- Обход двоичного дерева на Python
- Что такое двоичное дерево?
- Строим двоичное дерево на Python
- Обход двоичного дерева
- Pre-Order
- Post-Order
- In-Order
- Бинарное дерево. Способы обхода и удаления вершин
- Алгоритм обхода в глубину
- Удаление вершин бинарного дерева
- Удаление листовых вершин
- Удаление узла с одним потомком
- Удаление узла с двумя потомками
Обход двоичного дерева на Python
Да, двоичные деревья — не самая любимая тема программистов. Это одна из тех старых концепций, о целесообразности изучения которых постоянно ведутся споры. В работе вам довольно редко придется реализовывать двоичные деревья и обходить их, так зачем же уделять им так много внимания на технических собеседованиях?
Сегодня мы не будем переворачивать двоичное дерево (ффухх!), но рассмотрим пару методов его обхода. К концу статьи вы поймете, что двоичные деревья не так страшны, как кажется.
Что такое двоичное дерево?
Недавно мы разбирали реализацию связных списков на Python. Каждый такой список состоит из некоторого количества узлов, указывающих на другие узлы. А если бы узел мог указывать не на один другой узел, а на большее их число? Вот это и есть деревья. В них каждый родительский узел может иметь несколько узлов-потомков. Если у каждого узла максимум два узла-потомка (левый и правый), такое дерево называется двоичным (бинарным).
В приведенном выше примере «корень» дерева, т. е. самый верхний узел, имеет значение 1. Его потомки — 2 и 3. Узлы 3, 4 и 5 называют «листьями»: у них нет узлов-потомков.
Строим двоичное дерево на Python
Как построить дерево на Python? Реализация будет похожей на наш класс Node в реализации связного списка. В этом случае мы назовем класс TreeNode .
Определим метод __init__() . Как всегда, он принимает self . Также мы передаем в него значение, которое будет храниться в узле.
class TreeNode: def __init__(self, value):
Установим значение узла, а затем определим левый и правый указатель (для начала поставим им значение None ).
class TreeNode: def __init__(self, value): self.value = value self.left = None self.right = None
И… все! Что, думали, что деревья куда сложнее? Если речь идет о двоичном дереве, единственное, что его отличает от связного списка, это то, что вместо next у нас тут есть left и right .
Давайте построим дерево, которое изображено на схеме в начале статьи. Верхний узел имеет значение 1. Далее мы устанавливаем левые и правые узлы, пока не получим желаемое дерево.
tree = TreeNode(1) tree.left = TreeNode(2) tree.right = TreeNode(3) tree.left.left = TreeNode(4) tree.left.right = TreeNode(5)
Обход двоичного дерева
Итак, вы построили дерево и теперь вам, вероятно, любопытно, как же его увидеть. Нет никакой команды, которая позволила бы вывести на экран дерево целиком, тем не менее мы можем обойти его, посетив каждый узел. Но в каком порядке выводить узлы?
Самые простые в реализации обходы дерева — прямой (Pre-Order), обратный (Post-Order) и центрированный (In-Order). Вы также можете услышать такие термины, как поиск в ширину и поиск в глубину, но их реализация сложнее, ее мы рассмотрим как-нибудь потом.
Итак, что из себя представляют три варианта обхода, указанные выше? Давайте еще раз посмотрим на наше дерево.
При прямом обходе мы посещаем родительские узлы до посещения узлов-потомков. В случае с нашим деревом мы будем обходить узлы в таком порядке: 1, 2, 4, 5, 3.
Обратный обход двоичного дерева — это когда вы сначала посещаете узлы-потомки, а затем — их родительские узлы. В нашем случае порядок посещения узлов при обратном обходе будет таким: 4, 5, 2, 3, 1.
При центрированном обходе мы посещаем все узлы слева направо. Центрированный обход нашего дерева — это посещение узлов 4, 2, 5, 1, 3.
Давайте напишем методы обхода для нашего двоичного дерева.
Pre-Order
Начнем с определения метода pre_order() . Наш метод принимает один аргумент — корневой узел (расположенный выше всех).
Дальше нам нужно проверить, существует ли этот узел. Вы можете возразить, что лучше бы проверить существование потомков этого узла перед их посещением. Но для этого нам пришлось бы написать два if-предложения, а так мы обойдемся одним.
def pre_order(node): if node: pass
Написать обход просто. Прямой обход — это посещение родительского узла, а затем каждого из его потомков. Мы «посетим» родительский узел, выведя его на экран, а затем «обойдем» детей, вызывая этот метод рекурсивно для каждого узла-потомка.
