5.3.4 Интерактивное дерево решений
До этого мы получали дерево, которое строилось автоматическим способом, то есть алгоритм на каждом шаге выбирал атрибут для разбиения по заданному критерию. Известно, что алгоритмы построения деревьев «жадные», поэтому не факт, что итоговое дерево будет наилучшим. В то же время иногда имеются экспертные знания, которые позволяют «вмешаться» в процесс формирования дерева и выбора атрибутов, а также порогов для разбиения. Возможно, это и не повысит точность модели, но правила станут более логичными, с точки зрения экспертов.
Кредитный скоринг представляет собой тот самый случай, когда банковские аналитики имеют определенные знания и хотят, чтобы в модели ветвление по атрибутам осуществлялось в определенном порядке. Например, если имеются атрибуты Наличие квартиры и Стоимость квартиры, то разумно сразу после первого рассмотреть второй. Еще пример: после суммы кредита сразу желательно проанализировать первоначальный взнос.
В аналитической платформе Deductor имеется возможность построения интерактивных деревьев решений. Зададимся целью построить скоринговую модель на прежней выборке, приняв во внимание следующие пожелания экспертов.
- Первым атрибутом, по которому анализируют заемщика, должен быть атрибут Кредитная история.
- Далее необходимо рассмотреть коэффициент О/Д. Всех клиентов нужно разбить на три категории: заемщики с низким О/Д (до 20 %), с умеренным (от 20 до 40 %) и высоким (от 40 %).
Добавьте в сценарий новый узел дерева решений и на пятом шаге мастера поставьте переключатель в позицию Интерактивный режим.
В результате открывшийся визуализатор Дерево решений не будет содержать ни одного узла. На панели инструментов нажмите кнопку Разбить текущий узел на подузлы. откроется соответствующее окно (рис. 54.22).
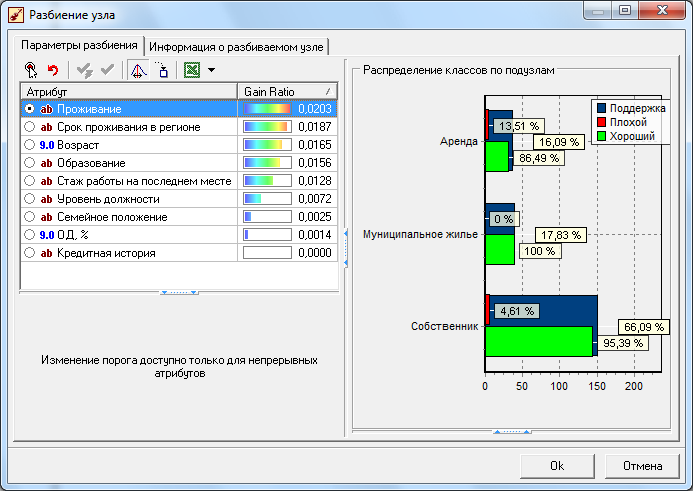
Рисунок 5.22 – Окно выбора атрибута для разбиения в интерактивном режиме: первый шаг
Слева в списке выводятся все атрибуты вместе с рассчитанными значениями прироста информации Gain Ratio, а справа — диаграммы распределения классов по подузлам. По умолчанию предлагается атрибут с максимальным значением Gain Ratio, но его можно переопределить. В данном случае ничего делать не нужно, поскольку разбиение и так начнется по атрибуту Кредитная история. Нажатие кнопки Ок приведет к тому, что в дерево добавится три узла этого атрибута со значениями нет данных, отрицательная, положительная.
Продолжим разбиение дальше, выбрав узел
Кредитная история = нет данных (рис. 5.23).
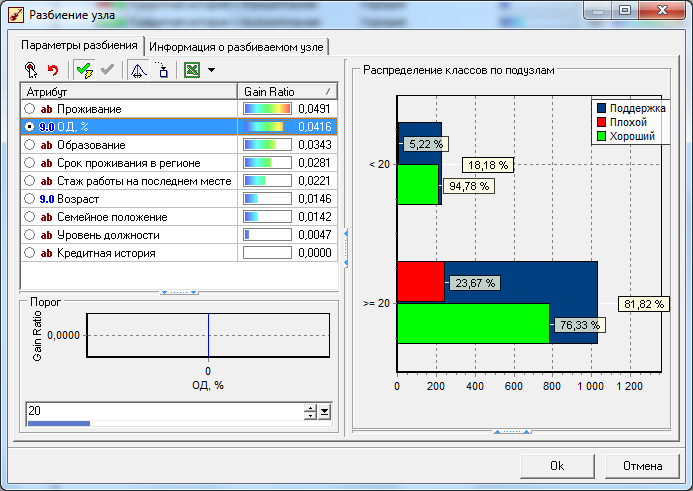
Рисунок 5.23 — – Окно выбора атрибута для разбиения в интерактивном режиме: второй шаг
Здесь в качестве оптимального с точки зрения прироста информации предлагается атрибут Проживание. Переопределите его на ОД, %, указав в нижней части окна порог, равный 20. Затем для узла ОД, % >20 снова выберите разбиение по ОД, %, но уже с порогом 40, после чего нажмите кнопку Построить дерево, начиная с текущего узла. В результате ветвь дерева будет полностью готова (рис. 5.24).
