16. Построение дерева синтаксического разбора.
Дерево разбора может рассматриваться как графическое представление порождения, из которого удалена информация о порядке замещения не терминалов.
Каждый внутренний узел дерева представляет применение продукции.
Внутренний узел дерева помечен нетерминалом А из заголовка соответствующей продукции, а дочерние узлы слева направо символами из тела продукции, использованные в порождении для замены А.
Например, дерево для разбора – (id+id):
Листья дерева разбора не терминальными или терминальными и будучи прочитаны слева на право, образуют сентенциальную форму называемую кроной или границей дерева.
Для того что бы увидеть связь между порождениями и деревьями разбора рассмотрим произвольное приведение. α1 → α2 → … → αn
Где альфа 1 отдельный не терминал А.
Для каждой сентенциальной формы альфа 1 можно построить дерево разбора, кроной которого является альфа 1 этот процесс представляет собой индукцию по i.
Пример, последовательность деревьев разбора:
Для моделирования этого шага корню Е в начало дерева добавляют два дочерних узла помеченных «-» и «Е».
2) – E => — (E) добавляют 3 дочерних узла, помеченных (, Е, ) к листу Е для получения дерева с кроной – (Е).
Продолжая построение описываемым способом получается полноценное дерево разбора.
Т.к. дерево разбора игнорирует порядок, в котором производилось замещение символов в сентенциальной форме, между порождениями и деревьями возникает соотношение «многих к одному».
Каждое дерево связано с единственным левым и единственным правым порождением.
17. Нисходящий синтаксический анализ
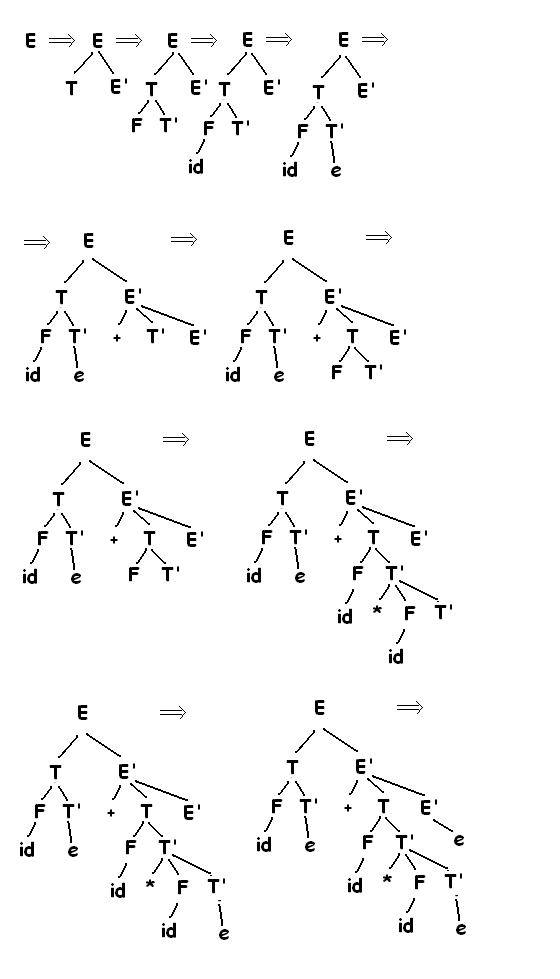
Можно рассмотреть как поиск левого порождения входящей строки. Рассмотрим последовательность построений деревьев разбора для входящей строки (id+id)*id, представляющий собой нисходящий синтаксический анализ, построенный в соответствии с грамматикой:
Эта последовательность деревьев соответствует левому порождению входящей строки. На каждом шаге нисходящего синтаксического анализа ключеваой проблемой является определение продукции, применимой для нетерминалов, например А. Когда А продукция выбрана, остальные части процесса синтаксического анализа состоят из проверки соответвствий терминальных символов в теле продукции входящей строки. В рассмотренном примере строится дерево с двумя узлами, помеченными E’, в первом (в прямом) порядке обхода узла Е’ выбирается продукция
E’ -> +TE’, во втором E’ -> e. Синтаксический анализатор может выбрать нужную E’ продукцию, рассматривающую очередной входящий символ. Класс Грамматик для которых можно построить синтаксический анализатор, просматривающий k-символов во входящем потоке называется классом LL(k).
