Trie, или нагруженное дерево
Здравствуй, Хабрахабр. Сегодня я хочу рассказать о такой замечательной структуре данных как словарь на нагруженном дереве, известной также как префиксное дерево, или trie.
Что это ?
Нагруженное дерево — структура данных реализующая интерфейс ассоциативного массива, то есть позволяющая хранить пары «ключ-значение». Сразу следует оговорится, что в большинстве случаев ключами выступают строки, однако в качестве ключей можно использовать любые типы данных, представимые как последовательность байт (то есть вообще любые).
Как это работает ?
Нагруженное дерево отличается от обычных n-арных деревьев тем, что в его узлах не хранятся ключи. Вместо них в узлах хранятся односимвольные метки, а ключем, который соответствует некоему узлу является путь от корня дерева до этого узла, а точнее строка составленная из меток узлов, повстречавшихся на этом пути. В таком случае корень дерева, очевидно, соответствует пустому ключу.
На рисунке вы можете наблюдать пример нагруженного дерева с ключами c, cap, car, cdr, go, if, is, it.
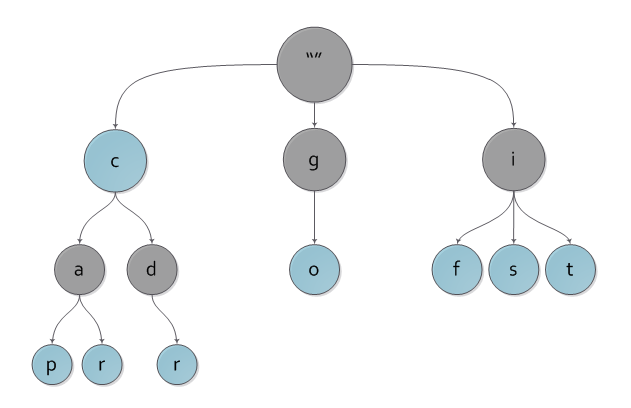
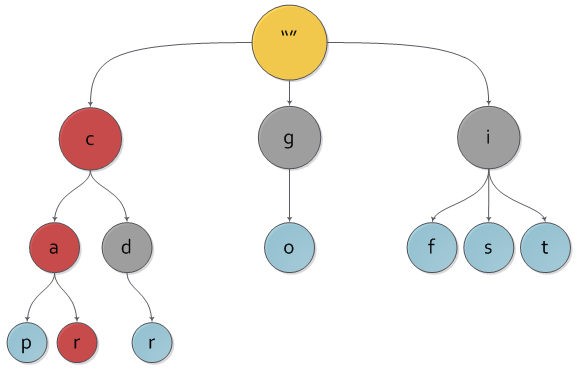
Сразу видно, что наше дерево содержит «лишние» ключи, ведь любому узлу дерева соответствует единственный путь до него от корня, а значит и некоторый ключ. Чтобы избежать проблемы с «лишними» ключами, каждому узлу дерева добавляется булева характеристика, указывающая, является ли узел реально существующим либо промежуточным по дороге в какой-либо другой.
Основные операции
Так как нагруженное дерево реализует интерфейс ассоциативного массива, в нем можно выделить три основные операции, а именно вставку, удаление и поиск ключа. Как и многие деревья, нагруженное дерево обладает свойством самоподобия, то есть любое его поддерево также является полноценным нагруженным деревом. Легко заметить, что все ключи в таком поддереве имеют общий префикс, (откуда и пошло название «префиксное дерево») а значит можно выделить специфичную для этого дерева операцию — получение всех ключей дерева с заданным префиксом за время O(|Prefix|).
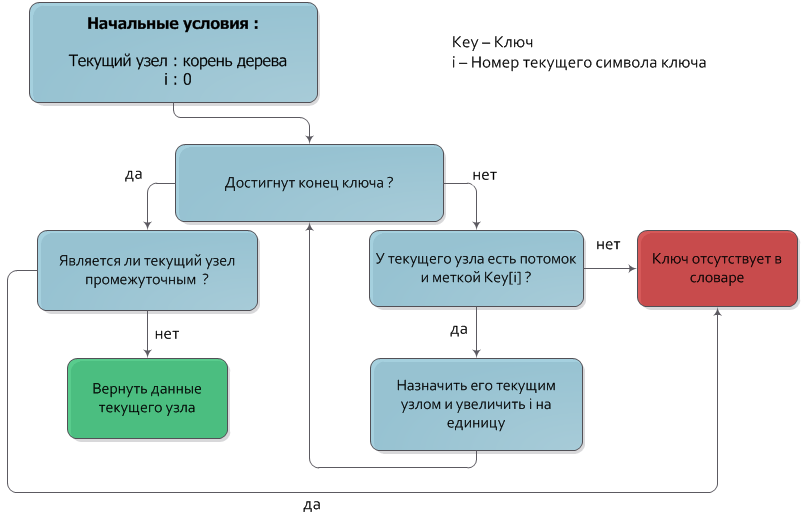
Поиск ключа
Как уже было сказано, ключ, соответствующий узлу — конкатенация меток узлов, содержащихся в пути от корня к данному узлу. Из этого свойства естественным образом следует алгоритм поиска ключа (как, впрочем, и алгоритмы добавления и удаления).
