- Методы программирования
- Теория
- Обход дерева в глубину
- Обход дерева в ширину
- Двоичные деревья поиска
- Сбалансированные деревья
- Формулировка задания
- а. Реализация простых двоичных деревьев поиска
- Примеры
- b. ** Реализация сбалансированных деревьев
- c. Реализация префиксного, инфиксного и постфиксного обходов двоичного дерева
- Дерево
- Способы обхода дерева
- Реализация дерева
- Добавление узлов в дерево
- Удаление поддерева
- Комментариев к записи: 19
Методы программирования
Задание состоит из трех частей, первая и третья обязательны для выполнения, вторая выполняется по желанию студента. Срок сдачи задания — 17 октября.
Теория
Двоичное дерево задается следующей структурой:
typedef struct _t int data; /* данные в узле */
struct _t *left, *right; /* указатели на левого и правого сыновей */
> t;
t *root; /* корень дерева */
Таким образом, каждый элемент дерева содержит некоторые данные и два указателя на потомков (на левого сына и на правого). Сам узел будем называть отцом этих двух потомков. Определение дерева требует, чтобы у каждого узла, кроме корня, был ровно один отец. Указатель на корень дерева хранится в переменной root , она равна нулю, если дерево пусто.
Левым и правым поддеревьями узла t ( t != 0 ) будем называть деревья (возможно, пустые), корнями которых являются соответственно t->left и t->right .
Основные операции на деревьях: поиск элемента, добавление элемента, удаление элемента. Для поиска элемента в произвольном бинарном дереве необходимо обойти все элементы этого дерева. Существует два основных способа обхода дерева: в глубину и в ширину.
Обход дерева в глубину
Обход в глубину производится рекурсивно либо с использованием стека. В обоих случаях можно обходить узлы дерева в различной последовательности. Обход начинается от корня. Выделяют три наиболее важных порядка обхода в глубину:
- префиксный (прямой) обход — сначала обрабатывается текущий узел, затем левое и правое поддеревья;
- инфиксный (симметричный) обход — сначала обрабатывается левое поддерево текущего узла, затем корень, затем правое поддерево;
- постфиксный (обратный) обход — сначала обрабатываются левое и правое поддеревья текущего узла, затем сам узел.
В качестве примера рассмотрим следующее дерево:
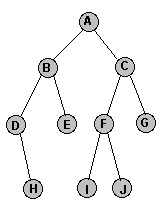
- префиксный обход: A, B, D, H, E, C, F, I, J, G
- инфиксный обход: D, H, B, E, A, I, F, J, C, G
- постфиксный обход: H, D, E, B, I, J, F, G, C, A
Запишем в качестве примера рекурсивную процедуру, выводящую на экран узлы дерева в порядке префиксного обхода.
void prefix(t *curr)
if (!curr)
return;
printf(«%d «, curr->data);
prefix(curr->left);
prefix(curr->right);
>
Обход дерева в ширину
Обход в ширину производится с помощью очереди. Первоначально в очередь помещается корень, затем, пока очередь не пуста, выполняются следующие действия:
- Из очереди выталкивается очередной узел;
- Этот узел обрабатывается;
- В очередь добавляются оба сына этого узла.
Узлы дерева на рисунке перечисляются в порядке обхода в ширину следующим образом: A, B, C, D, E, F, G, H, I, J. Заметим, что перечисление узлов происходит в порядке удаления от корня, что делает поиск в ширину удобным, например, для поиска узла дерева со значением k , наиболее близкого к корню, и т.д.
Приведем пример процедуры, которая выводит на экран узлы дерева в порядке обхода в ширину. Считаем, что определены три функции:
void add(t *elem); /* добавляет в конец очереди элемент elem */
t *del(); /* удаляет из очереди первый элемент и возвращает указатель на него */
int empty(); /* возвращает 1, если очередь пуста, и 0 в противном случае */
Тогда процедура обхода будет иметь следующий вид:
void width(t *root)
if (!root)
return;
add(root);
while (!empty()) t *curr = del();
printf(«%d «, curr->data);
if (curr->left)
add(curr->left);
if (curr->right)
add(curr->right);
>
>
Двоичные деревья поиска
Для поиска узла в таком дереве можно использовать как рекурсивную функцию, так и простой цикл. Ниже приведен пример функции, которая ищет узел со значением k в двоичном дереве поиска с корнем root . Этот код весьма напоминает обычный бинарный поиск:
t *search(t *root, int k)
t *curr = root;
while (curr) if (k == curr->data)
return (curr);
if (k < curr->data)
curr = curr->left;
else
curr = curr->right;
>
return (0);
>
Добавление узла в двоичное дерево поиска напоминает добавление элемента в середину связанного списка: выполняется проход по дереву с запоминанием указателя на узел, предшествующий текущему, и добавление узла к предыдущему, как только текущий указатель станет равным нулю. Необходимо отдельно обработать случай пустого дерева.
