- Алгоритм классификации Random Forest на Python
- Алгоритм Random Forest
- Как работает случайный лес?
- Поиск важных признаков
- Сравнение случайных лесов и деревьев решений
- Создание классификатора с использованием Scikit-learn
- Модели для классификации: Случайный лес (Random Forest)
- Что такое Random Forest?
- Машинное обучение на Python
- Реализация Random Forest на Python
Алгоритм классификации Random Forest на Python
Случайный лес (Random forest, RF) — это алгоритм обучения с учителем. Его можно применять как для классификации, так и для регрессии. Также это наиболее гибкий и простой в использовании алгоритм. Лес состоит из деревьев. Говорят, что чем больше деревьев в лесу, тем он крепче. RF создает деревья решений для случайно выбранных семплов данных, получает прогноз от каждого дерева и выбирает наилучшее решение посредством голосования. Он также предоставляет довольно эффективный критерий важности показателей (признаков).
Случайный лес имеет множество применений, таких как механизмы рекомендаций, классификация изображений и отбор признаков. Его можно использовать для классификации добросовестных соискателей кредита, выявления мошенничества и прогнозирования заболеваний. Он лежит в основе алгоритма Борута, который определяет наиболее значимые показатели датасета.
Алгоритм Random Forest
Давайте разберемся в алгоритме случайного леса, используя нетехническую аналогию. Предположим, вы решили отправиться в путешествие и хотите попасть в туда, где вам точно понравится.
Итак, что вы делаете, чтобы выбрать подходящее место? Ищите информацию в Интернете: вы можете прочитать множество различных отзывов и мнений в блогах о путешествиях, на сайтах, подобных Кью, туристических порталах, — или же просто спросить своих друзей.
Предположим, вы решили узнать у своих знакомых об их опыте путешествий. Вы, вероятно, получите рекомендации от каждого друга и составите из них список возможных локаций. Затем вы попросите своих знакомых проголосовать, то есть выбрать лучший вариант для поездки из составленного вами перечня. Место, набравшее наибольшее количество голосов, станет вашим окончательным выбором для путешествия.
Вышеупомянутый процесс принятия решения состоит из двух частей.
- Первая заключается в опросе друзей об их индивидуальном опыте и получении рекомендации на основе тех мест, которые посетил конкретный друг. В этой части используется алгоритм дерева решений. Каждый участник выбирает только один вариант среди знакомых ему локаций.
- Второй частью является процедура голосования для определения лучшего места, проведенная после сбора всех рекомендаций. Голосование означает выбор наиболее оптимального места из предоставленных на основе опыта ваших друзей. Весь этот процесс (первая и вторая части) от сбора рекомендаций до голосования за наиболее подходящий вариант представляет собой алгоритм случайного леса.
Технически Random forest — это метод (основанный на подходе «разделяй и властвуй»), использующий ансамбль деревьев решений, созданных на случайно разделенном датасете. Набор таких деревьев-классификаторов образует лес. Каждое отдельное дерево решений генерируется с использованием метрик отбора показателей, таких как критерий прироста информации, отношение прироста и индекс Джини для каждого признака.
Любое такое дерево создается на основе независимой случайной выборки. В задаче классификации каждое дерево голосует, и в качестве окончательного результата выбирается самый популярный класс. В случае регрессии конечным результатом считается среднее значение всех выходных данных ансамбля. Метод случайного леса является более простым и эффективным по сравнению с другими алгоритмами нелинейной классификации.
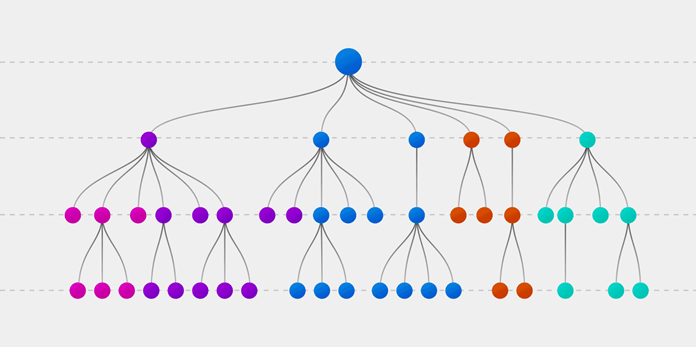
Как работает случайный лес?
Алгоритм состоит из четырех этапов:
- Создайте случайные выборки из заданного набора данных.
- Для каждой выборки постройте дерево решений и получите результат предсказания, используя данное дерево.
- Проведите голосование за каждый полученный прогноз.
