13 Вопрос. Реализация деревьев с помощью массива.
В статической памяти дерево можно представить массивом, для которого определено понятие пустого элемента:

Рис.2. двоичное дерево представленное в виде массива
Вершины двоичного дерева располагаются в массиве следующим образом (см. рис.2.): если k – индекс вершины дерева, то ее потомки находятся в элементах массива с индексами 2k + 1 и 2(k + 1); корень дерева находится в элементе с индексом 0 (при индексации в массиве от 1 до N индексы потомков k-ой вершины: 2k и 2k + 1, корень имеет индекс 1).
В динамической памяти дерево представляется иерархическим списком. Задать элемент двоичного дерева можно как элемент списка с тремя полями: два ссылочных поля, содержащие указатели на его левое ( L ) и правое ( R ) поддеревья, и информационное поле ( E ):

Определение типа элемента бинарного динамического дерева:
Здесь type – тип информационного поля (если информационное поле имеет сложную структуру, то type может быть типом — указатель на объект, содержащий значение элемента дерева).
Чтобы определить дерево как единую структуру, надо задать указатель на корень дерева:

Рис.3. Двоичное динамическое дерево
На рис.3 представлено двоичное динамическое дерево d в соответствии с определением типа элемента, сделанным выше. Элементы дерева со степенью 0 и 1 имеют два или одно ссылочное поле со значением равным пустому указателю (NULL).
14 Вопрос. Алгоритмы обходов бинарного дерева.
Обход дерева – это способ методичного исследования его узлов, при котором каждый узел проходится точно один раз. Полное прохождение динамического дерева дает линейную расстановку его узлов.
Возможны два способа прохождения бинарного дерева (если дерево не пусто):
- в глубину;
- в ширину.
Алгоритмы обхода в глубину Существует несколько способов обхода в глубину:
- Прямой порядок (см. рис.4.а):
- попасть в корень;
- пройти в прямом порядке левое поддерево;
- пройти в прямом порядке правое поддерево.
- Обратный порядок(см. рис.4.б):
- пройти в обратном порядке левое поддерево;
- пройти в обратном порядке правое поддерево;
- попасть в корень.
- Симметричный порядок(см. рис.4.в):
- пройти в симметричном порядке левое поддерево;
- попасть в корень;
- пройти в симметричном порядке правое поддерево.
 Рис.4. Способы обхода дерева в глубину Алгоритмы обхода в ширину Узлы дерева посещаются слева направо, уровень за уровнем вниз от корня (линейная расстановка узлов дерева, представленна на рис.5).
Рис.4. Способы обхода дерева в глубину Алгоритмы обхода в ширину Узлы дерева посещаются слева направо, уровень за уровнем вниз от корня (линейная расстановка узлов дерева, представленна на рис.5).  Рис.5. Порядок обхода дерева в ширину
Рис.5. Порядок обхода дерева в ширину
15 Вопрос. Добавление элемента в двоичное дерево.