Удаление узла из двоичного дерева поиска является менее тривиальной операцией: необходимо поддерживать выполнение условия расположения элементов («слева меньше, справа больше»). Одним из возможных способов является следующий:
- если у удаляемого узла нет сыновей, его удаление не представляет проблемы (освобождаем память и зануляем указатель на нее у его отца);
- если у удаляемого узла есть ровно один сын, удаляем узел, а указатель на него у отца заменяем указателем на этого сына;
- если у удаляемого узла есть оба сына, ищем в правом поддереве узел с минимальным значением (у него по определению будет отсутствовать левый сын) и ставим этот узел на место удаляемого, аккуратно поменяв все необходимые указатели.
Сбалансированные деревья
При работе с двоичными деревьями поиска возможен случай, когда дерево по сути примет вид линейного связанного списка (например, если элементы подавались на вход в порядке возрастания). В таком случае поиск элемента в дереве будет занимать линейное время. Одним из способов предотвращения подобной ситуации является балансировка дерева по мере добавления элементов.
Сбалансированным деревом (AVL-деревом) называется двоичное дерево поиска, удовлетворяющее следующему условию: для любого узла глубина левого поддерева отличается от глубины правого поддерева не более чем на 1. В сбалансированном дереве поиск элемента выполняется за время O(log2N), где N — количество узлов (Адельсон-Вельский, Ландис, 1962). Алгоритм построения сбалансированных деревьев можно найти в сети и в литературе (Вирт, Кнут, . ), поэтому подробное описание его здесь не приводится.
Формулировка задания
а. Реализация простых двоичных деревьев поиска
Во входном файле input.txt в первой строке находится количество записей N , в следующих N строках находятся записи вида имя значение , причем имена могут повторяться. В файл output.txt выдать итоговые значения всех переменных в алфавитном порядке. Хранение записей организовать в виде двоичного дерева поиска.
Примеры
b. ** Реализация сбалансированных деревьев
Задание аналогично предыдущему, но требуется поддерживать дерево сбалансированным. Задание не является обязательным.
c. Реализация префиксного, инфиксного и постфиксного обходов двоичного дерева
Необходимо реализовать функции обхода дерева в порядке префиксного, инфиксного и постфиксного обходов. Дерево задается произвольным образом.
Источник
Дерево
Дерево – структура данных, представляющая собой древовидную структуру в виде набора связанных узлов.
Бинарное дерево — это конечное множество элементов, которое либо пусто, либо содержит элемент ( корень ), связанный с двумя различными бинарными деревьями, называемыми левым и правым поддеревьями . Каждый элемент бинарного дерева называется узлом . Связи между узлами дерева называются его ветвями .

Способ представления бинарного дерева:
Корень дерева расположен на уровне с минимальным значением.
Узел D , который находится непосредственно под узлом B , называется потомком B . Если D находится на уровне i , то B – на уровне i-1 . Узел B называется предком D .
Максимальный уровень какого-либо элемента дерева называется его глубиной или высотой .
Если элемент не имеет потомков, он называется листом или терминальным узлом дерева.
Остальные элементы – внутренние узлы (узлы ветвления).
Число потомков внутреннего узла называется его степенью . Максимальная степень всех узлов есть степень дерева.
Число ветвей, которое нужно пройти от корня к узлу x , называется длиной пути к x . Корень имеет длину пути равную 0 ; узел на уровне i имеет длину пути равную i .
Бинарное дерево применяется в тех случаях, когда в каждой точке вычислительного процесса должно быть принято одно из двух возможных решений.
Имеется много задач, которые можно выполнять на дереве.
Распространенная задача — выполнение заданной операции p с каждым элементом дерева. Здесь p рассматривается как параметр более общей задачи посещения всех узлов или задачи обхода дерева.
Если рассматривать задачу как единый последовательный процесс, то отдельные узлы посещаются в определенном порядке и могут считаться расположенными линейно.
Способы обхода дерева
Пусть имеем дерево, где A — корень, B и C — левое и правое поддеревья.

Существует три способа обхода дерева:
- Обход дерева сверху вниз (в прямом порядке): A, B, C — префиксная форма.
- Обход дерева в симметричном порядке (слева направо): B, A, C — инфиксная форма.
- Обход дерева в обратном порядке (снизу вверх): B, C, A — постфиксная форма.
