Обход дерева в глубину с рекурсией
При первом знакомстве с понятием рекурсии (вики) при изучении программирования она может показаться сложной и неизвестно зачем придуманной (по крайней мере, у меня так было).
Однако, в случае рекурсивных (рекурсивно определяемых) структур данных (в том числе и в случае дерева) рекурсия существенно упрощает написание программ (в частности, реализацию алгоритма обхода дерева в глубину). Поэтому я считаю, что при изучении алгоритмов обхода дерева сначала стоит изучить обход дерева без рекурсии, а только потом — обход дерева с рекурсией, чтобы сразу стала видна польза от применения рекурсии.
Почему дерево — это рекурсивно определяемая структура данных? Потому что эта структура данных повторяет саму себя в своих частях. Об этом можно почитать в подразделе 6.1 «Рекурсия и стек» учебника по JavaScript.
У рекурсивного способа реализации алгоритма обхода дерева в глубину, однако, есть недостаток. При слишком больших деревьях этот способ может вызвать переполнение стека вызовов (вики). Поэтому, к примеру, для обработки небольших менюшек древовидной структуры удобнее использовать обход дерева с рекурсией, а вот, к примеру, для обработки некоего большого HTML-документа (или XML-документа), а точнее, элементов его DOM-дерева (про это понятие можно почитать в подразделе 1.2 «DOM-дерево» второй части упомянутого выше учебника), возможно, будет целесообразнее использовать обход дерева без рекурсии, чтобы не нарваться на переполнение стека вызовов.
Итак, почему же обход дерева в глубину с рекурсией проще реализовать, чем обход дерева в глубину без рекурсии? Дело в том, что так как дерево — рекурсивно определяемая структура данных, то при построении алгоритма его обхода с помощью рекурсии достаточно рассмотреть и реализовать обработку лишь одного узла дерева.
Рассмотрим при обходе дерева посещение любого одного узла. При рекурсии сначала следует определить условие завершения работы функции. Этим условием будем считать установление факта, что данный узел является листом дерева. Если узел не является листом дерева, то следует последовательно (в цикле) перейти (в нашем случае, как мы договорились в предыдущем посте, с приоритетом справа налево) по веткам на следующий, нижний, уровень дерева и запустить для каждой из этих веток (ссылок) эту же функцию (это и есть рекурсия).
Пишем код на языке JavaScript:
function traversal(tree) < // . обработка данных узла. console.log(tree.data); // просто выводим в консоль // если это лист, завершить функцию if ( !tree.refs ) return; // последовательно справа налево обходим ветви, ведущие из текущего узла for (let i = tree.refs.length - 1; i >= 0; i--) < traversal( tree.refs[i] ); // рекурсия > >
Для проверки работы этой функции можно взять тестовое дерево из предыдущего поста. Запуск функции там тоже был показан, а результат работы скрипта должен быть таким же, как в прошлом посте.
А теперь сравните с вариантом реализации обхода дерева без рекурсии, продемонстрированном в прошлом посте:
function traversal(tree) < let cur_ref; // текущая ссылка let memory = [tree]; // память (стек) // в начале память содержит ссылку на корень заданного дерева // внешний цикл, перебирающий линии заглублений // закончить цикл, если не получается извлечь ссылку из памяти (стека) while ( cur_ref = memory.pop() ) < // внутренний цикл обхода каждой линии заглубления дерева до листа while ( true ) < // . обработка данных узла. console.log(cur_ref.data); // просто выводим в консоль // если это лист, выйти из цикла if ( !cur_ref.refs ) break; // помещаем ветви, ведущие налево, в память (стек) for (let i = 0; i < cur_ref.refs.length - 1; i++) < memory.push( cur_ref.refs[i] ); >// переходим по ветви, ведущей направо cur_ref = cur_ref.refs[cur_ref.refs.length - 1]; > > >
Результат налицо. Понятно, какой вариант проще написать.
В случае с рекурсией запоминание ветвей на развилках дерева и разных промежуточных данных выполняет движок JavaScript в упомянутом выше стеке вызовов. То есть всю грязную работу делает движок, а программист наслаждается жизнью.
Источник
Обход бинарных деревьев: рекурсия, итерации и указатель на родителя
Основы о бинарных деревьях представлены, в том числе, здесь . Добавлю свои «5 копеек» и данным постом систематизирую материалы, связанные с обходом бинарных деревьев, а именно сравнений возможностей рекурсии и итераций, а также обсуждение возможностей использования указателя на родительский узел.
