Алгоритм Хаффмана
Алгоритм Хаффмана (англ. Huffman’s algorithm) — алгоритм оптимального префиксного кодирования алфавита. Был разработан в 1952 году аспирантом Массачусетского технологического института Дэвидом Хаффманом при написании им курсовой работы. Используется во многих программах сжатия данных, например, PKZIP 2, LZH и др.
Определение
- [math]c_[/math] не является префиксом для [math]c_[/math] , при [math]i \ne j[/math] ,
- cумма [math]\sum\limits_ w_\cdot |c_|[/math] минимальна ( [math]|c_|[/math] — длина кода [math]c_[/math] ),
Алгоритм построения бинарного кода Хаффмана
Построение кода Хаффмана сводится к построению соответствующего бинарного дерева по следующему алгоритму:
- Составим список кодируемых символов, при этом будем рассматривать один символ как дерево, состоящее из одного элемента c весом, равным частоте появления символа в строке.
- Из списка выберем два узла с наименьшим весом.
- Сформируем новый узел с весом, равным сумме весов выбранных узлов, и присоединим к нему два выбранных узла в качестве детей.
- Добавим к списку только что сформированный узел вместо двух объединенных узлов.
- Если в списке больше одного узла, то повторим пункты со второго по пятый.
Время работы
Если сортировать элементы после каждого суммирования или использовать приоритетную очередь, то алгоритм будет работать за время [math]O(N \log N)[/math] .Такую асимптотику можно улучшить до [math]O(N)[/math] , используя обычные массивы.
Пример
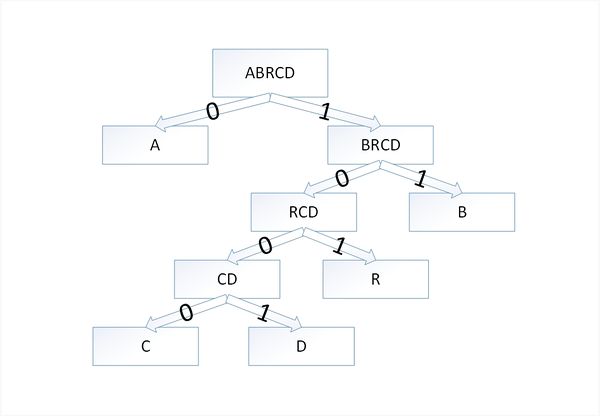
Закодируем слово [math]abracadabra[/math] . Тогда алфавит будет [math]A= \ [/math] , а набор весов (частота появления символов алфавита в кодируемом слове) [math]W=\[/math] :
В дереве Хаффмана будет [math]5[/math] узлов:
| Узел | a | b | r | с | d |
|---|---|---|---|---|---|
| Вес | 5 | 2 | 2 | 1 | 1 |
По алгоритму возьмем два символа с наименьшей частотой — это [math]c[/math] и [math]d[/math] . Сформируем из них новый узел [math]cd[/math] весом [math]2[/math] и добавим его к списку узлов:
| Узел | a | b | r | cd |
|---|---|---|---|---|
| Вес | 5 | 2 | 2 | 2 |
Затем опять объединим в один узел два минимальных по весу узла — [math]r[/math] и [math]cd[/math] :
Еще раз повторим эту же операцию, но для узлов [math]rcd[/math] и [math]b[/math] :
На последнем шаге объединим два узла — [math]brcd[/math] и [math]a[/math] :
Остался один узел, значит, мы пришли к корню дерева Хаффмана (смотри рисунок). Теперь для каждого символа выберем кодовое слово (бинарная последовательность, обозначающая путь по дереву к этому символу от корня):
| Символ | a | b | r | с | d |
|---|---|---|---|---|---|
| Код | 0 | 11 | 101 | 1000 | 1001 |
Таким образом, закодированное слово [math]abracadabra[/math] будет выглядеть как [math]01110101000010010111010[/math] . Длина закодированного слова — [math]23[/math] бита. Стоит заметить, что если бы мы использовали алгоритм кодирования с одинаковой длиной всех кодовых слов, то закодированное слово заняло бы [math]33[/math] бита, что существенно больше.
