Обход дерева предварительного заказа — итеративный и рекурсивный
Имея двоичное дерево, напишите итеративное и рекурсивное решение для обхода дерева с использованием обхода в прямом порядке в C++, Java и Python.
В отличие от связанных списков, одномерных массивов и других линейных структур данных, обход которых осуществляется в линейном порядке, по деревьям можно перемещаться несколькими способами. глубина первого порядка (предварительный заказ, в целях, а также постзаказ) или же ширина первого порядка (обход порядка уровней). Помимо этих основных обходов, возможны различные более сложные или гибридные схемы, такие как поиск с ограничением по глубине, например итеративный поиск в глубину с углублением. В этом посте подробно обсуждается обход дерева предварительного заказа.
Обход дерева включает в себя итерацию по всем узлам тем или иным образом. Поскольку дерево не является линейной структурой данных, может быть более одного возможного следующего узла от данного узла, поэтому некоторые узлы должны быть отложены, т. е. каким-то образом сохранены для последующего посещения. Обход может выполняться итеративно, когда отложенные узлы хранятся в stack, или это можно сделать с помощью рекурсия, где отложенные узлы неявно хранятся в стек вызовов.
Для обхода (непустого) бинарного дерева в предварительном порядке мы должны сделать эти три вещи для каждого узла. n начиная с корня дерева:
(N) Процесс n сам.
(L) Рекурсивно обходим его левое поддерево. Когда этот шаг будет завершен, мы вернемся к n опять таки.
(R) Рекурсивно обходим его правое поддерево. Когда этот шаг будет завершен, мы вернемся к n опять таки.
В обычном обходе в предварительном порядке посетите левое поддерево перед правым поддеревом. Если мы посещаем правое поддерево перед посещением левого поддерева, это называется обходом в обратном порядке.
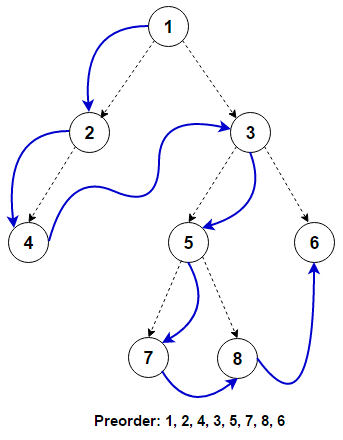
Рекурсивная реализация
Как мы видим, только после обработки любого узла обрабатывается левое поддерево, а за ним правое поддерево. Эти операции могут быть определены рекурсивно для каждого узла. Рекурсивная реализация называется Поиск в глубину (DFS), так как дерево поиска максимально углубляется для каждого дочернего элемента, прежде чем перейти к следующему родственному элементу.
Ниже приведена программа на C++, Java и Python, которая демонстрирует это:
Источник
Обход двоичного дерева
Теги: Обход двоичного дерева, прямой обход, обратный обход, симметричный обход, поперечный обход, сортировка дерева, удаление дерева, стек, очередь, итеративный обход дерева, рекурсивный обход дерева, поиск в глубину, поиск в ширину, обход бесконечных деревьев.
Обход дерева в глубину
В отличие от линейных структур типа односвязного списка и массива, у которых есть каноничный, прямой способ обхода, деревья можно обходить несколькими способами, в зависимости от поставленной задачи. Начиная с корня, можно применять необходимое действия (именуемое в дальнейшем «визит») как к самому узлу, так и к его левой или правой ветви. Порядок, в котором операции применяются, и будет определять способ обхода.
Наиболее простыми и понятными являются рекурсивные алгоритмы. При сведении к итеративному алгоритму, так как дерево предполагает несколько путей обхода, часть узлов придётся «откладывать» для дальнейшей обработки, для чего будут использоваться стек или очередь.
Существует три основных способа обхода в глубину.
- Прямой (pre-order)
Посетить корень
Обойти левое поддерево
Обойти правое поддерево
Рекурсивное решение полностью соответствует описанию алгоритма
void preOrderTravers(Node* root) < if (root) < printf("%d ", root->data); preOrderTravers(root->left); preOrderTravers(root->right); > > void inOrderTravers(Node* root) < if (root) < inOrderTravers(root->left); printf("%d ", root->data); inOrderTravers(root->right); > > void postOrderTravers(Node* root) < if (root) < postOrderTravers(root->left); postOrderTravers(root->right); printf("%d ", root->data); > > Переделаем функции, чтобы они могли работать с узлами. Для этого понадобится передавать функцию, которая могла бы работать с узлом и получать дополнительные параметры. Эти параметры будут передаваться указателем типа void. Если нам понадобится передать параметры, всегда можно будет их передать указателем на структуру.