Пусть дан ключ Key, который необходимо найти в дереве. Будем спускаться из корня дерева на нижние уровни, каждый раз переходя в узел, чья метка совпадает с очередным символом ключа. После того как обработаны все символы ключа, узел, в котором остановился спуск и будет искомым узлом. Если в процессе спуска не нашлось узла с меткой, соответствующей очередному символу ключа, или спуск остановился на промежуточной вершине (вершине, не имеющей значения), то искомый ключ отсутствует в дереве.
Временная сложность этого алгоритма, очевидно, равна О(|Key|).
Более подробно алгоритм показан на блок-схеме:
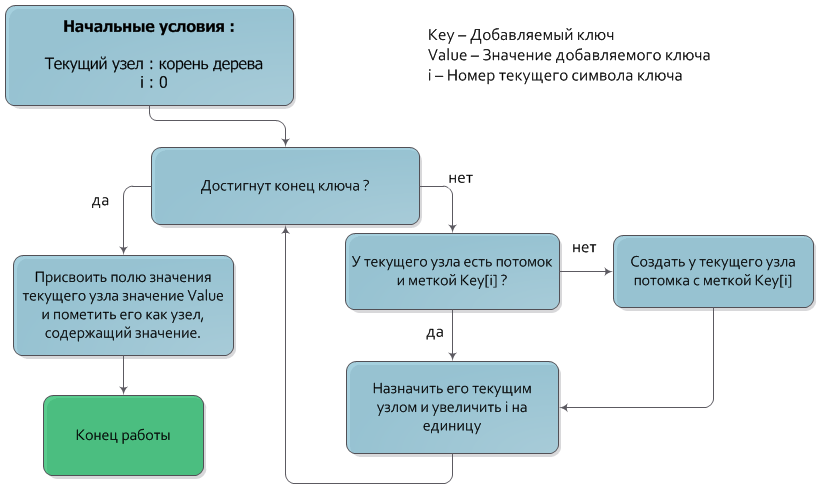
Вставка
Алгоритм добавления ключа в дерево очень похож на алгоритм поиска.
Пусть дана пара из ключа Key и значения Value, которую нужно добавить. Как и в алгоритме поиска ключа, будем спускаться из корня дерева на нижние уровни, каждый раз переходя в узел, чья метка совпадает с очередным символом ключа. После того как обработаны все символы ключа, узел, в котором остановился спуск и будет узлом, которому должно быть присвоено значение Value (также, разумеется, узел должен быть помечен как имеющий значение). Если в процессе спуска отсутствует узел с меткой, соответствующей очередному символу ключа, то следует создать новый промежуточный узел с нужной меткой и назначить его потомком текущего.
Временная сложность добавления ключа — О(|Key|).
Иллюстрация алгоритма на блок-схеме:
Удаление
Удаление ключа также реализуется очень легко.
Пусть дан ключ Key, который необходимо удалить из дерева. Проведем поиск этого ключа. Если ключ существует в словаре, то зная узел, которому он соответствует, можно просто пометить его как промежуточный, сделав его «невидимым» для последующих поисков.
После этого можно подняться от «отключенного» узла к корню, попутно удаляя все узлы которые являются листьями, однако экономия памяти в данном случае не существенна, а для эффективного определения того, является ли узел листом потребуется вводить дополнительную характеристику узла.
Временная оценка алгоритма удаления — знакомое уже О(|Key|).
Требовательность к ресурсам
Нагруженное дерево по показателям потребления памяти/процессорного времени не уступает хэш-таблицам и сбалансированным деревьям, а иногда и превосходит их по этим параметрам.
Процессорное время
Сложность операций вставки, удаления и поиска — O(|Key|). Хотя сбалансированные деревья и выполняют эти операции за O(ln(n)) но в этой асимптотике скрыто время, необходимое для сравнения ключей, которое, в общем случае, составляет O(|Key|). С хэш-таблицами ситуация аналогична — хоть время доступа и составляет О(1+a), но взятие хэша (если он не предвычислен заранее, разумеется) занимает O(|Key|).
Графики со сравнением производительности нагруженных деревьев, хэш-таблиц и красно-черных деревьев можно посмотреть в английской википедии.
Память
По потреблению памяти нагруженное дерево часто выигрывает у хэш-таблиц и сбалансированных деревьев. Это связано с тем что у множества ключей в нагруженном дереве совпадают префиксы, и вместе с ними память которую они используют. Также, в отличии от сбалансированных деревьев, в нагруженном дереве нет необходимости хранить ключ в каждом узле.
Оптимизации
- Сжатие. Сжатое нагруженное дерево получается из обычного удалением промежуточных узлов, которые ведут к единственному не промежуточному узлу. Например, цепочка промежуточных узлов с метками a, b, c заменяется на один узел с меткой abc.