Аналогичным образом достраивается дерево для оставшихся узлов. Качество классификации, как и прежде, можно оценивать через таблицы сопряженности.
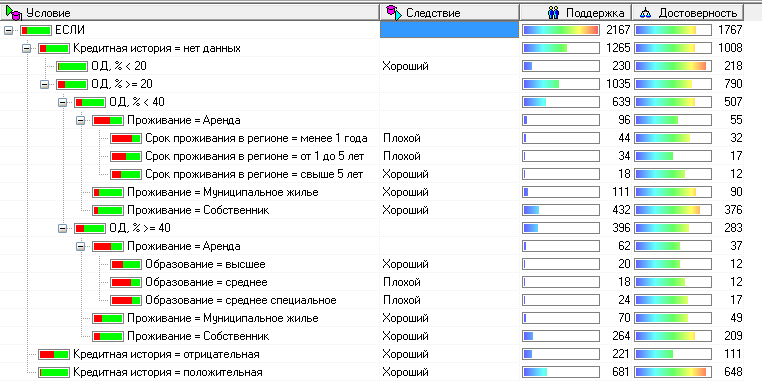
Рисунок 5.24 – Дерево решений, построенное в интерактивном режиме
Источник
Решение задачи в Deductor Studio
Цель:сформировать знания о сущности методики Data Mining, изучить процесс построения дерева решений для различного класса экономических задач на базе на основе аналитической платформы Deductor Academic.
Время: 2 часа.
1. Правила оформления и представления отчета по практической работе.
2. Построение дерева решений для оценки кредитоспособности заемщика.
3. Построение дерева решений для классификации депутатского корпуса.
Правила оформления и представления отчета по практической работе
Отчет по практической работе предоставляется в письменной форме в виде текстового документа с именем Ваша_Фамилия_Номер_группы_Пр.р.13.docx. Он должен состоять из следующих частей:
— ФИО студента, Номер группы, Дата проведения занятия;
— номер и название практической работы;
— для каждой задачи: вставить постановку задачи и скриншоты результатов выполнения.
Построение дерева решений для оценки кредитоспособности заемщика
Для выполнения практической работы необходимо скачать по следующей ссылке программу Deductor Academic https://basegroup.ru/deductor/download и установить, если она у вас не установлена.
Постановка задачи 1. С использованием метода деревьев решений, требуется построить классификационную модель, позволяющую определять, можно ли выдавать заемщику кредит или нет (относить заемщика к одному из заранее известных классов — классу платежеспособных или к классу неплатежеспособных).
Для обучения модели имеется выборка хронологических данных, состоящая из 1000 записей. Каждая запись выборки содержит характеристики заемщика (№ Паспорта, ФИО, Адрес, Размер ссуды, Срок ссуды, Цель ссуды, Среднемесячный доход, Среднемесячный расход, Основное направление расходов, Наличие недвижимости, Наличие автотранспорта, Наличие банковского счета, Наличие страховки, Название организации, Отраслевая принадлежность предприятия, Срок работы на данном предприятии, Направление деятельности заемщика, Срок работы на данном направлении, Пол, Семейное положение, Количество лет, Количество иждивенцев, Срок проживания в данной местности, Обеспеченность займа) и параметр, показывающий, были ли у клиента просрочки или невозвраты денег (Давать кредит).
По своей сути, эта выборка является проверенными временем данными, на основании которых можно построить и обучить модель дерева решений, которая сможет в дальнейшем выполнить классификацию вновь появляющихся заемщиков.
Решение задачи в Deductor Studio
Шаг 1. Загрузите данные из файла CreditSample.txt (прилагается к практической работе), входящего в состав примеров Deductor Studio.
Шаг 2. Запустите Мастер обработки (рисунок 1.1), выберите Дерево решений и нажмите Далее.