- Выберите предсказание с наибольшим количеством голосов в качестве окончательного результата.
Поиск важных признаков
Random forest также предлагает хороший критерий отбора признаков. Scikit-learn предоставляет дополнительную переменную при использовании модели случайного леса, которая показывает относительную важность, то есть вклад каждого показателя в прогноз. Библиотека автоматически вычисляет оценку релевантности каждого признака на этапе обучения. Затем полученное значение нормализируется так, чтобы сумма всех оценок равнялась 1.
Такая оценка поможет выбрать наиболее значимые показатели и отбросить наименее важные для построения модели.
Случайный лес использует критерий Джини, также известный как среднее уменьшение неопределенности (MDI), для расчета важности каждого признака. Кроме того, критерий Джини иногда называют общим уменьшением неопределенности в узлах. Он показывает, насколько снижается точность модели, когда вы отбрасываете переменную. Чем больше уменьшение, тем значительнее отброшенный признак. Таким образом, среднее уменьшение является необходимым параметром для выбора переменной. Также с помощью данного критерия можете быть отображена общая описательная способность признаков.
Сравнение случайных лесов и деревьев решений
- Случайный лес — это набор из множества деревьев решений.
- Глубокие деревья решений могут страдать от переобучения, но случайный лес предотвращает переобучение, создавая деревья на случайных выборках.
- Деревья решений вычислительно быстрее, чем случайные леса.
- Случайный лес сложно интерпретировать, а дерево решений легко интерпретировать и преобразовать в правила.
Создание классификатора с использованием Scikit-learn
Вы будете строить модель на основе набора данных о цветках ириса, который является очень известным классификационным датасетом. Он включает длину и ширину чашелистика, длину и ширину лепестка, и тип цветка. Существуют три вида (класса) ирисов: Setosa, Versicolor и Virginica. Вы построите модель, определяющую тип цветка из вышеперечисленных. Этот датасет доступен в библиотеке scikit-learn или вы можете загрузить его из репозитория машинного обучения UCI.
Начнем с импорта datasets из scikit-learn и загрузим набор данных iris с помощью load_iris() .
Источник
Модели для классификации: Случайный лес (Random Forest)
В прошлой статье мы рассматривали и даже реализовывали собственноручно такой метод классификации как дерево решений, сегодня будем разбираться с алгоритмом который базируется на деревьях решений– случайный лес (Random Forest).
Что такое Random Forest?
Random Forest (случайный лес) – это алгоритм машинного обучения, который используется для решения задач классификации и регрессии. Он является расширением алгоритма решающих деревьев, который использует ансамбль деревьев для улучшения качества классификации или регрессии.
Суть алгоритма заключается в том, что он создает множество решающих деревьев и использует их для предсказания классов объектов. Каждое дерево строится на случайном подмножестве обучающих данных и случайном подмножестве признаков. В результате, каждое дерево в ансамбле получается немного разным, что позволяет уменьшить эффект переобучения и повысить качество предсказаний.
Для построения каждого дерева случайного леса происходит следующее:
- Случайным образом выбирается подмножество обучающих объектов (bootstrap sample) из всего набора данных. Этот подмножество может содержать повторяющиеся объекты.
- Случайным образом выбирается подмножество признаков (обычно корень квадратный от общего числа признаков). Это позволяет уменьшить корреляцию между деревьями в ансамбле и улучшить их разнообразие.
- Строится дерево решений на выбранном подмножестве данных и признаков. При построении дерева используется критерий информативности (например, энтропийный критерий), который позволяет выбрать наилучший признак для разбиения данных на каждом уровне дерева.
- Повторяем шаги 1-3 для каждого дерева в ансамбле.
После построения всех деревьев в ансамбле, для каждого объекта данных происходит голосование по всем деревьям, и наиболее популярный класс становится предсказанным классом. В случае задачи регрессии, результаты всех деревьев усредняются, и это усредненное значение становится предсказанием.
Одно из главных преимуществ Random Forest заключается в том, что он позволяет оценить важность каждого признака для классификации объектов. Это можно сделать, используя атрибут feature_importances_ модели, который возвращает массив значений, отражающих важность каждого признака. Более важные признаки будут иметь более высокие значения.
Важно заметить, что Random Forest менее подвержен проблеме переобучения (overfitting) , что является одной из основных проблем в задачах машинного обучения. Это связано с тем, что каждое дерево строится на случайном подмножестве данных и признаков, что позволяет уменьшить корреляцию между деревьями и повысить их разнообразие.