- Patricia. Patricia нагруженное дерево получается из сжатого (или обычного) удалением промежуточных узлов, которые имеют одного ребенка.
Зачем все это нужно?
Собственно, область применения нагруженных деревьев огромна — их можно применять везде где требуется реализация интерфейса ассоциативного массива. Особенно нагруженные деревья удобны для реализации словарей, спеллчекеров и прочих Т9 — то есть в задачах, где необходимо быстро получать наборы ключей с заданным префиксом. Также нагруженное дерево использует в своей работе небезизвестный алгоритм Ахо — Корасик.
Вот собственно и все. Надеюсь, читателю было интересно узнать об этой замечательной структуре данных, незаслуженно редко упоминаемой на Хабре.
Источник
Префиксное дерево
Префиксное дерево или бор (англ. trie) — структура данных для компактного хранения строк, устроенная в виде дерева, где на рёбрах между вершинами записаны символы, а некоторые вершины помечены терминальными.
Говорят, что префиксное дерево принимает строку $s$, если существует такая терминальная вершина $v$, что, если выписать подряд все буквы на путях от корня до $v$, то получится строка $s$.
 изначально пустой бор можно реализовать так:</p><pre><span <span <span <span <span <span <span <span <span <span <span <span нулевой указатель означает, что перехода нет</span> </span></span><span <span <span <span <span <span <span <span <span >Чтобы добавить слово в бор, нужно пройтись от корня по символам слова. Если перехода по для очередного символа нет — создать его, иначе пройти по уже существующему. В конце текущее состояние нужно не забыть пометить терминальным.</pre><pre><span <span <span <span <span <span <span <span <span <span <span <span <span <span <span <span <span получаем число от 0 до 25</span> </span></span><span <span <span</span> </span><span <span <span <span <span <span <span <span <span <span <span <span >Чтобы проверить, есть ли слово в боре, нужно так же пройти от корня по символам слова. Если в конце оказались в терминальной вершине — то слово есть. Если оказались в нетерминальной вершине или когда-нибудь потребовалось пройтись по несуществующей ссылке — то нет.</pre><pre>Удалить слово можно «лениво»: просто дойти до него и убрать флаг терминальности.</pre><pre>В зависимости от задачи эти процедуры иногда следует изменить. Например, если мы хотим реализовать автодополнение — по запросу найти все слова с заданным префиксом — можно аккуратно удалять вершины, если они не ведут в терминальные вершины, и тогда при ответе на запрос можно просто пройтись dfs -ом из состояния-префикса, выводя ответ во всех терминальных вершинах.</pre><h3>#Как хранить ссылки</h3><p>Иногда ограничения не позволяют хранить ссылки на детей просто в массиве.</p><p>Например, если алфавит большой — тогда нам не хватит ни времени, ни памяти инициализировать столько массивов, большинство из которых будут пустыми.</p><p>Помимо массивов указателей, есть много других способов хранить отображение из символа в ссылку:</p><ul><li>расширяющийся массив ( std::vector ),</li><li>бинарное дерево ( std::map ),</li><li>хеш-таблица ( std::unordered_map ).</li></ul><p>Чаще всего память является основным практическим соображением. Также на 64-битных системах может быть выгодно вместо new и указателей выделять всё на большом массиве или векторе и хранить 4-байтные индексы вершин вместо 8-байтных указателей на память.</p><h2>#Цифровой бор</h2><p>В некоторых задачах появляется идея хранить в боре числа, подобно строкам — такая структура называется <em>цифровым бором</em>.</p><p>Чаще всего числа надо записывать в двоичной системе счисления, и тогда все очень просто, но в некоторых задачах требуется какая-то другая система счисления, а так, например, как сравнивать числа в лексикографическом порядке в десятичной системе счисления нельзя (2 > 11). Чтобы избавиться от этого момента, будем считать, что все числа меньше какой-то степени 10, и тогда будем просто дополнять число ведущими нулями: теперь 02 < 11.</p><p><strong>Задача.</strong> Задано некоторое множество чисел, и требуется отвечать на три вида запросов:</p><ol><li>Добавить число $x$.</li><li>Удалить число $x$.</li><li>Найти число $y$ в массиве, у которого xor c $x$ максимален.</li></ol><p>Первые два вида запросов мы уже умеем делать в цифровом боре, а запрос третьего типа сложнее.</p><p>Заметим, что если существует $y$ из множества, такой что $y_i \neq x_i$ (то есть они отличаются в $i$-ом бите), то взять его выгоднее, чем любое другое число, у которого префикс до $i$-того бита включительно равен префиксу $x$ — потому что xor такого числа с $x$ будет содержать только меньшие биты, чем $i$-тый, и соответственно не будет превосходить $2^i$, который мы уже можем получить с $y$.</p><p>Тогда при ответе на запрос третьего типа мы можем жадно спускаться по бору, каждый раз пытаясь пойти в ветку, у которой $i$-тый бит не равен $x_i$.</p><p><span class=) Источник
Источник