# Выводит родителя до всех его потомков def pre_order(node): if node: print(node.value) pre_order(node.left) pre_order(node.right)
Просто, правда? Можем протестировать этот код, совершив обход построенного ранее дерева.
Post-Order
Переходим к обратному обходу. Возможно, вы думаете, что для этого нужно написать еще один метод, но на самом деле нам нужно изменить всего одну строчку в предыдущем.
Вместо «посещения» родительского узла и последующего «обхода» детей, мы сначала «обойдем» детей, а затем «посетим» родительский узел. То есть, мы просто передвинем print на последнюю строку! Не забудьте поменять имя метода на post_order() во всех вызовах.
# Выводит потомков, а затем родителя def post_order(node): if node: post_order(node.left) post_order(node.right) print(node.value)
Каждый узел-потомок посещен до посещения его родителя.
In-Order
Наконец, напишем метод центрированного обхода. Как нам обойти левый узел, затем родительский, а затем правый? Опять же, нужно переместить предложение print!
# выводит левого потомка, затем родителя, затем правого потомка def in_order(node): if node: in_order(node.left) print(node.value) in_order(node.right)
Вот и все, мы рассмотрели три простейших способа совершить обход двоичного дерева.
Источник
Бинарное дерево. Способы обхода и удаления вершин
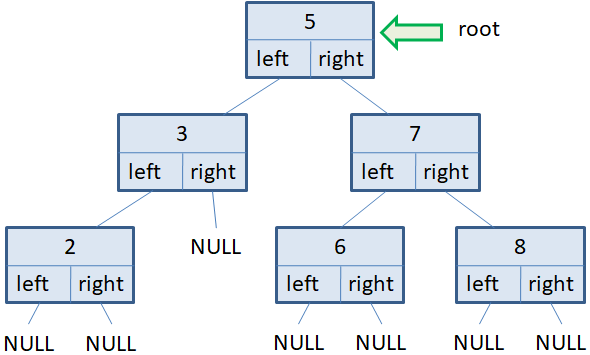
Давайте представим, что у нас имеется следующее двухуровневое бинарное дерево: На корневую вершину ведет указатель root. Создадим еще один вспомогательный указатель p на эту же вершину:
Изначально в списке только одна корневая вершина. Сформируем два цикла: первый будет работать, пока список вершин не пуст, то есть, пока в дереве имеются узлы текущего уровня; а второй будет перебирать вершины текущего уровня, выводить информацию на экран и формировать список следующего уровня:
while v: vn = [] for x in v: print(x.data) if x.left: vn += [x.left] if x.right: vn += [x.right] v = vn
В результате, сначала будет выведено значение 7 корневого узла. Затем, сформирован список vn из двух узлов следующего уровня в порядке слева-направо. После этого списку v присваивается новый сформированный список vn следующего уровня и на следующей итерации цикла while во вложенном цикле for будут перебираться уже вершины первого уровня. На экран выведутся значения 2 и 5. Снова сформируется список vn из вершин следующего второго уровня. И на следующей итерации цикла while будут выведены значения 3, 4 и 6. После этого список vn окажется пустым, следовательно, список v также будет пустой и цикл while завершит свою работу. Вот пример реализации алгоритма перебора вершин бинарного дерева в ширину в самом простом варианте. При этом мы обходим по всем узлам дерева ровно один раз.