Корректность алгоритма Хаффмана
Чтобы доказать корректность алгоритма Хаффмана, покажем, что в задаче о построении оптимального префиксного кода проявляются свойства жадного выбора и оптимальной подструктуры. В сформулированной ниже лемме показано соблюдение свойства жадного выбора.
Пусть [math]C[/math] — алфавит, каждый символ [math]c \in C[/math] которого встречается с частотой [math]f[c][/math] . Пусть [math]x[/math] и [math]y[/math] — два символа алфавита [math]C[/math] с самыми низкими частотами. Тогда для алфавита [math]C[/math] существует оптимальный префиксный код, кодовые слова символов [math]x[/math] и [math]y[/math] в котором имеют одинаковую максимальную длину и отличаются лишь последним битом.
Возьмем дерево [math]T[/math] , представляющее произвольный оптимальный префиксный код для алфавита [math]C[/math] . Преобразуем его в дерево, представляющее другой оптимальный префиксный код, в котором символы [math]x[/math] и [math]y[/math] — листья с общим родительским узлом, находящиеся на максимальной глубине.
Пусть символы [math]a[/math] и [math]b[/math] имеют общий родительский узел и находятся на максимальной глубине дерева [math]T[/math] . Предположим, что [math]f[a] \leqslant f[b][/math] и [math]f[x] \leqslant f[y][/math] . Так как [math]f[x][/math] и [math]f[y][/math] — две наименьшие частоты, а [math]f[a][/math] и [math]f[b][/math] — две произвольные частоты, то выполняются отношения [math]f[x] \leqslant f[a][/math] и [math]f[y] \leqslant f[b][/math] . Пусть дерево [math]T'[/math] — дерево, полученное из [math]T[/math] путем перестановки листьев [math]a[/math] и [math]x[/math] , а дерево [math]T»[/math] — дерево полученное из [math]T'[/math] перестановкой листьев [math]b[/math] и [math]y[/math] . Разность стоимостей деревьев [math]T[/math] и [math]T'[/math] равна:
[math]B(T) — B(T’) = \sum\limits_ f(c)d_T(c) — \sum\limits_ f(c)d_(c) = (f[a] — f[x])(d_T(a) — d_T(x)),[/math]
что больше либо равно [math]0[/math] , так как величины [math]f[a] — f[x][/math] и [math]d_T(a) — d_T(x)[/math] неотрицательны. Величина [math]f[a] — f[x][/math] неотрицательна, потому что [math]x[/math] — лист с минимальной частотой, а величина [math]d_T(a) — d_T(x)[/math] является неотрицательной, так как лист [math]a[/math] находится на максимальной глубине в дереве [math]T[/math] . Точно так же перестановка листьев [math]y[/math] и [math]b[/math] не будет приводить к увеличению стоимости. Таким образом, разность [math]B(T’) — B(T»)[/math] тоже будет неотрицательной.
