- 1. Алгоритм работы метода цепочек.
- 2. Алгоритм поиска элемента в таблице идентификаторов.
- 4. Обработка ошибок
- 5. Драйвер
- II. Контрольные вопросы
- Структуры данных. Связный список
- Структуры данных. Хеш-таблицы. Рехеширование
- Структуры данных. Хеш-таблицы. Метод цепочек
- 1.3 Метод бинарного дерева
- 1.4 Метод цепочек
- 2.2 Назначение лексического анализатора
1. Алгоритм работы метода цепочек.
2. Алгоритм поиска элемента в таблице идентификаторов.
- Вычислить значение хеш-функции n для искомого элемента A. Если ячейка хеш-таблицы по адресу n пустая, то элемент не найден и алгоритм завершен, иначе – j:=1, выбрать из хеш-таблицы адрес ячейки таблицы идентификаторов mj.
- Сравнить имя элемента в ячейке таблицы идентификаторов по адресу mj с именем искомого элемента A. Если они совпадают, то искомый элемент найден и алгоритм завершен, иначе – перейти к шагу 3.
- Проверить значение поля ссылки в ячейке таблицы идентификаторов по адресу mj. Если оно пустое, то искомый элемент не найден и алгоритм завершен; иначе –j:=j+1, выбрать из поля ссылки адрес mj и перейти к шагу 2.
4. Обработка ошибок
5. Драйвер
Драйвер – это управляющая программа, которая необходима для инициализации и запуска всех функций калькулятора.
II. Контрольные вопросы
- Что такое рекурсивная подпрограмма?
- Какие существуют рекурсивные структуры данных?
- В чем заключается задача поиска данных в таблице?
- Что такое таблица идентификаторов?
- В чем заключается алгоритм Кнута, Мориса и Пратта (КМП-поиск)?
- В чем заключается алгоритм Боуера и Мура (БМ-поиск)?
- В чем заключается бинарный поиск?
- Что представляют собой абстрактные структуры данных и для чего они предназначены?
- Что такое АТД-cловарь и для чего он используется?
- Что такое хеширование и хеш-таблица?
- Что такое хеш-адресация?
- Что такое коллизия, и в каких случаях происходят коллизии?
- Какие существуют методы разрешения коллизий?
- В чем заключается метод цепочек?
- В чем заключается метод открытой адресации?
- В чем заключается метод построения таблиц, имеющих форму бинарного дерева?
- Принципы работы хеш-функций.
- Что такое рехеширование, и в чем заключается этот метод?
- Из каких основных частей состоит калькулятор?
- Что представляет собой программа синтаксического разбора?
- В чем заключается задача функций ввода и обработки ошибок? Что представляет собой драйвер?
Источник
Структуры данных. Связный список
LinkedList или связный список – это структура данных. Связный список обеспечивает возможность создать двунаправленную очередь из каких-либо элементов. Каждый элемент такого списка считается узлом. По факту в узле есть его значение, а также две ссылки – на предыдущий и на последующий узлы. Из-за таких особенностей строения из связного списка можно организовать стек, очередь или двойную очередь. Это динамическая структура данных, что означает, что память, зарезервированная для связного списка, может быть увеличена или уменьшена во время выполнения.
Структуры данных. Хеш-таблицы. Рехеширование
Хеш — это математический алгоритм, преобразовывающий произвольный массив данных в состоящую из букв и цифр строку фиксированной длины. Мы можем вставить данные в хеш-функцию и получить на выходе хеш, по которому будет очень легко потом найти исходную информацию в хеш-карте. Хеш-карта — таблица с парами ключ -значение. В качестве ключа задается хеш, в качестве значения — исходная информация. Рехеширование необходимо для того, чтобы избегать коллизий. Коллизия — это явление, характеризующееся одинаковыми хешами для разных исходных данных. В таких случаях вызывается функция рехеширования — создание уникального хеша. В последующем, если мы будем искать данные, к которым мы вызывали функцию рехеширования, мы, найдя, что под данным хешем уже есть какие-то данные будем вызывать функцию рехеширования до тех пор пока не найдем искомые данные.
