- Алгоритм классификации Random Forest на Python
- Алгоритм Random Forest
- Как работает случайный лес?
- Поиск важных признаков
- Сравнение случайных лесов и деревьев решений
- Создание классификатора с использованием Scikit-learn
- Random forest дерево решений
- Порядок действий в алгоритме
- Теоретическая составляющая алгоритма случайного дерева
- Реализация алгоритма Random Forest
- Недостатки алгоритма
- Заключение
Алгоритм классификации Random Forest на Python
Случайный лес (Random forest, RF) — это алгоритм обучения с учителем. Его можно применять как для классификации, так и для регрессии. Также это наиболее гибкий и простой в использовании алгоритм. Лес состоит из деревьев. Говорят, что чем больше деревьев в лесу, тем он крепче. RF создает деревья решений для случайно выбранных семплов данных, получает прогноз от каждого дерева и выбирает наилучшее решение посредством голосования. Он также предоставляет довольно эффективный критерий важности показателей (признаков).
Случайный лес имеет множество применений, таких как механизмы рекомендаций, классификация изображений и отбор признаков. Его можно использовать для классификации добросовестных соискателей кредита, выявления мошенничества и прогнозирования заболеваний. Он лежит в основе алгоритма Борута, который определяет наиболее значимые показатели датасета.
Алгоритм Random Forest
Давайте разберемся в алгоритме случайного леса, используя нетехническую аналогию. Предположим, вы решили отправиться в путешествие и хотите попасть в туда, где вам точно понравится.
Итак, что вы делаете, чтобы выбрать подходящее место? Ищите информацию в Интернете: вы можете прочитать множество различных отзывов и мнений в блогах о путешествиях, на сайтах, подобных Кью, туристических порталах, — или же просто спросить своих друзей.
Предположим, вы решили узнать у своих знакомых об их опыте путешествий. Вы, вероятно, получите рекомендации от каждого друга и составите из них список возможных локаций. Затем вы попросите своих знакомых проголосовать, то есть выбрать лучший вариант для поездки из составленного вами перечня. Место, набравшее наибольшее количество голосов, станет вашим окончательным выбором для путешествия.
Вышеупомянутый процесс принятия решения состоит из двух частей.
- Первая заключается в опросе друзей об их индивидуальном опыте и получении рекомендации на основе тех мест, которые посетил конкретный друг. В этой части используется алгоритм дерева решений. Каждый участник выбирает только один вариант среди знакомых ему локаций.
- Второй частью является процедура голосования для определения лучшего места, проведенная после сбора всех рекомендаций. Голосование означает выбор наиболее оптимального места из предоставленных на основе опыта ваших друзей. Весь этот процесс (первая и вторая части) от сбора рекомендаций до голосования за наиболее подходящий вариант представляет собой алгоритм случайного леса.
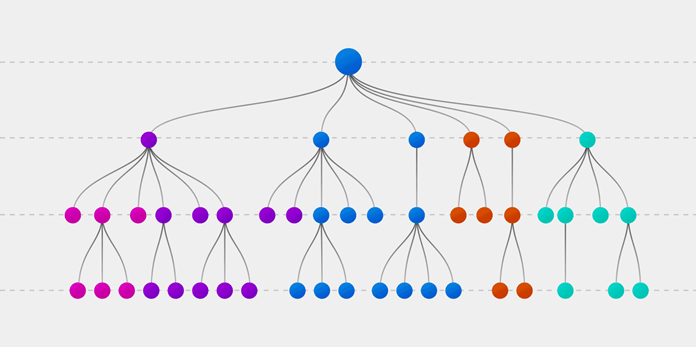
Технически Random forest — это метод (основанный на подходе «разделяй и властвуй»), использующий ансамбль деревьев решений, созданных на случайно разделенном датасете. Набор таких деревьев-классификаторов образует лес. Каждое отдельное дерево решений генерируется с использованием метрик отбора показателей, таких как критерий прироста информации, отношение прироста и индекс Джини для каждого признака.
Любое такое дерево создается на основе независимой случайной выборки. В задаче классификации каждое дерево голосует, и в качестве окончательного результата выбирается самый популярный класс. В случае регрессии конечным результатом считается среднее значение всех выходных данных ансамбля. Метод случайного леса является более простым и эффективным по сравнению с другими алгоритмами нелинейной классификации.
Как работает случайный лес?
Алгоритм состоит из четырех этапов:
- Создайте случайные выборки из заданного набора данных.
- Для каждой выборки постройте дерево решений и получите результат предсказания, используя данное дерево.
- Проведите голосование за каждый полученный прогноз.
- Выберите предсказание с наибольшим количеством голосов в качестве окончательного результата.
Поиск важных признаков
Random forest также предлагает хороший критерий отбора признаков. Scikit-learn предоставляет дополнительную переменную при использовании модели случайного леса, которая показывает относительную важность, то есть вклад каждого показателя в прогноз. Библиотека автоматически вычисляет оценку релевантности каждого признака на этапе обучения. Затем полученное значение нормализируется так, чтобы сумма всех оценок равнялась 1.
Такая оценка поможет выбрать наиболее значимые показатели и отбросить наименее важные для построения модели.
Случайный лес использует критерий Джини, также известный как среднее уменьшение неопределенности (MDI), для расчета важности каждого признака. Кроме того, критерий Джини иногда называют общим уменьшением неопределенности в узлах. Он показывает, насколько снижается точность модели, когда вы отбрасываете переменную. Чем больше уменьшение, тем значительнее отброшенный признак. Таким образом, среднее уменьшение является необходимым параметром для выбора переменной. Также с помощью данного критерия можете быть отображена общая описательная способность признаков.
Сравнение случайных лесов и деревьев решений
- Случайный лес — это набор из множества деревьев решений.
- Глубокие деревья решений могут страдать от переобучения, но случайный лес предотвращает переобучение, создавая деревья на случайных выборках.
- Деревья решений вычислительно быстрее, чем случайные леса.
- Случайный лес сложно интерпретировать, а дерево решений легко интерпретировать и преобразовать в правила.
Создание классификатора с использованием Scikit-learn
Вы будете строить модель на основе набора данных о цветках ириса, который является очень известным классификационным датасетом. Он включает длину и ширину чашелистика, длину и ширину лепестка, и тип цветка. Существуют три вида (класса) ирисов: Setosa, Versicolor и Virginica. Вы построите модель, определяющую тип цветка из вышеперечисленных. Этот датасет доступен в библиотеке scikit-learn или вы можете загрузить его из репозитория машинного обучения UCI.
Начнем с импорта datasets из scikit-learn и загрузим набор данных iris с помощью load_iris() .
Источник
Random forest дерево решений