Включение элемента в дерево. Операция заключается в добавлении листа (исключая сбалансированное дерево – включение элемента в сбалансированное дерево приводит, как правило, к его перестройке) в какое-то поддерево, если такого элемента нет в исходном дереве. При включении нового элемента в дерево поиска лист добавляется в то поддерево, в котором не нарушается отношение порядка; В двоичном дереве каждая вершина имеет не более двух потомков, обозначенных как левый ( left) и правый ( right). Кроме того, на данные, хранимые в вершинах дерева, вводится следующее правило упорядочения: значения вершин левого поддерева всегда меньше, а значения вершин правого поддерева — больше значения в текущей вершине. struct btree < int val; btree *left,*right; >; Свойства двоичного дерева позволяют применить в нем алгоритм поиска, аналогичный двоичному поиску в массиве. Каждое сравнение искомого значения и значения в вершине позволяет выбрать для следующего шага правое или левое поддерево. Алгоритмы включения и исключения вершин дерева не должны нарушать указанное свойство: при включении вершины дерева поиск места ее размещения производится путем аналогичных сравнений. Эти алгоритмы являются линейно рекурсивными или циклическими.
Источник
Построить бинарное дерево из родительского массива
Дан целочисленный массив, представляющий двоичное дерево, такое, что отношение родитель-потомок определяется как (A[i], i) для каждого индекса i в массиве A , построить из него бинарное дерево. Значение корневого узла равно i если -1 присутствует в индексе i в массиве. Можно предположить, что входные данные, предоставленные программе, действительны.
- -1 присутствует в индексе 0, что означает, что корень бинарного дерева является узлом 0.
- 0 присутствует в индексах 1 и 2, что означает, что левый и правый потомки узла 0 — это 1 и 2.
- 1 присутствует в индексе 3, что означает, что левый или правый дочерний элемент узла 1 равен 3.
- 2 присутствует в индексах 4 и 5, что означает, что левый и правый потомки узла 2 — это 4 и 5.
- 4 присутствует в индексах 6 и 7, что означает, что левый и правый потомки узла 4 — это 6 и 7.
Соответствующее бинарное дерево:
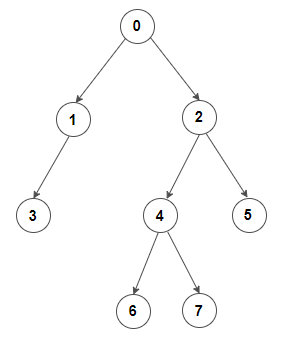
Решение простое и эффективное – создайте n новые узлы дерева, каждый из которых имеет значения от 0 до n-1 , куда n — это размер массива, и сохранить их на карте или в массиве для быстрого поиска. Затем пройдите по данному родительскому массиву и постройте дерево, установив отношение родитель-потомок, определенное (A[i], i) для каждого индекса i в массиве A . Поскольку из одного входа можно сформировать несколько бинарных деревьев, решение должно построить любое из них. Решение всегда будет устанавливать левый дочерний узел для узла перед установкой его правого дочернего элемента.
Алгоритм может быть реализован следующим образом на C++, Java и Python:
Источник
Представление деревьев с помощью массивов
При этом представлении каждый элемент массива A[i] является указателем или курсором на родителя узла i. Корень дерева имеет нулевой указатель.