Метод рекурсивного спуска
Программа синтаксического анализатора методом рекурсивного спуска состоит из набора процедур по одной для каждого нетерминала. Работа программы начинается с вызова процедуры для стартового символа и успешно заканчивается в случае сканирования всей входящей строки.
Типичная процедура для нетерминала низходящего анализатора
If (Xi-нетерминал) Вызов процедуры Xi();
else if(Xi равно текущему входному символу a)
Переход к следующему входному символу
Этот псевдокод недетерминирован т.к. он начинается с выбором А-продукции не указанным способом.
Рекурсивный способ в общем случае может потребовать выполнения возврата т.е. повторения сканирования входного потока. При анализе синтаксической конструкции языка программирования возврат требуется редко. В ситуациях , наподобие, синтаксического анализа естественного языка возврат не слишком эффективен и предпочтительней являются табличные методы. Чтобы разрешить возврат код в примере должен быть модифицирован:
- Невозможно выбрать единую А-продукцию в строке (1), поэтому требуется испытывать каждую из нескольких продукций в некотором порядке.
- Ошибка в строке (*) не является окончательной и предполагает возворат к строке (1) и испытание другой А-продукции.
Объявлять о найденной во входной строке ошибке можно только в том случае, если больше не имеется непроверенных А-продукций.
Чтобы построить дерево разбора для входной строки ω-cod начинают с дерева, состоящего из единичного узла с меткой S и указателя входного потока, указывающего на С или первый символ ω.
S имеет единичную продукцию, поэтому ее используют для разворачивания и получения дерева.
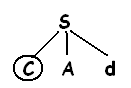
Соответствует первому символу входного потока ω, поэтому указатель входного потока перемещается к а-второму символу ω и рассматривается следующий лист, помеченный А.
Затем разворачивается А с использованием альтернативы А -> ab и получаем таким образом дерево, показанное на рис.
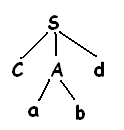
Имеется совпадение второго входного символа а, поэтому выполняется переход к третьему символу d и сравнивают его с очередным листком b. Т.к. b не соответствует d, то сообщается об ошибке и происходит возврат к А.
Чтобы выяснить нет ли альтернативной продукции, которая не была проверена до этого времени, вернувшись к а необходимо отбросить указатель входного потока так, чтобы он указывал на позицию 2, в которой указатель находится, когда впервые столкнулся с а. Это означает что процедура для а должна хранить указатель на входной поток в локальной переменной.
Вторая альтернатива для а дает дерево разбора:
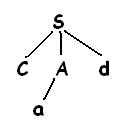
Лист а соответствует второму символу ω, а лист d – третьему символу. Т.к. построено дерево разбора для входящей строки ω, то алгоритм завершает работу и сообщает об успешном выполнении синтаксического анализа и построении дерева разбора. Левосторонняя грамматика может привести синтаксический анализатор, работающий методом рекурсивного спуска к бесконечному циклу, т.е. когда пытаются проверить нетерминал а, то в конечном счете можно найти этот же нетерминал а и перейти к попытке развернуть а, так и не взяв ни одного символа из входного потока.
Источник
Лекция 6 Определение синтаксического разбора
В предыдущих разделах мы уже неоднократно сталкивались с понятием синтаксического анализа при изучении распознавателей и сканеров. До сих пор под этим понятием подразумевался процесс анализа символьных цепочек с целью распознавания “правильных” или “неправильных” языковых конструкций. При этом не требовалось выдачи информации о структуре самой конструкции. Основная же функция анализатора в фазе синтаксического анализа состоит в получении и представлении этой информации в виде дерева разбора или другой структуры. Эта структура называется промежуточной программой и используется для генерации кода.
Синтаксический анализ, в ходе которого уясняется структура анализируемой цепочки лексем, называется синтаксическим разбором. Выделяют два вида разбора. Введем их формальное определение.
Определение. Пусть G=(N,,P,S) — КС-грамматика, правила которой пронумерованы 1,2, . р, (NU)*. Тогда
левым разбором цепочки называется последовательность правил, примененных при левом выводе цепочки из S;
правым разбором цепочки называется обращение последовательности правил, примененных при правом выводе цепочки из S.
Эти разборы можно представить в виде последовательности номеров из множества 1, 2, . . . , р>.
