. У словная схема распознавателя имеет следующий вид: Основные компоненты распознавателя:
словная схема распознавателя имеет следующий вид: Основные компоненты распознавателя:
- входная лента – линейная последовательность клеток, или ячеек, каждая из которых содержит ровно один символ входного алфавита;
- входная (считывающая) головка обозревает одну входную ячейку; на каждом шаге работы может сдвигаться на одну ячейку вправо, влево или оставаться на месте;
- устройство управления (УУ), которое координирует работу распознавателя, имеет некоторое множество состояний и конечную память;
- внешняя (рабочая) память может хранить некоторую информацию в процессе работы распознавателя и может иметь неограниченный объем.
Алфавит распознавателя конечен; он включает в себя все допустимые символы входных цепочек, а также некоторый дополнительный алфавит символов, которые могут обрабатываться УУ и храниться в рабочей памяти распознавателя. В процессе своей работы распознаватель может выполнять некоторые элементарные операции, такие как чтение входного символа, сдвиг головки, доступ к рабочей памяти для чтения или записи информации, изменение состояния УУ. Работа распознавателя состоит из последовательности шагов, или тактов. То, каким должен быть этот такт, определяется текущим входным символом, состоянием УУ и символом, извлеченным из памяти. Итак, Такт состоит из следующих моментов:
- входная головка распознавателя сдвигается на одну ячейку вправо, влево или остается на месте;
- в память помещается некоторая информация;
- изменяется состояние УУ.
В процессе работы распознавателя происходит смена конфигураций. Конфигурация распознавателя (мгновенное описание) определяется следующими параметрами:
- состояние УУ;
- содержимое входной ленты и положение считывающей головки в ней;
- содержимое внешней памяти.
Конфигурация называется начальной, если УУ находится в начальном состоянии, входная головка обозревает самый левый символ на входной ленте, а память имеет заранее установленное начальное содержимое. Конфигурация называется заключительной, если УУ находится в одном из множества заключительных состояний, а входная головка обозревает правый концевой маркер или сошла с ленты. Распознаватель допускает входную цепочку символов, если, находясь в начальной конфигурации, в которой данная цепочка записана на входной ленте, он может проделать конечную последовательность шагов, заканчивающуюся одной из его заключительных конфигураций. Некоторые виды распознавателей могут из начальной конфигурации проделать различные последовательности шагов, из которых, может быть, лишь некоторые (или даже одна) приведут к заключительной конфигурации. В таком случае входная цепочка является допущенной. Язык, определяемый распознавателем – это множество всех цепочек, которые допускает этот распознаватель.
Источник
3.1.2 Дерево разбора
Графическим способом отображения процесса разбора цепочек является дерево разбора (или дерево вывода).

Определениедерево разбора грамматики называется дерево, которое соответствует некоторой цепочке вывода и удовлетворяет следующим условиям:
- каждая вершина дерева обозначается символом грамматики
 ;
; - корнем дерева является вершина, обозначенная начальным символом грамматики S;
- листьями дерева (концевыми вершинами) являются вершины, обозначенные терминальными символами грамматики или символом пустой строки ;
- если некоторый узел дерева обозначен символом , а связанные с ним узлы – символами, то в грамматике существует правило
 ;
;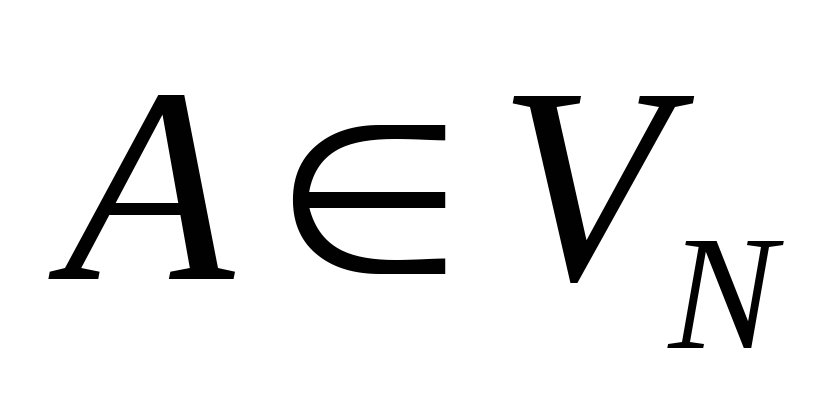 , а связанные с ним узлы – символами
, а связанные с ним узлы – символами , то в грамматике
, то в грамматике  существует правило
существует правило 
Дерево разбора можно построить двумя способами: сверху вниз и снизу вверх.
3.1.2.1 Нисходящее дерево разбора
При построении дерева вывода сверху вниз построение начинается с целевого символа грамматики, который помещается в корень дерева. Затем в грамматике выбирается необходимое правило, и на первом шаге вывода корневой символ раскрывается на несколько символов первого уровня. На втором шаге среди всех концевых вершин дерева выбирается крайняя (крайняя левая — для левостороннего вывода, крайняя правая — для правостороннего) вершина, обозначенная нетерминальным символом, для этой вершины выбирается нужное правило грамматики, и она раскрывается на несколько вершин следующего уровня. Построение дерева заканчивается, когда все концевые вершины обозначены терминальными символами, в противном случае надо вернуться ко второму шагу и продолжить построение.
3.1.2.2 Восходящее дерево разбора
Построение дерева вывода снизу вверх начинается с листьев дерева. В качестве листьев выбираются терминальные символы конечной цепочки вывода, которые на первом шаге построения образуют последний уровень (слой) дерева. Построение дерева идет по слоям. На втором шаге построения в грамматике выбирается правило, правая часть которого соответствует крайним символам в слое дерева (крайним правым символам при правостороннем выводе и крайним левым — при левостороннем). Выбранные вершины слоя соединяются с новой вершиной, которая выбирается из левой части правила. Новая вершина попадает в слой де рева вместо выбранных вершин. Построение дерева закончено, если достигнута корневая вершина (обозначенная целевым символом), а иначе надо вернуться ко второму шагу и повторить его над полученным слоем дерева. Поскольку все известные языки программирования имеют нотацию записи «слева — направо», компилятор также всегда читает входную программу слева направо (и сверху вниз, если программа разбита на несколько строк). Поэтому для построения дерева вывода методом «сверху вниз», как правило, используется левосторонний вывод, а для построения «снизу вверх» — правосторонний вывод. На эту особенность компиляторов стоит обратить внимание. Нотация чтения программ «слева направо» влияет не только на порядок разбора программы компилятором (для пользователя это, как правило, не имеет значения), но и ни порядок выполнения операций — при отсутствии скобок большинство равноправных операций выполняются в порядке слева направо, а это уже имеет существенное значение.
Источник