Итак… язык Java, класс узла имеет следующий вид:
Примечание: Указатель на родителя parent – как правило не имеет большого смысла, однако, как следует из заголовка и будет показано, может быть полезен в ряде случаев.
Обход деревьев – последовательная обработка (просмотр, изменение и т.п.) всех узлов дерева, при котором каждый узел обрабатывается строго один раз. При этом получается линейная расстановка узлов дерева.
В зависимости от траекторий выделяют два типа обхода:
— горизонтальный (в ширину); и
— вертикальный (в глубину).

Горизонтальный обход подразумевает обход дерева по уровням (level-ordered) – вначале обрабатываются все узлы текущего уровня, после чего осуществляется переход на нижний уровень.

При вертикальном обходе порядок обработки текущего узла и узлов его правого и левого поддеревьев варьирует и по этому признаку выделяют три варианта вертикального обхода:
— прямой (префиксный, pre-ordered): вершина – левое поддерево – правое поддерево;
— обратный (инфиксный, in-ordered): левое поддерево – вершина – правое поддерево; и
— концевой (постфиксный, post-ordered): левое поддерево – правое поддерево – вершина.
Сам обход во всех случаях в принципе один и тот же, различается порядок обработки. Для представления в каком порядке будет проходить обработка узлов дерева удобно следовать по «контуру обхода». При прямом обходе узел будет обработан в точке слева от узла, при обратном снизу от узла и при концевом, соответственно, справа от узла.
Другими словами «находясь» в некотором узле, нам нужно знать, нужно ли его обрабатывать и куда двигаться дальше.
Рекурсия
Все три варианта вертикального обхода элементарно реализуются рекурсивными функциями.
void recPreOrder() < treatment(); if (left!=null) left.recPreOrder(); if (right!=null) right.recPreOrder(); >void recInOrder() < if (left!=null) left.recInOrder(); treatment(); if (right!=null) right.recInOrder(); >void recPostOrder()
Рекурсия крайне удобна не только при обходе, но также при построении дерева, поиска в дереве, а также балансировки. Однако рекурсией нельзя осуществить горизонтальный обход дерева. В этом случае, а так же при обеспокоенности перегрузкой программного стека, следует применять итерационный подход.
Контейнеры
В случае использования итераций необходимо хранить сведенья о посещенных, но не обработанных узлах. Используются контейнеры типа стек (для вертикального обхода) и очередь (для горизонтального обхода).
Горизонтальный обход:
обрабатываем первый в очереди узел, при наличии дочерних узлов заносим их в конец очереди. Переходим к следующей итерации.
static void contLevelOrder(Node top) < Queuequeue=new LinkedList<> (); do< top.treatment(); if (top.left!=null) queue.add(top.left); if (top.right!=null) queue.add(top.right); if (!queue.isEmpty()) top=queue.poll(); >while (!queue.isEmpty()); > Вертикальный прямой обход:
обрабатываем текущий узел, при наличии правого поддерева добавляем его в стек для последующей обработки. Переходим к узлу левого поддерева. Если левого узла нет, переходим к верхнему узлу из стека.
static void contPreOrder(Node top) < Stackstack = new Stack<> (); while (top!=null || !stack.empty()) < if (!stack.empty())< top=stack.pop(); >while (top!=null) < top.treatment(); if (top.right!=null) stack.push(top.right); top=top.left; >> > Вертикальный обратный обход:
из текущего узла «спускаемся» до самого нижнего левого узла, добавляя в стек все посещенные узлы. Обрабатываем верхний узел из стека. Если в текущем узле имеется правое поддерево, начинаем следующую итерацию с правого узла. Если правого узла нет, пропускаем шаг со спуском и переходим к обработке следующего узла из стека.
static void contInOrder(Node top) < Stackstack = new Stack<> (); while (top!=null || !stack.empty()) < if (!stack.empty())< top=stack.pop(); top.treatment(); if (top.right!=null) top=top.right; else top=null; >while (top!=null) < stack.push(top); top=top.left; >> > Вертикальный концевой обход:
Здесь ситуация усложняется – в отличие от обратного обхода, помимо порядка спуска нужно знать обработано ли уже правое поддерево. Одним из вариантов решения является внесение в каждый экземпляр узла флага, который бы хранил соответствующую информацию (не рассматривается). Другим подходом является «кодирование» непосредственно в очередности стека — при спуске, если у очередного узла позже нужно будет обработать еще правое поддерево, в стек вносится последовательность «родитель, правый узел, родитель». Таким образом, при обработке узлов из стека мы сможем определить, нужно ли нам обрабатывать правое поддерево.