Пример Рассмотрим грамматику с такой нумерацией правил:
а так же цепочку a*(a+a) и ее левый и правый разборы. Имеем:
левый вывод: Е2 Т3 Т*F4 F*F6a*F5 a*(E)1 a*(E+T)2 a*(T+T)4 a*(F+T)6 a*(a+T)4a*(a+F)6 a*(a+a) ;
левый разбор: 23465124646;
правый вывод: Е 2Т 3Т*F 5 T*(E) 1 T*(E+T) 4 T*(E+F) 6 T*(E+a) 2 T*(T+a) 4 T*(F+a) 6 T*(a+a) 4 F*(a+a) 6 a*(a+a);
правый разбор: 64642641532.
Понятию разбора можно дать и графическую интерпретацию: говорят, что для некоторой КС-грамматики G цепочка L(G) разобрана, или проанализирована, если известно одно (или, быть может, все) из ее деревьев выводов. При трансляции такое дерево можно “физически” построить в памяти машины.
Нисходящий и восходящий разборы
Большинство методов синтаксического анализа делят на два класса разбора, – нисходящего и восходящего. Анализаторы, реализующие методы нисходящего разбора, выдают на выходе левые разборы и называются левыми анализаторами, а реализующие методы восходящего разбора, выдают правые разборы и называются правыми анализаторами. Оказывается, что эти анализаторы можно моделировать при помощи соответствующих МП — преобразователей.
В литературе отмечается, что при сравнении эффективности стратегий нисходящего и восходящего разбора, ни одной из них нельзя отдать окончательного предпочтения. Для приобретения навыков построения анализатора в дальнейшем мы будем рассматривать только нисходящие методы, а восходящие методы рассмотрим только на уровне стратегии. Рассмотрим стратегию нисходящего разбора.
Пусть = i1 . in — левый разбор цепочки L(G), где G — КС-грамматика. Зная можно построить левый вывод и соответствующее дерево вывода цепочки .
Пример 5.2. Рассмотрим грамматику G с правилами:
(1) Е Е + Т,
(3) Т Т * F,
и цепочку =a*(a+a). Если = 23465124646, то дерево вывода имеет вид, показанный на рис.5.1.
С деревом вывода тесно связано дерево разбора. Пока мы не будем делать различий между ними, но дадим соответствующее разъяснение в следующей главе.
Изменим теперь исходные данные. Пусть задана грамматика G=(N,,P,S) с занумерованными правилами и цепочка L(G). Требуется построить ее левый разбор , т.е. решить задачу разбора. Можно считать, что нам известны корень и крона дерева. Стратегия нисходящего разбора заключается в попытках построения дерева, начиная с его корня и двигаясь сверху вниз, слева направо, восполняя недостающие вершины, пока не будет достигнута крона дерева. На каждом шаге выбирается только одно правило грамматики (и запоминается его номер), которое приводит к построению очередной внутренней вершины.
Очевидно, что последовательность номеров этих правил, получаемая по завершению процедуры построения дерева, и есть левый разбор цепочки .
Левый анализатор можно моделировать при помощи МП -преобразователя.
Определение. Пусть G=(N, ,P,S) – КС-грамматика и ее правила пронумерованы от 1 до р. Определим левый анализатор как недетерминированный МП — преобразователь:
Ml=(, , N , ,, q, S, ),
где определяется следующим образом:
Пример . Пусть G-грамматика из примера и
(q, b, b)= для всех b.
Пусть на входе анализатора цепочка =a+a*a, и начальная конфигурация анализатора имеет вид (q, a+a*a, E, e).
В результате потактного анализа входной цепочки анализатор проделает траекторию, которая имеет вид дерева, аналогично траектории недетерминированного конечного автомата (см. гл. 2). Мы предлагаем читателю построить эту траекторию самостоятельно. В этой древовидной траектории только один путь приведет к заключительной конфигурации, имеющей вид:
(q, e, e, 12463466).
Легко убедиться, что выходная цепочка =12463466 — левый разбор входной цепочки .
Рассмотрим теперь стратегию восходящего разбора. Эта стратегия так же предполагает реконструирование дерева вывода, но восполнение вершин начинается снизу — с кроны дерева, а движение происходит вверх и слева направо — к корню дерева.
При построении очередной вершины запоминается номер применяемого правила грамматики. Получаемая в результате последовательность номеров представляет правый разбор входной цепочки , соответствующей кроне дерева.
Стратегия восходящего разбора реализуется правым анализатором, моделью которого также служит МП — преобразователь (но здесь он будет расширенным). Мы не будем вводить определение правого анализатора, поскольку в дальнейшем будут рассматриваться только левые анализаторы.
Источник