Структуры данных. Хеш-таблицы. Метод цепочек
Хеш — это математический алгоритм, преобразовывающий произвольный массив данных в состоящую из букв и цифр строку фиксированной длины. Мы можем вставить данные в хеш-функцию и получить на выходе хеш, по которому будет очень легко потом найти исходную информацию в хеш-карте. Хеш-карта — таблица с парами ключ-значение. В качестве ключа задается хеш, в качестве значения — исходная информация. Метод цепочек необходим для того, чтобы избегать коллизий. Коллизия — это явление, характеризующееся одинаковыми хешами для разных исходных данных. В таких случаях создается таблица с возвращаемыми значениями хеш-функции и берется список, который может изменяться динамически. В этот список мы заносим наши исходные данные и делаем из первой таблицы ссылку на эти данные. Позже, если происходит коллизия, мы заносим элемент в список исходных данных и делаем ссылку на этот элемент из элемента, который уже находился под данным хешем. Это позволяет гораздо эффективней работать с памятью, чем обычное рехеширование.


Бинарное дерево — это иерархическая структура данных, в которой каждый узел имеет значение (оно же является в данном случае и ключом) и ссылки на левого и правого потомка. Узел, находящийся на самом верхнем уровне (не являющийся чьим либо потомком) называется корнем. Мы сортируем дерево, начиная с первого элемента. Влево закидываем меньшие значения вправо большие.
https://www.youtube.com/watch?v=-jNBafIT7sI&t=244s — лекция по сортировкам

Сравниваем элементы поочередно ища наименьший, найдя добавляем его в начало отсортированного массива и больше не трогаем
Выбираем область из двух элементов и сравниваем с предыдущими и смотрим куда его вставить. Далее эту область расширяем на один элемент и снова смотрим куда вставить и так далее пока не дойдем до конца.
Элемент сравниваем последовательно друг с другом и меняем местами, если эл-т больше последующего. запоминаем самый последний отсортированный элемент (максимальный) и больше его не рассматриваем
Алгоритм можно ускорить, используя следующие методы:

- условие Айверсона: Если в ходе сортировки на каком-либо этапе не было перестановок (при шаге в 1), то множество упорядоченно
- Применить шейкерную сортировку: запоминаем не только последний, но и первый (минимальный) при условии, что в нем не было перестановок (минимальный элемент)
Источник
1.3 Метод бинарного дерева
Метод построения таблиц, при котором таблица имеет форму бинарного дерева. Каждый узел дерева представляет собой элемент таблицы, причем корневой узел является первым элементом. При построении дерева элементы сравниваются между собой, и в зависимости от результатов, выбирается путь в дереве. Предположим, что надо записать новый идентификатор. Для него выбирается левое поддерево, если этот идентификатор меньше текущего, если же идентификатор больше, выбирается правое поддерево. В случае если текущий узел не является концевым, переходим в следующий узел (согласно выбранному направлению) и опять сравниваем добавляемый идентификатор с текущим.
Для данного метода число требуемых сравнений и форма получившегося дерева во многом зависят от того порядка, в котором поступают идентификаторы.
