- 3. Синтаксический анализ
- Документация
- Порядок выполнения работы
- Пример
- Часть 1
- Часть 2
- Варианты проектирования AST
- Гомогенное дерево (Homogeneous AST)
- Нормализованное гетерогенное дерево (Normalized Heterogeneous AST)
- Денормализованное гетерогенное дерево (Irregular Heterogeneous AST)
- 16. Построение дерева синтаксического разбора.
- 17. Нисходящий синтаксический анализ
3. Синтаксический анализ
Реализовать синтаксический анализ выбранного языка программирования и построение абстрактного синтаксического дерева (Abstract Syntax Tree, AST). Парсер должен распознавать все предусмотренные вашим вариантом синтаксические конструкции:
- Вызов функций.
- Арифметические и логические выражения с учетом приоритетов операций.
- Условные и циклические конструкции.
- Определение функций.
- Дополнительно: все, что необходимо для компиляции минимального примера на целевом языке программирования: директивы препроцессора, подключение модулей, определение класса и т. д.
Документация
- Language Implementation Patterns, Terence Parr
- Chapter 4: Building Intermediate Form Trees
- Chapter 5: Walking and Rewriting Trees
Порядок выполнения работы
Выполнение работы следует разбить на две части:
- Разработка минимальной грамматики. На этом этапе вам нужно написать грамматику, достаточную для парсинга приложения «Hello, World». Этап будет достаточно объемным:
- Нужно будет принять множество решений: каким спроектировать AST, как тестировать парсер.
- Разобраться с API antlr и паттерном Visitor. Вам предстоит как реализовывать интерфейсы Visitor’а, сгенерированного antlr, так и разрабатывать свои Visitor для обхода AST.
- Реализовать преобразование дерева в машино- или человеко- читаемый формат (json, xml, s-expr).
Первую часть нужно отправить напроверку отдельно. В этом случае объем кода будет еще сравнительно небольшим, и исправления ошибок будут не потребуют объемного рефакторинга.
Пример
Пусть на входе у компилятора приложение на языке С:
int main() printf("Hello World\n"); return 0; >
Тогда AST в различных форматах может выглядеть так.
(program (function (int main) (call printf "Hello World\n") (return 0)))
name="main" return-type="int"> name="printf"> "Hello, World\n" 0Ваш формат может отличаться.
Часть 1
Реализуйте Hello, World на целевом языке программирования и напишите грамматику, описывающую его структуру.
Определите множество типов узлов AST. Для приведенного выше примера на языке С это могут быть:
- Program
- FunctionDefinition
- Statement
- ReturnStatement
- FunctionCall
- StringLiteral
- IntegerLiteral
Сгенерированный парсер возвращает дерево разбора. Дерево разбора (Parse Tree) представляет полную синтаксическую структуру входной программы, включая всю пунктуацию (скобки, запятые и т. д.). Для последующей обработки программы детали конкретного синтаксиса не важны, и ваша следующая задача — абстрагироваться от синтаксиса, преобразовать дерево разбора в абстрактное синтаксическое дерево.
- Укажите генератору ANTLR создать Visitor для обхода дерева разбора. Будут сгенерированы классы: абстрактный *Visitor и *BaseVisitor с заглушками.
- Реализуйте интерфейс *Visitor и для каждого метода напишите создание соответствующего узла AST. Для наших задач оптимальным выбором будет нормализованное гетерогенное или гомогенное дерево.
- Для реализации проходов по вашему AST создайте интерфейс AstVisitor.
- Реализуйте конкретный visitor-преобразователь AST в выбранный формат.
- По умолчанию парсер выводит ошибки в stderr . Создайте свой обработчик ошибок для сохранения их в контейнер. Для этого можно унаследоваться от BaseErrorListener.
- Покройте тестами как построение AST, так и негативные сценарии с возникновением синтаксических ошибок.
Отправьте работу на проверку.
Часть 2
Реализуйте оставшиеся классы AST.
Варианты проектирования AST
От выбора структуры дерева зависит удобство реализации его обходов и способ добавления новых типов узлов.
Более подробное описание вы найдете в книге Language Implementation Patterns.
Гомогенное дерево (Homogeneous AST)
Все узлы представлены единственным классом:
public class AST Token token; ListAST> children; public AST(Token token) this.token = token; > public int getNodeType() return token.type; > public void addChild(AST t) . > >
- Крайне простая реализация.