Рисунок 1.1 — Мастер обработки
Поля «ФИО», «Адрес» и «Название организации» определены алгоритмом уже до начала построения дерева решений как непригодные по причине практической уникальности каждого из значений. Поле «№ Паспорта» нам также не пригодится, поэтому назначьте его не используемым.

Рисунок 1.2 — Настройка назначений столбцов
Целевым полем является поле «Давать кредит», в котором отображаются значения «Да» (True) и «Нет» (False). Эти значения можно интерпретировать следующим образом: «Нет» — плательщик либо сильно просрочил с платежами, либо не вернул часть денег, «Да» — противоположность «Нет» (рисунок 1.2).
Дальнейшие настройки процесса построения и отображения дерева решений выполните, как показано на рисунках 1.3-1.7.

Рисунок 1.3 — Разбиение исходного набора данных на подмножества

Рисунок 1.4 — Выбор способа построения дерева решений

Рисунок 1.5 — Настройка параметров обучения дерева решений

Рисунок 1.6 — Построение дерева решений

Рисунок 1.7 — Определение способов отображения
После окончания процесса построения дерева решений получаем модель оценки кредитоспособности физических лиц (рисунок 1.8). Модель описывает ситуацию, относящуюся к определенному банку, и имеет иерархическую структуру правил — дерево решений.

Рисунок 1.8 — Модель оценки кредитоспособности физических лиц
Шаг 3. Нажав на вкладке Дерево решений пиктограмму с изображением очков , получите записанные на естественном языке правила, определяющие принадлежность заемщика к той или иной группе (рисунок 1.9).

Рисунок 1.9 — Получение правил
Примеры правил, построенных на основе результатов работы модели:

Шаг 4. Перейдите на вкладку Правила и просмотрите расчетные значения поддержки и достоверности полученных правил (рисунок 1.10).
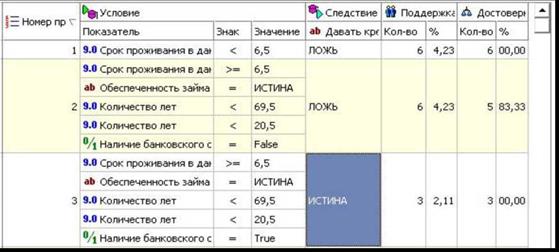
Рисунок 1.10 — Расчетные значения поддержки и достоверности
Шаг 5. Используйте данную модель для определения принадлежности потенциального заемщика к одному из двух классов (платежеспособен, неплатежеспособен). Для этого воспользуйтесь вкладкой Что-если, где, изменяя значения параметров, можно получить ответ на вопрос: «Давать ли кредит?» (рисунок 1.11).

