Использование деревьев решений в задачах прогнозной аналитики
В последние десятилетия одними из самых популярных методов решения задач прогнозной аналитики являются методы построения деревьев решений. Эти методы универсальны, используют эффективную процедуру вычислений, позволяют найти достаточно качественное решение задачи. Именно об этих методах я расскажу в данной статье.
Дерево решений
Дерево решений – структура данных, в процессе обхода которой в каждом узле в зависимости от проверяемого условия принимается определенное решение – перемещение по той или иной ветке дерева от корня к «листьевым» (конечным) вершинам. В «листьевой» вершине дерева содержится искомое значение интересующего атрибута. Деревья решений могут оценивать значения категориальных атрибутов (конечное число дискретных значений), а также количественных. В первом случае говорят о задаче классификации – отнесении объекта к одному из «классов», определяемых атрибутом (например, Да/Нет, Хорошо/Удовлетворительно/Плохо и т.д.). Во втором случае говорят о задаче регрессии, то есть об оценке количественной величины.
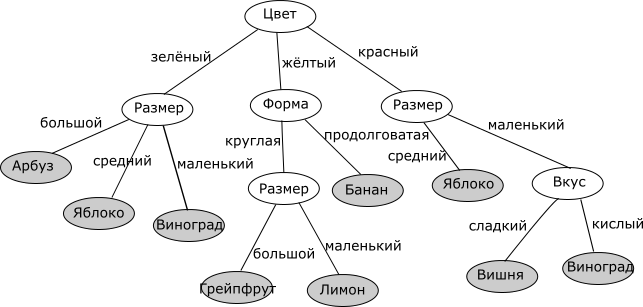
Мы рассмотрим алгоритм, позволяющий построить такое дерево решений для оценивания и предсказания значений интересующего нас категориального атрибута анализируемого набора данных на основе значений других атрибутов (задача классификации).
Вообще способов построить дерево может быть бесконечно много – атрибуты можно рассматривать в разном порядке, проверять в узлах дерева различные условия, останавливать процесс, используя разные критерии. Но нас интересуют только деревья, которые наиболее точно оценивают значение атрибута, с минимальной ошибкой, а также позволяют выявлять зависимость между атрибутами и успешно выполнять прогнозирование значений атрибутов на новых данных. К сожалению, не существует хороших алгоритмов, позволяющих гарантированно найти такое «оптимальное» дерево (за приемлемое время). Однако существуют достаточно хорошие алгоритмы, которые пытаются построить «почти оптимальное» дерево, выполняя на каждой итерации определенный «локальный» критерий оптимальности в надежде, что получившееся дерево тоже в целом будет «оптимальным». Такие алгоритмы называются «жадными». Именно такой алгоритм мы и рассмотрим.
Алгоритм построения дерева решений
Принцип построения дерева следующий. Дерево строится «сверху вниз» от корня. Начинается процесс с определения, какой атрибут следует выбрать для проверки в корне дерева. Для этого каждый атрибут исследуется на предмет, как хорошо он в одиночку классифицирует набор данных (разделяет на классы по целевому атрибуту). Когда атрибут выбран, для каждого его значения создается ветка дерева, набор данных разделяется в соответствии со значением к каждой ветке, процесс повторяется рекурсивно для каждой ветки. Также следует проверять критерий остановки.
Главный вопрос – как выбирать атрибуты. В соответствии с идеей подхода, когда в концевых узлах дерева (листьях) будет искомый нами класс целевого атрибута, необходимо, чтобы при разбиении набора данных в каждом узле получавшиеся наборы данных были все более однородны в плане значений классов (например, большинство объектов в наборе принадлежало бы к классу Арбуз). И необходимо определить количественный критерий, чтобы оценить однородность разбиения.
Энтропия
Рассмотрим набор вероятностей pi, описывающий вероятность соответствия строки данных в нашем наборе (обозначим его X) классу i. Вычислим следующую величину:
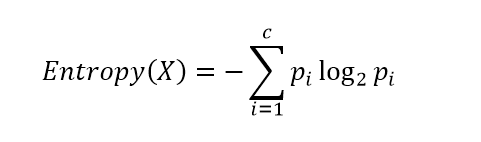
Данная функция представляет собой так называемую энтропию. Энтропия возникла в теории информации и описывает количество информации (в битах), которое необходимо, чтобы закодировать сообщение о принадлежности случайно выбранного объекта (строки) из нашего набора X к одному из классов и передать его получателю. Если класс только один, получателю ничего не нужно передавать, энтропия равна 0 (принимается, что 0log20 = 0). Если все классы равновероятны, то потребуется log2c бит (c – общее количество классов) – максимум функции энтропии.