void preOrderTravers(Node* root, void (*visit)(Node*, void*), void *params) < if (root) < visit(root, params); preOrderTravers(root->left, visit, params); preOrderTravers(root->right, visit, params); > > void inOrderTravers(Node* root, void (*visit)(Node*, void*), void *params) < if (root) < inOrderTravers(root->left, visit, params); visit(root, params); inOrderTravers(root->right, visit, params); > > void postOrderTravers(Node* root, void (*visit)(Node*, void*), void *params) < if (root) < postOrderTravers(root->left, visit, params); postOrderTravers(root->right, visit, params); visit(root, params); > >
В качестве функции visit можно передавать, например, такую функцию
void printNode(Node *current, void *args) < printf("%d ", current->data); > inOrderTravers(root, printNode, NULL);
Рассмотрим теперь результат каждого из обходов.
inOrderTraversal выводит сначала самый левый узел, потом средний, потом правый. Если слева находилось дерево, то алгоритм применяется к нему рекурсивно. Если мы обрабатываем двоичное дерево поиска, то самым левым будет самый маленький элемент, самым правым и самым последним при обработке будет самый большой элемент. Симметричный обход выведет дерево в отсортированном по возрастанию виде. Для того, чтобы отсортировать дерево в обратном порядке, нужно сначала обработать правую ветвь, то есть функция
void inOrderTraversRL(Node* root) < if (root) < inOrderTraversRL(root->right); printf("%d ", root->data); inOrderTraversRL(root->left); > > выведет дерево в обратном порядке.
postOrderTraversal выводит узлы слева направо, снизу вверх. Это имеет ряд применений, сейчас рассмотрим только одно – удаление дерева. Обход дерева начинается снизу, с узлов, у которых нет родителей. Их можно безболезненно удалять, так как обращение root->left и root->right происходят до удаления объекта.
void deleteTree(Node **root) < if (*root) < deleteTree(&((*root)->left)); deleteTree(&((*root)->right)); free(*root); > >
Напомню, что если мы хотим изменить указатель, то нужно передавать указатель на указатель.
Итеративная реализация обхода в глубину требует использования стека. Он нужен для того, чтобы «откладывать» на потом обработку некоторых узлов (например тех, у кого есть необработанные наследники, или всех левых улов и т.д.).
Реализовывать стек будем с помощью массива, который при переполнении будет изменять свой размер. Напомню, что реализация стека требует двух функций — push, которая кладёт значение на вершину стека и pop, которая снимает значение с вершины стека и возвращает его. Кроме того, будем использовать функцию peek, которая возвращает значение с вершины, но не удаляет его.
#define STACK_INIT_SIZE 100 typedef struct Stack < size_t size; size_t limit; Node **data; >Stack; Stack* createStack() < Stack *tmp = (Stack*) malloc(sizeof(Stack)); tmp->limit = STACK_INIT_SIZE; tmp->size = 0; tmp->data = (Node**) malloc(tmp->limit * sizeof(Node*)); return tmp; > void freeStack(Stack **s) < free((*s)->data); free(*s); *s = NULL; > void push(Stack *s, Node *item) < if (s->size >= s->limit) < s->limit *= 2; s->data = (Node**) realloc(s->data, s->limit * sizeof(Node*)); > s->data[s->size++] = item; > Node* pop(Stack *s) < if (s->size == 0) < exit(7); >s->size--; return s->data[s->size]; > Node* peek(Stack *s) < return s->data[s->size-1]; >
После того, как у нас готова реализация стека, напишем обходы.