Рисунок 1.11 — Вкладка Что-если
Таким образом, такой подход позволяет строить модели классификации (дерево решений) с минимальным вмешательством человека (модели самоадаптируемые). При этом достоверность результата достаточно высока за счет того, что алгоритм выбирает наиболее значимые факторы для определения конечного ответа. Кроме того, полученный результат является статистически обоснованным.
Приведенный выше пример – это, достаточно грубый вариант того, как можно использовать технологии обработки информации, в частности, деревья решений, для достижения поставленной задачи: уменьшения риска при операциях кредитования физических лиц. Хотя и при таком первом приближении наблюдаются положительные результаты. Дальнейшие усовершенствования могут затрагивать такие моменты, как:
— более точный подбор определяющих заемщика факторов;
— изменение самой постановки задачи, так, например, вместо двух значений целевого параметра, можно использовать более детальную информацию (Вернул/Не вернул/Не вовремя) или использовать в качестве целевого значения вероятность того, что деньги выплачены вовремя;
— в данном примере ни слова не говорится об очистке данных, хотя, как показывает практика, использование предобработки исходных данных позволяет значительно улучшить качество результата и является важным этапом при комплексном подходе к решению любой задачи анализа данных.
Изменяя значения параметров вкладки Что-если, можно выполнить классификацию клиентов и тем самым получить ответ на вопрос: «Давать ли кредит?».
На вкладке Дерево решений можно получить записанные на естественном языке правила, определяющие принадлежность заемщика к той или иной группе (классу).
Понравилась статья? Добавь ее в закладку (CTRL+D) и не забудь поделиться с друзьями:
Источник
Порядок выполнения работы.
1. Запустить аналитическое приложение Deductor Studio и загрузить набор данных по указанию преподавателя».
2. Открыть Мастер обработки и в разделе Data Mining в списке доступных методов обработки выбрать пункт «Дерево решений».
3. На 2-м шаге Мастера обработки установить назначение поле набора данных.

Рисунок 3. Настройка назначения полей.
4. На 3-м шаге установить размеры обучающего и тестового множеств 90% и 10% соответственно, способ отбора – случайно (рис. 4).

Рисунок 4. Настройка размеров обучающего и тестового множеств.
5. На 4-м шаге Мастера настроить параметры обучения дерева решений:
— параметры ранней остановки: минимальное количество примеров в узле, при котором будет создан новый узел – 2, флажок «Строить дерево с более достоверными правилами в ущерб компактности» — установить;
— отсечение узлов дерева – отключить, сбросив соответствующий флажок в разделе Параметры отсечения.
Таким образом, мы настроили алгоритм обучения на построение «полного» дерева, содержащее максимальное число правил.
6. На 5-м шаге запустить процесс обучения и проконтролировать его результаты (рис. 5): зафиксировать процент распознанных примеров на обучающем и тестовом множестве, сделать вывод о результатах обучения; зафиксировать число правил и узлов в построенном дереве. Темп обновления установит равным 1.

Рисунок 5. Запуск процесса обучения и контроль его результатов.
7. На 6-м шаге Мастера обработки выбрать способы визуализации: Дерево решений, Обучающий набор, Правила, Таблица сопряженности.

8. По внешнему виду дерева решений визуально оценить его сложность и интерпретируемость. Схематично зарисовать полученное дерево решений и для каждого узла зафиксировать число примеров каждого класса, попавшее в него. Для этого выделить узел щелчком мыши и щелкнуть по кнопке , в результате чего внизу откроется список попавших в данный узел объектов. Сделать вывод, какое из правил является самым эффективным (то, которое распределит в узел наибольшее число примеров одного класса). По таблице сопряженности определить характер ошибки.
9. По правилам, извлеченным из дерева решений (вкладка «Правила» в верхней части окна), сделать вывод о влиянии тех или иных показателей на урожайность, например, какая урожайность связана с низкой кислотностью, а какая – с высоки содержанием калия и т.д.).
10. По таблице сопряженности определить, сколько ошибок классификации допустила модель и в чем они заключаются.
11. Построить зависимость числа распознанных примеров и узлов дерева от минимально допустимого числа примеров в узле. Для этого повторить пункты 5 -7, изменяя минимально допустимое число примеров в узле от 2 до 10 и каждый раз регистрируя число правильно и не правильно распознанных примеров. Результаты свести в таблицу вида:
Минимально допустимое число примеров Nmin
Источник