Здесь мы на основе классификации просто добавляем метод для отбора признаков.
Порядок действий в алгоритме
- Загрузите ваши данные.
- В заданном наборе данных определите случайную выборку.
- Далее алгоритм построит по выборке дерево решений.
- Дерево строится, пока в каждом листе не более n объектов, или пока не будет достигнута определенная высота.
- Затем будет получен результат прогнозирования из каждого дерева решений.
- На этом этапе голосование будет проводиться для каждого прогнозируемого результата: мы выбираем лучший признак, делаем разбиение в дереве по нему и повторяем этот пункт до исчерпания выборки.
- В конце выбирается результат прогноза с наибольшим количеством голосов. Это и есть окончательный результат прогнозирования.
Теоретическая составляющая алгоритма случайного дерева
По сравнению с другими методами машинного обучения, теоретическая часть алгоритма Random Forest проста. У нас нет большого объема теории, необходима только формула итогового классификатора a(x) :
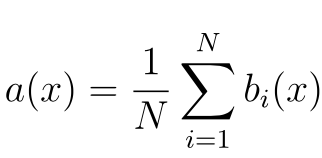
- N – количество деревьев;
- i – счетчик для деревьев;
- b – решающее дерево;
- x – сгенерированная нами на основе данных выборка.
Стоит также отметить, что для задачи классификации мы выбираем решение голосованием по большинству, а в задаче регрессии – средним.
Реализация алгоритма Random Forest
Реализуем алгоритм на простом примере для задачи классификации, используя библиотеку scikit-learn:

- Имеет высокую точность предсказания, которая сравнима с результатами градиентного бустинга.
- Не требует тщательной настройки параметров, хорошо работает из коробки.
- Практически не чувствителен к выбросам в данных из-за случайного семплирования (random sample).
- Не чувствителен к масштабированию и к другим монотонным преобразованиям значений признаков.
- Редко переобучается. На практике добавление деревьев только улучшает композицию.
- В случае наличия проблемы переобучения, она преодолевается путем усреднения или объединения результатов различных деревьев решений.
- Способен эффективно обрабатывать данные с большим числом признаков и классов.
- Хорошо работает с пропущенными данными – сохраняет хорошую точность даже при их наличии.
- Одинаково хорошо обрабатывает как непрерывные, так и дискретные признаки
- Высокая параллелизуемость и масштабируемость.
Недостатки алгоритма

- Для реализации алгоритма случайного дерева требуется значительный объем вычислительных ресурсов.
- Большой размер моделей.
- Построение случайного леса отнимает больше времени, чем деревья решений или линейные алгоритмы.
- Алгоритм склонен к переобучению на зашумленных данных.
- Нет формальных выводов, таких как p-values, которые используются для оценки важности переменных.
- В отличие от более простых алгоритмов, результаты случайного леса сложнее интерпретировать.
- Когда в выборке очень много разреженных признаков, таких как тексты или наборы слов (bag of words), алгоритм работает хуже чем линейные методы.
- В отличие от линейной регрессии, Random Forest не обладает возможностью экстраполяции. Это можно считать и плюсом, так как в случае выбросов не будет экстремальных значений.
- Если данные содержат группы признаков с корреляцией, которые имеют схожую значимость для меток, то предпочтение отдается небольшим группам перед большими, что ведет к недообучению.
- Процесс прогнозирования с использованием случайных лесов очень трудоемкий по сравнению с другими алгоритмами.
Заключение
Метод случайного дерева (Random Forest) – это универсальный алгоритм машинного обучения с учителем. Его можно использовать во множестве задач, но в основном он применяется в проблемах классификации и регрессии.
Действенный и простой в понимании, алгоритм имеет значительный недостаток – заметное замедление работы при определенной настройке параметров внутри него.
Вы можете использовать случайный лес, если вам нужны чрезвычайно точные результаты или у вас есть огромный объем данных для обработки, и вам нужен достаточно сильный алгоритм, который позволит вам эффективно обработать все данные.
Дополнительные материалы:
Источник