Далее, для выбора атрибута, для каждого атрибута A вычисляется так называемый прирост информации:
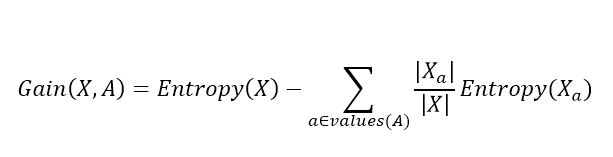
Где values(A) – все принимаемые значения атрибута A, Xa – подмножество набора данных, где A = a, |X| – количество элементов во множестве. Данная величина описывает ожидаемое уменьшение энтропии после разбиения набора данных по выбранному атрибуту. Второе слагаемое – это сумма энтропий для каждого подмножества, взятая со своим весом. Общая разница описывает, как уменьшится энтропия, сколько мы сэкономим бит для кодирования класса случайного объекта из набора X, если мы знаем значения атрибута A и разобьем набор данных на подмножества по данному атрибуту.
Алгоритм выбирает атрибут, соответствующий максимальному значению прироста информации.
Когда атрибут выбран, исходный набор разбивается на подмножества в соответствии с его значениями, исходный атрибут исключается из анализа, процесс повторяется рекурсивно.
Процесс останавливается, когда созданные подмножества стали достаточно однородны (преобладает один класс), а именно когда max(Gain(X,A)) становится меньше некоторого заданного параметра Θ (величина, близкая к 0). Как альтернативный вариант, можно контролировать само множество X, и когда оно стало достаточно мало или стало полностью однородным (только один класс), останавливать процесс.
Жадный алгоритм построения дерева решений
Более структурно алгоритм можно представить следующим образом:
1. Если max(Gain(X,A))
Источник
8.10. Метод «дерево решений»
Для анализа рисков инновационных проектов часто применяют метод дерева решений. Он предполагает, что у проекта существует несколько вариантов развития. Каждое решение, принимаемое по проекту, определяет один из сценариев его дальнейшего развития. При помощи дерева решений решаются задачи классификации и прогнозирования. Дерево решений – это схематическое представление проблемы принятия решений. Ветви дерева решений представляют собой различные события (решения), а его вершины – ключевые состояния, в которых возникает необходимость выбора. Чаще всего дерево решений является нисходящим, т. е. строится сверху вниз. Выделяют следующие этапы построения дерева решений:
- Первоначально обозначают ключевую проблему. Это будет вершина дерева.
- Для каждого момента определяют все возможные варианты дальнейших событий, которые могут оказать влияние на ключевую проблему. Это будут исходящие от вершины дуги дерева.
- Обозначают время наступления событий.
- Каждой дуге прописывают денежную и вероятностную характеристики.
- Проводят анализ полученных результатов.
Основа наиболее простой структуры дерева решений – ответы на вопросы «да» и «нет». Пример 1. Рассмотрим пример дерева решений, задача которого – ответить на вопрос «Пойти ли гулять?». Чтобы решить эту задачу, необходимо ответить на ряд вопросов, которые находятся в узлах дерева (рис. 8.1). Вершина дерева «На улице солнечно» является узлом проверки. Если на этот вопрос получен положительный ответ, то переходим к левой ветви дерева, если отрицательный – то к правой. Движение продолжается до тех пор, пока не будет получен окончательный ответ. 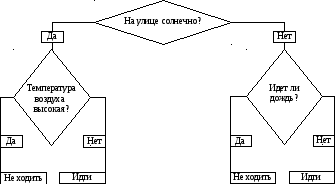 Рис. 8.1. Дерево решений «пойти ли гулять» Для каждой дуги дерева могут быть определены числовые характеристики, например величина прибыли по проекту и вероятность ее получения. В этом случае оно помогает учесть все возможные варианты действия и соотнести с ними финансовые результаты. Для формулирования сценариев развития проекта необходимо располагать достоверной информацией с учетом вероятности и времени наступления событий. Затем переходят к сравнению альтернатив. Пример 2. Компания «Конфетти» в настоящее время выпускает плитки молочного шоколада. Директор по развитию считает, что на рынке повысился спрос на молочный шоколад с наполнителями. Перед компанией стоит вопрос: переходить ли на производство молочного шоколада с наполнителем или не стоит этого делать? Если производить шоколад обоих типов, то потребуется увеличить производственные мощности. Информация об ожидаемых выигрышах и вероятности событий в случае того или иного решения представлена на дереве решений (рис. 8.2). Используя дерево решений, руководитель находит наиболее предпочтительное решение – увеличить производственные мощности. Это обусловлено ожидаемой прибылью – 2 млн руб., которая превышает прибыль 1 млн руб. при отказе от такого наращивания, если в точке «а» будет низкий спрос. Руководитель, двигаясь к первой точке принятия решения, рассчитывает предполагаемую прибыль в случае альтернативных действий.