Еще одним преимуществом Random Forest является его способность обрабатывать большое количество признаков и работать с данными различных типов (например, числовые, категориальные, текстовые). Кроме того, модель не требует сложной предобработки данных и может работать с пропущенными значениями.
Существует несколько параметров, которые можно настраивать при использовании Random Forest, например, количество деревьев в ансамбле, количество объектов и признаков в каждом подмножестве, критерий информативности, максимальную глубину деревьев и т.д. Настройка этих параметров может помочь улучшить качество модели и снизить вероятность переобучения.
Машинное обучение на Python
Код курса
PYML
Ближайшая дата курса
Длительность обучения
24 ак.часов
Стоимость обучения
49 500 руб.
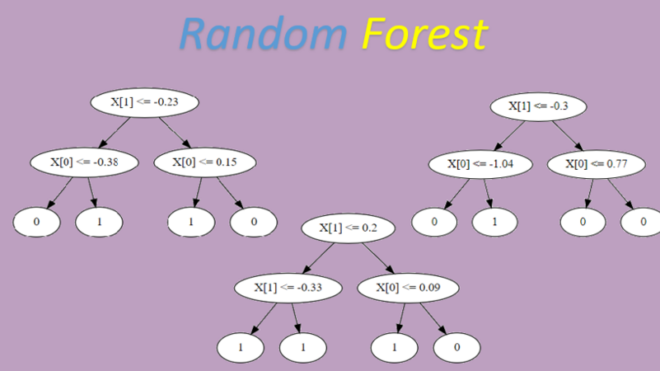
Реализация Random Forest на Python
Так как Random Forest, это ансамбль деревьев решений, воспользуемся классом который реализует дерево решений, который мы реализовали в прошлой статье. Для начала импортируем всё библиотеки, которые нам пригодятся. Дерево решений я так же запаковал в .py файл и буду использовать здесь как библиотеку:
import numpy as np import matplotlib.pyplot as plt from sklearn import svm, datasets from sklearn.metrics import accuracy_score from sklearn.datasets import make_classification from sklearn.metrics import classification_report from My_DecisionTree import DecisionTree # Класс реализованный в прошлой статье
Далее реализуем класс для обучения алгоритма леса решений:
class RandomForestClassifier: def __init__(self, n_estimators=100, max_depth=None, random_state=None): # Конструктор класса, устанавливающий параметры модели self.n_estimators = n_estimators # количество деревьев в лесу self.max_depth = max_depth # максимальная глубина деревьев self.random_state = random_state # случайное начальное состояние для генератора случайных чисел self.estimators = [] # список для хранения деревьев def fit(self, X, y): # Метод для обучения модели на тренировочных данных X и метках y rng = np.random.default_rng(self.random_state) # инициализация генератора случайных чисел for i in range(self.n_estimators): # Использование Bootstrap Aggregating для случайного выбора объектов для текущего дерева idxs = rng.choice(X.shape[0], X.shape[0]) X_subset, y_subset = X[idxs], y[idxs] # Создание и обучение дерева решений с заданными параметрами clf = DecisionTree(max_depth=self.max_depth) clf.fit(X_subset, y_subset) self.estimators.append(clf) # Добавление обученного дерева в список def predict(self, X): # Метод для предсказания меток на новых данных X y_pred = [] for i in range(len(X)): votes = <> # Словарь для подсчета голосов деревьев за каждый класс for clf in self.estimators: pred = clf.predict([X[i]])[0] # Предсказание метки на текущем дереве if pred not in votes: votes[pred] = 1 else: votes[pred] += 1 y_pred.append(max(votes, key=votes.get)) # Выбор метки с наибольшим количеством голосов return np.array(y_pred) # Возвращение предсказанных меток в виде массива numpy Далее обучим и оценим точность нашего алгоритма: # Генерируем данные для обучения X, y = make_classification(n_samples=1000, n_features=2, n_redundant=0, n_informative=2, random_state=1, n_clusters_per_class=1) clf = RandomForestClassifier(n_estimators=100, max_depth=3) clf.fit(X, y) # Прогнозируем метки классов y_pred = clf.predict(X) print(classification_report(y, y_pred)) OUT: precision recall f1-score support 0 0.91 0.94 0.93 500 1 0.94 0.91 0.92 500 accuracy 0.93 1000 macro avg 0.93 0.93 0.92 1000 weighted avg 0.93 0.93 0.92 1000
Как видим, если сравнивать с результатами классификации одним деревом, которые мы получили в прошлой статье, лес решений справляется лучше.
Далее визуально оценим как принимает решение наш алгоритм:
Источник