Алгоритм обхода в глубину
Следующий тип алгоритмов – это обход дерева в глубину. Здесь мы проходим по определенной ветви до листовой вершины. Лучше всего показать этот ход на конкретном примере. Пусть у нас то же самое бинарное дерево. Начальная вершина, как всегда, корневая (root). Затем, мы должны для себя решить, по какой из двух ветвей идти в первую очередь, а по какой – во вторую. Я решил обойти дерево сначала по левой ветви, а затем, с возвратами проходить правые ветви. Это можно реализовать следующей рекурсивной функцией:
def show_tree(self, node): if node is None: return self.show_tree(node.left) print(node.data) self.show_tree(node.right)
Как она работает? Мы начинаем двигаться от корневого узла. Если он существует, то вызывается та же самая функция для левого узла. В результате, мы как бы попадаем в ту же самую функцию, только параметр node теперь является ссылкой на узел со значением 3. Здесь выполняется та же самая проверка: если узел существует, то по рекурсии мы снова переходим к следующему левому узлу. Это узел со значением 2. Снова делается проверка на его существование и, так как он существует, переходим к следующему левому узлу. Теперь параметр node принимает значение None (на рисунке NULL), рекурсия завершается и мы возвращаемся к прежнему вызову с параметром node узла 2. Это значение отображается на экране и делается попытка пройти по правой ветви. Так как справа объектов нет, то вызов текущей функции завершается и мы попадаем в функцию уровнем выше с параметром node на узел 3. Это значение 3 выводится на экран и делается попытка пройти по правой ветви. Ее нет, поэтому мы возвращаемся на уровень выше, то есть, к корневому узлу со значением 5. Это значение выводится на экран и далее мы переходим к правой вершине 7. Снова вызывается рекурсивная функция с параметром node на узел 7 и делается попытка пройти по левой ветви. Там имеется вершина со значение 6. Она выводится на экран с возвратом к функции узла 7. Затем, отображаем эту семерку на экран и переходит к левому узлу со значением 8. Это значение также отображается, после чего все вызовы рекурсивных функций завершаются. В результате мы на экране увидим следующие значения, записанные в вершинах бинарного дерева: 2, 3, 5, 6, 7, 8 Вы можете подумать, что такой возрастающий порядок значений получился чисто случайно. Однако нет. Если у нас имеется бинарное дерево сформированное по правилу добавления меньших значений в левую ветвь, а больших – в правую, то при обходе дерева в глубину в порядке: левое поддерево (L); промежуточная вершина (N); правое поддерево (R) всегда будет образовываться возрастающая последовательность чисел. Сокращенно такой алгоритм в глубину получил название LNR и относится к симметричному типу обхода. А если пройти сначала по правой ветви, затем вывести значение промежуточной вершины, а после пройти по левой ветви, то получим убывающую последовательность значений в бинарном дереве: 8, 7, 6, 5, 3, 2 Такой алгоритм сокращенно называется RNL и также является одним из видов симметричного обхода. Комбинируя различные варианты обхода и отображения значений вершин можно получать самые разнообразные вариации алгоритмов обхода в глубину.
Удаление вершин бинарного дерева
Теперь, когда мы с вами подробно разобрались в способах формирования бинарного дерева и алгоритмами обхода его вершин, остался один важный вопрос, связанный с удалением его узлов. Здесь возможны несколько типовых исходов.
Удаление листовых вершин
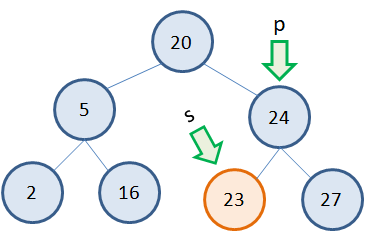
Самый простой случай, когда удаляется листовой узел дерева. Предположим, что это узел 23: Тогда, нам достаточно получить указатель p на родительский узел и указатель s на удаляемый узел. Сделать это очень просто, запоминая при обходе дерева предыдущую (родительскую) вершину и текущую. После этого ссылку, ведущую на удаляемый узел следует приравнять NULL и освободить память из под узла s:
Удаление узла с одним потомком
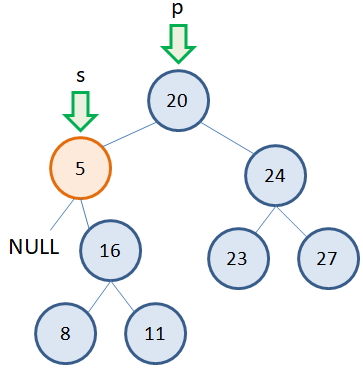
Также относительно просто обстоит ситуация, когда у удаляемого узла имеется один потомок (слева или справа). Например, нам нужно удалить узел 5, у которого один потомок справа: Здесь мы также должны иметь два указателя: p – на родительскую вершину; s – на удаляемую вершину. Затем, исключаем из дерева удаляемую вершину 5, меняя связь от родительской вершины 20 к вершине 16 (которая идет после удаляемой):
Причем, ситуация принципиально не меняется, если у удаляемой вершины один правый или левый потомок. Алгоритм удаления таких вершин работает похожим образом.