- Список потомков одного типа существенно облегчает реализацию обхода дерева по сравнению с денормализованной структурой.
Недостаток: нет возможности хранить данные, специфичные для узлов. Например, если возникнет потребность хранить тип выражения, то его придется хранить для всех узлов, а не только для Expression.
Нормализованное гетерогенное дерево (Normalized Heterogeneous AST)
Для каждого узла создается отдельный тип, но список детей хранится единым списком:
public abstract class ExprNode extends AST int evalType; public int getEvalType() return evalType; > . >
- Возможность хранить специфичные для узла данные.
- Сохраняется простота обхода дерева за счет нормализованного списка потомков.
Недостаток: увеличивается объем кода.
Денормализованное гетерогенное дерево (Irregular Heterogeneous AST)
Для каждого узла создается отдельный тип. Каждый потомок хранится в отдельном поле.
class FunctionCall extends AST Body body; ListExprNode> argument_list; . >
Преимущество: упрощается доступ к отдельным потомкам дерева. Так, вместо обращений вида children[0] и children[1] в дереве появляются именованные поля, например, body и argument_list .
Недостаток: в каждом обходе дерева приходится реализовывать функцию для каждого типа узла.
© Copyright 2021, Evgeny Pimenov. Ревизия 15191b02 .
Источник
16. Построение дерева синтаксического разбора.
Дерево разбора может рассматриваться как графическое представление порождения, из которого удалена информация о порядке замещения не терминалов.
Каждый внутренний узел дерева представляет применение продукции.
Внутренний узел дерева помечен нетерминалом А из заголовка соответствующей продукции, а дочерние узлы слева направо символами из тела продукции, использованные в порождении для замены А.
Например, дерево для разбора – (id+id):
Листья дерева разбора не терминальными или терминальными и будучи прочитаны слева на право, образуют сентенциальную форму называемую кроной или границей дерева.
Для того что бы увидеть связь между порождениями и деревьями разбора рассмотрим произвольное приведение. α1 → α2 → … → αn
Где альфа 1 отдельный не терминал А.
Для каждой сентенциальной формы альфа 1 можно построить дерево разбора, кроной которого является альфа 1 этот процесс представляет собой индукцию по i.
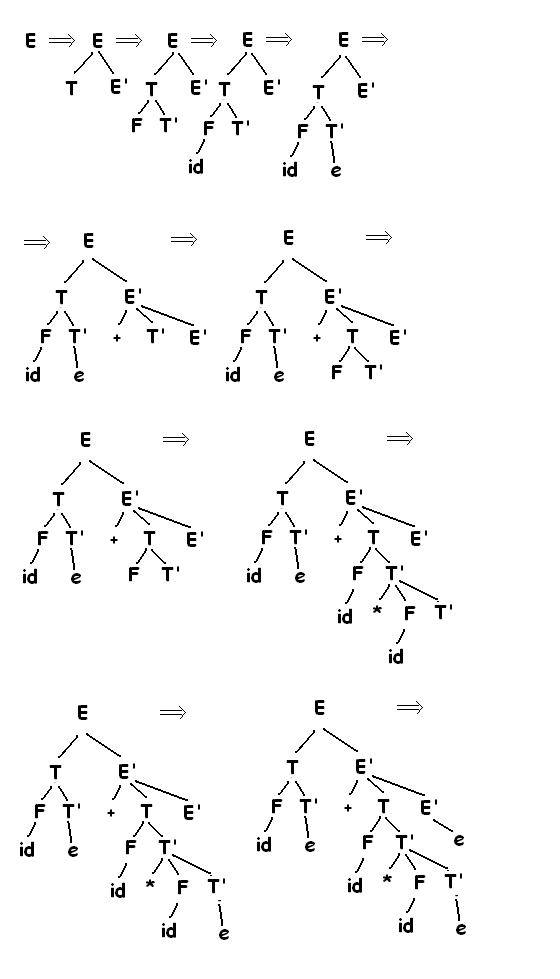
Пример, последовательность деревьев разбора:
Для моделирования этого шага корню Е в начало дерева добавляют два дочерних узла помеченных «-» и «Е».
2) – E => — (E) добавляют 3 дочерних узла, помеченных (, Е, ) к листу Е для получения дерева с кроной – (Е).
Продолжая построение описываемым способом получается полноценное дерево разбора.