Рис. 8.1. Дерево решений «пойти ли гулять» Для каждой дуги дерева могут быть определены числовые характеристики, например величина прибыли по проекту и вероятность ее получения. В этом случае оно помогает учесть все возможные варианты действия и соотнести с ними финансовые результаты. Для формулирования сценариев развития проекта необходимо располагать достоверной информацией с учетом вероятности и времени наступления событий. Затем переходят к сравнению альтернатив. Пример 2. Компания «Конфетти» в настоящее время выпускает плитки молочного шоколада. Директор по развитию считает, что на рынке повысился спрос на молочный шоколад с наполнителями. Перед компанией стоит вопрос: переходить ли на производство молочного шоколада с наполнителем или не стоит этого делать? Если производить шоколад обоих типов, то потребуется увеличить производственные мощности. Информация об ожидаемых выигрышах и вероятности событий в случае того или иного решения представлена на дереве решений (рис. 8.2). Используя дерево решений, руководитель находит наиболее предпочтительное решение – увеличить производственные мощности. Это обусловлено ожидаемой прибылью – 2 млн руб., которая превышает прибыль 1 млн руб. при отказе от такого наращивания, если в точке «а» будет низкий спрос. Руководитель, двигаясь к первой точке принятия решения, рассчитывает предполагаемую прибыль в случае альтернативных действий. 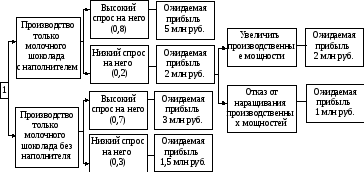 Рис. 8.2. Дерево решений «какой шоколад производить» Для производства только молочного шоколада с наполнителем она составит 4,4 млн руб. (5 × 0,8 + 0,2 × 2). Аналогично рассчитывается ожидаемое значение для варианта выпуска только молочного шоколада без наполнителя, которое равно всего 2,55. Таким образом, наращивание производственных мощностей является наиболее желательным решением и приносит наибольший выигрыш. Пример 3. Руководителю отдела нужно принять решение относительно закупки станков. Второй станок более экономичный, но и в то же время более дорогой и требует больших накладных расходов (рис. 8.3). Руководителю нужно выбрать тот станок, который обеспечит максимизацию прибыли.
Рис. 8.2. Дерево решений «какой шоколад производить» Для производства только молочного шоколада с наполнителем она составит 4,4 млн руб. (5 × 0,8 + 0,2 × 2). Аналогично рассчитывается ожидаемое значение для варианта выпуска только молочного шоколада без наполнителя, которое равно всего 2,55. Таким образом, наращивание производственных мощностей является наиболее желательным решением и приносит наибольший выигрыш. Пример 3. Руководителю отдела нужно принять решение относительно закупки станков. Второй станок более экономичный, но и в то же время более дорогой и требует больших накладных расходов (рис. 8.3). Руководителю нужно выбрать тот станок, который обеспечит максимизацию прибыли.
| Оборудование | Постоянные расходы | Операционный расход на единицу техники |
| Станок 1 | 500 000 | 670 |
| Станок 2 | 700 000 | 940 |
 Рис. 8.3. Дерево решений Руководитель оценивает вероятность спроса на продукцию, производимую на станках:
Рис. 8.3. Дерево решений Руководитель оценивает вероятность спроса на продукцию, производимую на станках:
- 2 000 ед. с вероятностью 0,4;
- 3 000 ед. с вероятностью 0,6.
Станок 1: 840 000 × 0,4 + 1 510 000 × 0,6 = 1 242 000. Станок 2: 1 180 000 × 0,4 + 2 120 000 × 0,6 = 1 744 000. Таким образом, приобретение второго станка более экономично. Недостатками дерева решений является ограниченное число вариантов решения проблемы. В процессе построения дерева решений необходимо обращать внимание на его размер. Оно не должно быть слишком перегруженным, т. к. это уменьшает способность к обобщению и способность давать верные ответы.
Источник