Блок-схема метода бинарного дерева представлена на рисунке 1.1

Рис. 1. 1 – Блок-схема метода бинарного дерева; а) – Блок-схема алгоритма метода бинарного дерева;б) – Блок-схема функции добавления идентификатора;
в) – Блок-схема функции поиска идентификатора
1.4 Метод цепочек
Блок-схема метода цепочек списка представлена на рисунке 1.2
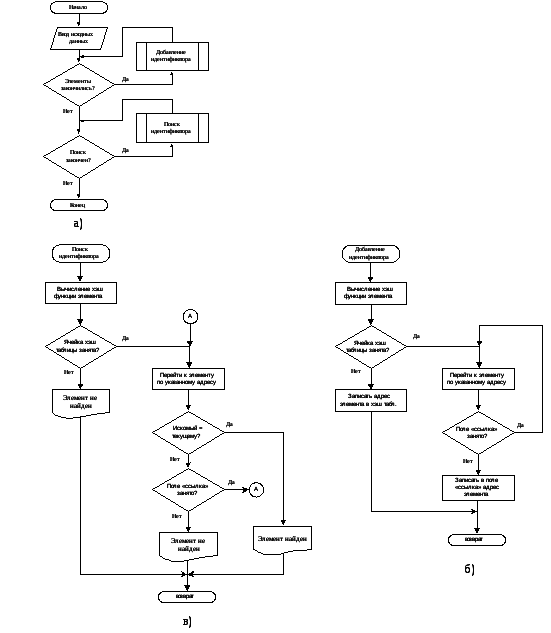
Рис. 1.2 – Блок-схема метода цепочек; а) – Блок-схема алгоритма метод цепочек;
б) – Блок-схема функции добавление идентификатора;в) – Блок-схема функции поиска идентификатора
1.5 Результат выполнения программы
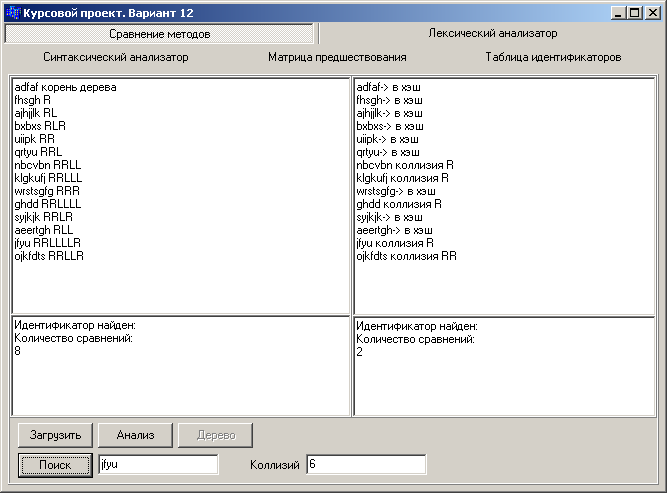
Рис. 1.3 – Результаты сравнения методов организации таблицы идентификаторов
При поиске идентификаторов в таблицах организованных методом бинарного дерева и методом цепочек было установлено, что количество сравнений в бинарном дереве в несколько раз больше, чем в методе цепочек.
Для сравнения методов организации таблицы идентификаторов был разработан модуль, иллюстрирующий их работу.
Было выявлено, что метод цепочек является более эффективным, чем метод бинарного дерева, так как для поиска идентификатора используется меньшее количество сравнений.
В дальнейшем для заполнения таблицы идентификаторов исходной программы будем использовать метод цепочек.
2 Проектирование лексического анализатора
Текст на входном языке задается в виде символьного (текстового) файла. Программа должна выдает сообщения о наличие во входном тексте ошибок, которые могут быть обнаружены на этапе лексического анализа.
Предусмотрены следующие варианты операторов входной программы:
- оператор присваивания вида :=;
- условный оператор вида ifthen
- либо ifthenelse;
- составной оператор вида begin. end;
- оператор цикла dowhile;
- арифметические операции сложения (+), вычитания (-), декремент (—);
- операции сравнения «меньше» (<), «больше» (>), «равно» (=);
- логические операции and, or, not;
- операндами в выражениях могут выступать идентификаторы и константы;
- все идентификаторы должны восприниматься как переменные целого типа.
2.2 Назначение лексического анализатора
Лексический анализатор (или сканер) – это часть компилятора, которая читает литеры программы на исходном языке и строит из них слова (лексемы) исходного языка. На вход лексического анализатора поступает текст исходной программы, а выходная информация передается для дальнейшей обработки компилятором на этапе синтаксического анализа и разбора. В основном лексические анализаторы выполняют исключение из текста исходной программы комментариев и незначащих пробелов, а также выделение лексем следующих типов: идентификаторов, строковых, символьных и числовых констант, ключевых (служебных) слов входного языка.
Источник