Т.к. дерево разбора игнорирует порядок, в котором производилось замещение символов в сентенциальной форме, между порождениями и деревьями возникает соотношение «многих к одному».
Каждое дерево связано с единственным левым и единственным правым порождением.
17. Нисходящий синтаксический анализ
Можно рассмотреть как поиск левого порождения входящей строки. Рассмотрим последовательность построений деревьев разбора для входящей строки (id+id)*id, представляющий собой нисходящий синтаксический анализ, построенный в соответствии с грамматикой:
Эта последовательность деревьев соответствует левому порождению входящей строки. На каждом шаге нисходящего синтаксического анализа ключеваой проблемой является определение продукции, применимой для нетерминалов, например А. Когда А продукция выбрана, остальные части процесса синтаксического анализа состоят из проверки соответвствий терминальных символов в теле продукции входящей строки. В рассмотренном примере строится дерево с двумя узлами, помеченными E’, в первом (в прямом) порядке обхода узла Е’ выбирается продукция
E’ -> +TE’, во втором E’ -> e. Синтаксический анализатор может выбрать нужную E’ продукцию, рассматривающую очередной входящий символ. Класс Грамматик для которых можно построить синтаксический анализатор, просматривающий k-символов во входящем потоке называется классом LL(k).

Метод рекурсивного спуска
Программа синтаксического анализатора методом рекурсивного спуска состоит из набора процедур по одной для каждого нетерминала. Работа программы начинается с вызова процедуры для стартового символа и успешно заканчивается в случае сканирования всей входящей строки.
Типичная процедура для нетерминала низходящего анализатора
If (Xi-нетерминал) Вызов процедуры Xi();
else if(Xi равно текущему входному символу a)
Переход к следующему входному символу
Этот псевдокод недетерминирован т.к. он начинается с выбором А-продукции не указанным способом.
Рекурсивный способ в общем случае может потребовать выполнения возврата т.е. повторения сканирования входного потока. При анализе синтаксической конструкции языка программирования возврат требуется редко. В ситуациях , наподобие, синтаксического анализа естественного языка возврат не слишком эффективен и предпочтительней являются табличные методы. Чтобы разрешить возврат код в примере должен быть модифицирован:
- Невозможно выбрать единую А-продукцию в строке (1), поэтому требуется испытывать каждую из нескольких продукций в некотором порядке.
- Ошибка в строке (*) не является окончательной и предполагает возворат к строке (1) и испытание другой А-продукции.
Объявлять о найденной во входной строке ошибке можно только в том случае, если больше не имеется непроверенных А-продукций.
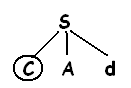
Чтобы построить дерево разбора для входной строки ω-cod начинают с дерева, состоящего из единичного узла с меткой S и указателя входного потока, указывающего на С или первый символ ω.
S имеет единичную продукцию, поэтому ее используют для разворачивания и получения дерева.
Соответствует первому символу входного потока ω, поэтому указатель входного потока перемещается к а-второму символу ω и рассматривается следующий лист, помеченный А.
Затем разворачивается А с использованием альтернативы А -> ab и получаем таким образом дерево, показанное на рис.
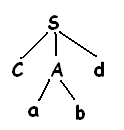
Имеется совпадение второго входного символа а, поэтому выполняется переход к третьему символу d и сравнивают его с очередным листком b. Т.к. b не соответствует d, то сообщается об ошибке и происходит возврат к А.
Чтобы выяснить нет ли альтернативной продукции, которая не была проверена до этого времени, вернувшись к а необходимо отбросить указатель входного потока так, чтобы он указывал на позицию 2, в которой указатель находится, когда впервые столкнулся с а. Это означает что процедура для а должна хранить указатель на входной поток в локальной переменной.
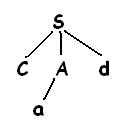
Вторая альтернатива для а дает дерево разбора:
Лист а соответствует второму символу ω, а лист d – третьему символу. Т.к. построено дерево разбора для входящей строки ω, то алгоритм завершает работу и сообщает об успешном выполнении синтаксического анализа и построении дерева разбора. Левосторонняя грамматика может привести синтаксический анализатор, работающий методом рекурсивного спуска к бесконечному циклу, т.е. когда пытаются проверить нетерминал а, то в конечном счете можно найти этот же нетерминал а и перейти к попытке развернуть а, так и не взяв ни одного символа из входного потока.
Источник