Д анное представление основывается на том, что каждый узел, отличный от корня, имеет только одного родителя.
Используя это представление, родителя любого узла можно найти за фиксированное время. Прохождение по пути, т.е. переход по узлам от родителя к родителю, можно выполнить за время, пропорциональное количеству узлов пути.
Для реализации оператора LEBEL можно использовать другой массив, в котором хранить метку узла i.
днако, используя такое представление, трудно для заданного узла найти его сыновей или определить его высоту. Кроме того, в этом случае невозможно определить порядок сыновей узла если не поддерживать специальный порядок в массиве, например, левые сыновья должны иметь меньший индекс в массиве, чем правые.
Представление деревьев с использованием списков сыновей
В этом представлении для каждого узла дерева формируется список сыновей. Эти списки можно представить любым способом. Вот как будет выглядеть наше дерево при таком представлении

П редставление левых сыновей и правых братьев (левый ребенок – правый сосед)
- указатель на родителя,
- указатель на самого левого сына узла,
- указатель на ближайшего справа (следующего по старшинству) брата узла.
 Узел x тогда и только тогда не имеет сыновей, когда указатель left_child(x) = NULL. Если узел x – самый правый сын родителя, то right_sibling(x) = NULL. Двоичные (бинарные) деревья В компьютерных науках часто используются деревья, в которых все вершины имеют ограниченное сверху количество потомков. Например, если это число 2, то любая вершина содержит не более двух (2,1 или 0) потомков, такие деревья называются бинарнымиилидвоичными. Реализация с помощью указателей на «левого ребенка» и «правого ребенка». Коды Хаффмана Примером применения двоичных деревьев в качестве структур данных могут служить коды Хаффмана. Они широко используются при сжатии информации (выигрыш может составить от 20% до 90% в зависимости от типа файла). Алгоритм Хаффмана находит оптимальные коды символов исходя из частоты использования этих символов в сжимаемом тексте с помощью жадного выбора. Предположим, в файле длиной 100 000 встречаются только латинские буквы от а до f и известны их частоты.
Узел x тогда и только тогда не имеет сыновей, когда указатель left_child(x) = NULL. Если узел x – самый правый сын родителя, то right_sibling(x) = NULL. Двоичные (бинарные) деревья В компьютерных науках часто используются деревья, в которых все вершины имеют ограниченное сверху количество потомков. Например, если это число 2, то любая вершина содержит не более двух (2,1 или 0) потомков, такие деревья называются бинарнымиилидвоичными. Реализация с помощью указателей на «левого ребенка» и «правого ребенка». Коды Хаффмана Примером применения двоичных деревьев в качестве структур данных могут служить коды Хаффмана. Они широко используются при сжатии информации (выигрыш может составить от 20% до 90% в зависимости от типа файла). Алгоритм Хаффмана находит оптимальные коды символов исходя из частоты использования этих символов в сжимаемом тексте с помощью жадного выбора. Предположим, в файле длиной 100 000 встречаются только латинские буквы от а до f и известны их частоты.
| A | B | C | D | E | F | |
| Количество в тысячах | 45 | 13 | 12 | 16 | 9 | 5 |
| Равномерный код | 000 | 001 | 010 | 011 | 100 | 101 |
| Неравномерный код | 0 | 101 | 100 | 111 | 1101 | 1100 |
Мы хотим построить двоичный код, в котором каждый символ представляется в виде конечной последовательности битов, называемой кодовым словом. При использовании равномерного кода, в котором все кодовые слова имеют одинаковую длину, на каждый символ надо потратить как минимум 3 бита. На весь файл уйдет 300 000 бит. Но если часто встречающиеся символы закодировать короткими последова-тельностями битов, а редко встречающиеся – длинными, то можно построить более экономный неравномерный код. В приведенном примере неравномерного кода на весь файл уйдет 224 000 бит, что дает около 25% экономии. Будем раcсматривать только коды, в которых из двух последовательностей битов, представляющих различные символы, ни одна не является префиксом другой. Такие коды называются префиксными кодами хотя логичнее было бы называть их «безпрефиксными». Можно показать, что для любого кода, обеспечивающего однозначное восстановление информации, существует не худший его префиксный код. Поэтому, ограничившись префиксными кодами, мы ничего не теряем. При кодировании каждый символ заменяется на свой код. Например, строка ABC запишется как 0101100. Для префиксного кода декодирование однозначно и выполняется слева направо. Для эффективной реализации декодирования надо хранить информацию о коде в удобной форме. Одна из возможностей – представить код в виде двоичного дерева, листья которого соответствуют кодируемым символам. При этом путь от вершины дерева до кодируемого символа определяет кодирующую последовательность битов: поворот налево дает 0, а поворот направо – 1. Оптимальному коду (для данного файла) всегда соответствует двоичное дерево, в котором всякая вершина, не являющаяся листом, имеет двоих детей. Такое свойство позволяет легко доказать, что дерево оптимального префиксного кода для файла, в котором используются все символы из некоторого множества С и только они, содержит только |С| листьев и ровно |C| –1 узлов, не являющихся листьями. Хаффман построил жадный алгоритм, который строит оптимальный префиксный код, который называют кодом Хаффмана. Алгоритм строит дерево Т, соответствующее оптимальному коду, снизу вверх, начиная с множества из |С| листьев и делая |С| –1 “слияний”. Предполагаем, что для каждого символа из С задана его частота f[c]. Для нахождения двух объектов, подлежащих слиянию, может быть использована очередь с приоритетами Q, использующая частоты f в качестве рангов – сливаются два объекта с наименьшими частотами. В результате слияния получается новый объект, частота которого считается равной сумме частот двух сливаемых объектов. Пример применения алгоритма Хаффмана. F:5 E:9 C:12 B:13 D:16 A:45 

Источник