iterativePreorder(node) parentStack = empty stack while (not parentStack.isEmpty() or node ≠ null) if (node ≠ null) visit(node) parentStack.push(node) node = node.left else node = parentStack.pop() node = node.right
void iterPreorder(Node *root) < Stack *ps = createStack(); while (ps->size != 0 || root != NULL) < if (root != NULL) < printf("visited %d\n", root->data); if (root->right) < push(ps, root->right); > root = root->left; > else < root = pop(ps); >> freeStack(&ps); > iterativeInorder(node) parentStack = empty stack while (not parentStack.isEmpty() or node ≠ null) if (node ≠ null) parentStack.push(node) node = node.left else node = parentStack.pop() visit(node) node = node.right
void iterInorder(Node *root) < Stack *ps = createStack(); while (ps->size != 0 || root != NULL) < if (root != NULL) < push(ps, root); root = root->left; > else < root = pop(ps); printf("visited %d\n", root->data); root = root->right; > > freeStack(&ps); > iterativePostorder(node) parentStack = empty stack lastnodevisited = null while (not parentStack.isEmpty() or node ≠ null) if (node ≠ null) parentStack.push(node) node = node->left else peeknode = parentStack.peek() if (peeknode->right ≠ null and lastnodevisited ≠ peeknode->right) /* if traversing node from left child AND right child exists, move right */ node = peeknode->right else parentStack.pop() visit(peeknode) lastnodevisited = peeknode
void iterPostorder(Node *root) < Stack *ps = createStack(); Node *lnp = NULL; Node *peekn = NULL; while (!ps->size == 0 || root != NULL) < if (root) < push(ps, root); root = root->left; > else < peekn = peek(ps); if (peekn->right && lnp != peekn->right) < root = peekn->right; > else < pop(ps); printf("visited %d\n", peekn->data); lnp = peekn; > > > freeStack(&ps); > Обход в ширину
О бход в ширину подразумевает, что сначала мы посещаем корень, затем, слева направо, все ветви первого уровня, затем все ветви второго уровня и т.д.
Пусть мы находимся в корне дерева. Далее необходимо посетить всех наследников корня. Таким образом, нужно засунуть в контейнер сначала узел, затем его наследников, при этом узел далее должен быть обработан первым. То есть, элемент, который вошёл первым должен быть обработан первым. Это очередь, и в этом примере мы будем использовать готовую реализацию очереди с помощью двусвязного списка.
breadthFirst(root) q = empty queue q.enqueue(root) while not q.empty do node := q.dequeue() visit(node) if node.left ≠ null then q.enqueue(node.left) if node.right ≠ null then q.enqueue(node.right)
void breadthFirst(Node* root) < DblLinkedList *q = createDblLinkedList(); //Для начала поместим в очередь корень pushBack(q, root); while (q->size != 0) < Node *tmp = (Node*) popFront(q); printf("%d ", tmp->data); //Если есть левый наследник, то помещаем его в очередь для дальнейшей обработки if (tmp->left) < pushBack(q, tmp->left); > //Если есть правый наследник, то помещаем его в очередь для дальнейшей обработки if (tmp->right) < pushBack(q, tmp->right); > > deleteDblLinkedList(&q); > void breadthFirstWakaWaka(Node* root) < DblLinkedList *q = createDblLinkedList(); pushFront(q, root); while (q->size != 0) < Node *tmp = (Node*) popFront(q); printf("%d ", tmp->data); if (tmp->left) < pushFront(q, tmp->left); > if (tmp->right) < pushFront(q, tmp->right); > > deleteDblLinkedList(&q); > Теперь функция обходит узлы как Post-Order, только задом наперёд.
Обход бесконечных деревьев
Б ывают ситуации, когда необходимо обработать бесконечное дерево. Дерево может генерироваться, когда мы обращаемся к нему (например, мы обходим сайт, страницы которого генерируются сервером во время обращения), либо его размер просто не известен (и возможно велик).
Если дерево растёт бесконечно в глубину, то его можно обрабатывать, используя проход в ширину. То есть, известно, что если спускаться вниз по ветви, то до конца мы не дойдём, но на данном уровне дерево имеет конечный размер.
Если дерево растёт бесконечно в ширину, но при этом имеет конечную глубину (то есть, у узла не два наследника, а из бесконечно много), то можно использовать поиск в глубину.
Обработку бесконечного дерева можно заканчивать например, когда обработано достаточно большое количество узлов или их значения достигли какой-то величины.
Пусть робот «шмугл» индексирует страницы на сайте. Количество ссылок на странице конечно. (т.к. страница конечна). То есть можно рассматривать страницы как узел, ссылки с которой ведут к другим узлам. Конечно, есть ссылки, которые ведут на предыдущие страницы, есть кросс-ссылки между страницами на одном уровне вложенности и т.д., сейчас всех тонкостей рассматривать не будем. То есть, есть дерево, у каждого узла которого конечное число наследников. В лучшем случае количество ссылок конечно и охватывает весь сайт. Однако, может попасться страница, на которой есть календарь, ссылки с которого генерируются автоматически. Программист забыл, что ссылки в будущее надо запретить, поэтому в глубину мы получаем бесконечно дерево, каждый новый узел которого генерируется автоматически. Обход этого дерева закончится, например, когда будет забит канал или превышен лимит по ссылкам.

Всё ещё не понятно? – пиши вопросы на ящик
Источник