Удаление узла с двумя потомками
Несколько сложнее обстоит дело, когда у удаляемой вершины два потомка. Общая идея здесь такая. Сам узел не удаляется, меняется только его значение на новое. А новое берется как наименьшее из правой ветви. Например, если мы хотим удалить узел 5, то следует взять наименьшее значение 16 из правого поддерева. Записать его вместо 5, а листовой узел 16 просто удалить: 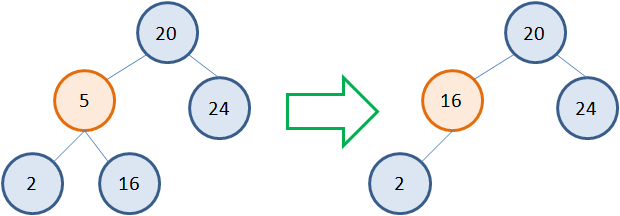 Но это если справа расположен листовой узел. А что если справа имеется полноценное поддерево с множеством вершин? Как быть в такой ситуации? По сути, также. Идея алгоритма остается прежней. Выбираем узел с наименьшим значением 11 в правом поддереве, заменяем 5 на 11 и удаляем листовой узел 11:
Но это если справа расположен листовой узел. А что если справа имеется полноценное поддерево с множеством вершин? Как быть в такой ситуации? По сути, также. Идея алгоритма остается прежней. Выбираем узел с наименьшим значением 11 в правом поддереве, заменяем 5 на 11 и удаляем листовой узел 11: 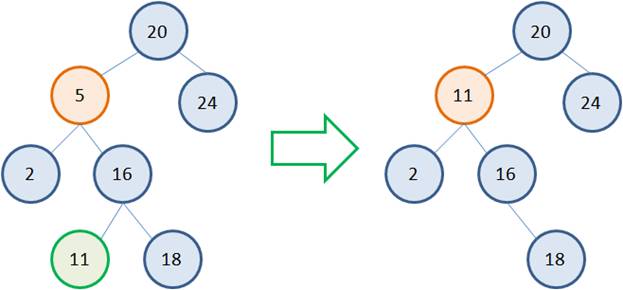 Но вершина с наименьшим значением в правом поддереве не всегда является листовой. Возможны и такие ситуации:
Но вершина с наименьшим значением в правом поддереве не всегда является листовой. Возможны и такие ситуации: 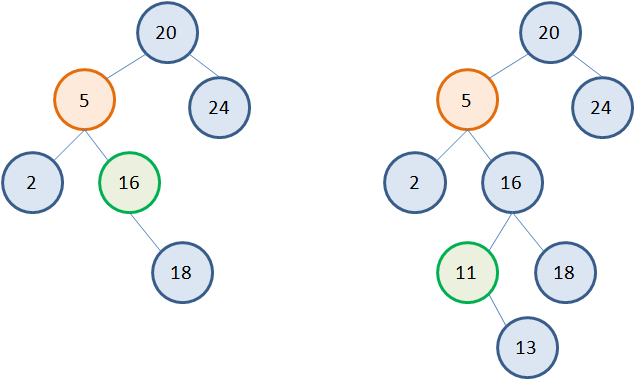 Однако можно заметить, что у узла с наименьшим значением может быть только один потомок справа. А значит, его удаление будет выполняться по алгоритму удаления вершин с одним потомком. Например, рассмотрим второе дерево. Нам потребуется три указателя: t – на удаляемую вершину (то есть, вершину, у которой будет меняться значение); s – на вершину с наименьшим значением в правом поддереве; p – на родительскую вершину для вершины s:
Однако можно заметить, что у узла с наименьшим значением может быть только один потомок справа. А значит, его удаление будет выполняться по алгоритму удаления вершин с одним потомком. Например, рассмотрим второе дерево. Нам потребуется три указателя: t – на удаляемую вершину (то есть, вершину, у которой будет меняться значение); s – на вершину с наименьшим значением в правом поддереве; p – на родительскую вершину для вершины s: 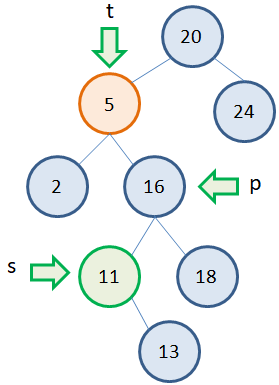 Затем, мы меняем значение вершины 5 на 11:
Затем, мы меняем значение вершины 5 на 11:
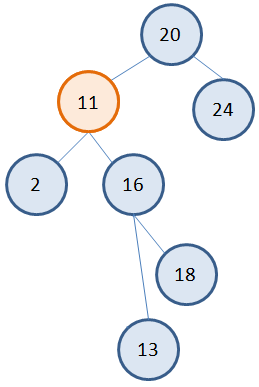
В результате получаем дерево: Вот основные типовые варианты удаления вершин в бинарном дереве:
- удаление листового узла;
- удаление узла с одним потомком (правым или левым);
- удаление узла с двумя потомками.
На следующем занятии, в качестве примера, реализуем бинарное дерево на языке Python, чтобы вы во всех деталях понимали принцип его работы. Курс по структурам данных: https://stepik.org/a/134212
Источник