Пусть дан алфавит [math]C[/math] , в котором для каждого символа [math]c \in C[/math] определены частоты [math]f[c][/math] . Пусть [math]x[/math] и [math]y[/math] — два символа из алфавита [math]C[/math] с минимальными частотами. Пусть [math]C'[/math] — алфавит, полученный из алфавита [math]C[/math] путем удаления символов [math]x[/math] и [math]y[/math] и добавления нового символа [math]z[/math] , так что [math]C’ = C \backslash \ < x, y \>\cup
Сначала покажем, что стоимость [math]B(T)[/math] дерева [math]T[/math] может быть выражена через стоимость [math]B(T’)[/math] дерева [math]T'[/math] . Для каждого символа [math]c \in C \backslash \[/math] верно [math]d_T(C) = d_[/math] , значит, [math]f[c]d_T(c) = f[c]d_(c)[/math] . Так как [math]d_T(x) = d_T(y) = d_ (z) + 1[/math] , то
[math]f[x]d_T(x) + f[y]d_T(y) = (f[x] + f[y])(d_(z) + 1) = f[z]d_(z) + (f[x] + f[y])[/math]
Докажем лемму от противного. Предположим, что дерево [math]T[/math] не представляет оптимальный префиксный код для алфавита [math]C[/math] . Тогда существует дерево [math]T»[/math] такое, что [math]B(T») \lt B(T)[/math] . Согласно лемме (1), элементы [math]x[/math] и [math]y[/math] можно считать дочерними элементами одного узла. Пусть дерево [math]T»'[/math] получено из дерева [math]T»[/math] заменой элементов [math]x[/math] и [math]y[/math] листом [math]z[/math] с частотой [math]f[z] = f[x] + f[y][/math] . Тогда
[math]B(T»’) = B(T») — f[x] — f[y] \lt B(T) — f[x] — f[y] = B(T’)[/math] ,
См. также
Источники информации
- Томас Х. Кормен, Чарльз И. Лейзерсон, Рональд Л. Ривест, Клиффорд Штайн. Алгоритмы: построение и анализ — 2-е изд. — М.: «Вильямс», 2007. — с. 459. — ISBN 5-8489-0857-4
- Wikipedia — Huffman coding
- Википедия — Бинарное дерево
- Википедия — Префиксный код
Источник
Код Хаффмана
Вот калькулятор, который рассчитывает коды Хаффмана для заданной вероятности символов.
Немного теории под калькулятором.
Код Хаффмана
Таблица вероятности символов
Таблица вероятности символов
Импортировать данные Ошибка импорта
Для разделения полей можно использовать один из этих символов: Tab, «;» или «,» Пример: Lorem ipsum;50.5
Алгоритм Хаффмана — адаптивный жадный алгоритм оптимального префиксного кодирования алфавита с минимальной избыточностью. Был разработан в 1952 году аспирантом Массачусетского технологического института Дэвидом Хаффманом при написании им курсовой работы. В настоящее время используется во многих программах сжатия данных.
Этот метод кодирования состоит из двух основных этапов:
Построение оптимального кодового дерева.
Построение отображения код-символ на основе построенного дерева.
Идея алгоритма состоит в следующем: зная вероятности символов в сообщении, можно описать процедуру построения кодов переменной длины, состоящих из целого количества битов. Символам с большей вероятностью ставятся в соответствие более короткие коды. Коды Хаффмана обладают свойством префиксности (т. е. ни одно кодовое слово не является префиксом другого), что позволяет однозначно их декодировать.
Классический алгоритм Хаффмана на входе получает таблицу частот встречаемости символов в сообщении. Далее на основании этой таблицы строится дерево кодирования Хаффмана (Н-дерево).
- Символы входного алфавита образуют список свободных узлов. Каждый лист имеет вес, который может быть равен либо вероятности, либо количеству вхождений символа в сжимаемое сообщение.
- Выбираются два свободных узла дерева с наименьшими весами.
- Создается их родитель с весом, равным их суммарному весу.
- Родитель добавляется в список свободных узлов, а два его потомка удаляются из этого списка.
- Одной дуге, выходящей из родителя, ставится в соответствие бит 1, другой — бит 0.
- Шаги, начиная со второго, повторяются до тех пор, пока в списке свободных узлов не останется только один свободный узел. Он и будет считаться корнем дерева.
Этот процесс можно представить как построение дерева, корень которого — символ с суммой вероятностей объединенных символов, получившийся при объединении символов из последнего шага, его n0 потомков — символы из предыдущего шага и т. д.
Чтобы определить код для каждого из символов, входящих в сообщение, мы должны пройти путь от корня до листа дерева, соответствующего текущему символу, накапливая биты при перемещении по ветвям дерева (первая ветвь в пути соответствует младшему биту). Полученная таким образом последовательность битов является кодом данного символа, записанным в обратном порядке.
Источник