Реализация дерева
Узел дерева можно описать как структуру:
struct tnode <
int field; // поле данных
struct tnode *left; // левый потомок
struct tnode *right; // правый потомок
>;
При этом обход дерева в префиксной форме будет иметь вид
void treeprint(tnode *tree) <
if (tree!= NULL ) < //Пока не встретится пустой узел
cout field; //Отображаем корень дерева
treeprint(tree->left); //Рекурсивная функция для левого поддерева
treeprint(tree->right); //Рекурсивная функция для правого поддерева
>
>
Обход дерева в инфиксной форме будет иметь вид
void treeprint(tnode *tree) <
if (tree!= NULL ) < //Пока не встретится пустой узел
treeprint(tree->left); //Рекурсивная функция для левого поддерева
cout field; //Отображаем корень дерева
treeprint(tree->right); //Рекурсивная функция для правого поддерева
>
>
Обход дерева в постфиксной форме будет иметь вид
void treeprint(tnode *tree) <
if (tree!= NULL ) < //Пока не встретится пустой узел
treeprint(tree->left); //Рекурсивная функция для левого поддерева
treeprint(tree->right); //Рекурсивная функция для правого поддерева
cout field; //Отображаем корень дерева
>
>
Бинарное (двоичное) дерево поиска – это бинарное дерево, для которого выполняются следующие дополнительные условия (свойства дерева поиска):
- оба поддерева – левое и правое, являются двоичными деревьями поиска;
- у всех узлов левого поддерева произвольного узла X значения ключей данных меньше, чем значение ключа данных самого узла X ;
- у всех узлов правого поддерева произвольного узла X значения ключей данных не меньше, чем значение ключа данных узла X .
Данные в каждом узле должны обладать ключами, на которых определена операция сравнения меньше.
Как правило, информация, представляющая каждый узел, является записью, а не единственным полем данных.
Для составления бинарного дерева поиска рассмотрим функцию добавления узла в дерево.
Добавление узлов в дерево
struct tnode * addnode( int x, tnode *tree) <
if (tree == NULL ) < // Если дерева нет, то формируем корень
tree = new tnode; // память под узел
tree->field = x; // поле данных
tree->left = NULL ;
tree->right = NULL ; // ветви инициализируем пустотой
> else if (x < tree->field) // условие добавление левого потомка
tree->left = addnode(x,tree->left);
else // условие добавление правого потомка
tree->right = addnode(x,tree->right);
return (tree);
>
Удаление поддерева
void freemem(tnode *tree) <
if (tree!= NULL ) <
freemem(tree->left);
freemem(tree->right);
delete tree;
>
>
Пример Написать программу, подсчитывающую частоту встречаемости слов входного потока.
Поскольку список слов заранее не известен, мы не можем предварительно упорядочить его. Неразумно пользоваться линейным поиском каждого полученного слова, чтобы определять, встречалось оно ранее или нет, т.к. в этом случае программа работает слишком медленно.
Один из способов — постоянно поддерживать упорядоченность уже полученных слов, помещая каждое новое слово в такое место, чтобы не нарушалась имеющаяся упорядоченность. Воспользуемся бинарным деревом.
В дереве каждый узел содержит:
- указатель на текст слова;
- счетчик числа встречаемости;
- указатель на левого потомка;
- указатель на правого потомка.
Рассмотрим выполнение программы на примере фразы
now is the time for all good men to come to the aid of their party

При этом дерево будет иметь следующий вид
#include
#include
#include
#include
//#include
#define MAX WORD 100
struct tnode < // узел дерева
char * word; // указатель на строку (слово)
int count; // число вхождений
struct tnode* left; // левый потомок
struct tnode* right; // правый потомок
>;
// Функция добавления узла к дереву
struct tnode* addtree( struct tnode* p, char * w) int cond;
if (p == NULL ) p = ( struct tnode*)malloc( sizeof ( struct tnode));
p->word = _strdup(w);
p->count = 1;
p->left = p->right = NULL ;
>
else if ((cond = strcmp(w, p->word)) == 0)
p->count++;
else if (cond < 0)
p->left = addtree(p->left, w);
else
p->right = addtree(p->right, w);
return p;
>
// Функция удаления поддерева
void freemem(tnode* tree) if (tree != NULL ) freemem(tree->left);
freemem(tree->right);
free(tree->word);
free(tree);
>
>
// Функция вывода дерева
void treeprint( struct tnode* p) if (p != NULL ) treeprint(p->left);
printf( «%d %s\n» , p->count, p->word);
treeprint(p->right);
>
>
int main() struct tnode* root;
char word[MAX WORD ];
root = NULL ;
do scanf_s( «%s» , word, MAX WORD );
if (isalpha(word[0]))
root = addtree(root, word);
> while (word[0] != ‘0’ ); // условие выхода – ввод символа ‘0’
treeprint(root);
freemem(root);
getchar();
getchar();
return 0;
>

Результат выполнения
Комментариев к записи: 19
Источник