static void contPostOrder(Node top) < Stackstack = new Stack<> (); while (top!=null || !stack.empty())< if (!stack.empty())< top=stack.pop(); if (!stack.empty() && top.right==stack.lastElement())< top=stack.pop(); >else < top.treatment(); top=null; >> while (top!=null) < stack.push(top); if (top.right!=null)< stack.push(top.right); stack.push(top); >top=top.left; > > > Об указателе на родителя
Наличие в экземпляре класса указателя на родителя приносит определенные хлопоты при построении и балансировки деревьев. Однако, возможность из произвольного узла дерева «дойти» до любого из его узлов может придтись весьма кстати. Все, за чем нужно следить при «подъеме» на верхний уровень – пришли ли от правого потомка или от левого.
Так, с использованием родительских указателей будет выглядеть код вертикального концевого обхода.
static void parentPostOrder(Node top) < boolean fromright=false; Node shuttle=top, holder; while(true)< while (fromright)< shuttle.treatment(); if (shuttle==top) return; holder=shuttle; shuttle=shuttle.parent; fromright=shuttle.right==holder; if (!fromright && shuttle.right!=null) shuttle=shuttle.right; else fromright=true; >while (shuttle.left!=null) shuttle=shuttle.left; if (shuttle.right!=null) shuttle=shuttle.right; else fromright=true; > > Другой класс задач, которые позволяет решить родительский указатель, как уже было упомянуто — перемещение внутри дерева.
Так, что бы перейти на n-ый по счету узел от текущего узла, без «ориентации в дереве» пришлось бы обходить дерево с самого начала, до известного узла, а потом еще n-узлов. С использованием же родительского указателя при обратном обходе дерева перемещение на steps узлов от текущего узла (start) будет иметь следующий вид.
public static Node walkTheTree(Node start, int steps) < boolean fromright=true; Node shuttle=start, holder; if (shuttle.right!=null)< shuttle=shuttle.right; while (shuttle.left!=null) shuttle=shuttle.left; fromright=false; >int counter=0; do < while (true)< if (!fromright && ++counter==steps) return shuttle; if (!fromright && shuttle.right!=null)< shuttle=shuttle.right; break; >holder=shuttle; shuttle=shuttle.parent; fromright=(holder==shuttle.right); > while (shuttle.left!=null) shuttle=shuttle.left; >while (true); > Примечание: В общем случае также требуется предотвратить возможность попытки выхода за пределы дерева (подняться выше корневого узла).
Источник
Неупорядоченный обход дерева — итеративный и рекурсивный
Имея двоичное дерево, напишите итеративное и рекурсивное решение для обхода дерева с использованием неупорядоченного обхода в C++, Java и Python.
В отличие от связанных списков, одномерных массивов и других линейных структур данных, обход которых осуществляется в линейном порядке, по деревьям можно перемещаться несколькими способами. глубина первого порядка (предварительный заказ, в целях, а также постзаказ) или же ширина первого порядка (обход порядка уровней). Помимо этих основных обходов, возможны различные более сложные или гибридные схемы, такие как поиск с ограничением по глубине, например итеративный поиск в глубину с углублением. В этом посте подробно обсуждается упорядоченный обход дерева.
Обход дерева включает в себя итерацию по всем узлам тем или иным образом. Поскольку дерево не является линейной структурой данных, может быть более одного возможного следующего узла от данного узла, поэтому некоторые узлы должны быть отложены, т. е. каким-то образом сохранены для последующего посещения. Обход может выполняться итеративно, когда отложенные узлы хранятся в stack, или это можно сделать с помощью рекурсия, где отложенные узлы неявно хранятся в стек вызовов.
Для обхода (непустого) бинарного дерева неупорядоченным образом мы должны сделать эти три вещи для каждого узла. n начиная с корня дерева:
(L) Рекурсивно обходим его левое поддерево. Когда этот шаг будет завершен, мы вернемся к n опять таки.
(N) Процесс n сам.
(R) Рекурсивно обходим его правое поддерево. Когда этот шаг будет завершен, мы вернемся к n опять таки.
При обычном упорядоченном обходе мы посещаем левое поддерево перед правым поддеревом. Если мы посещаем правое поддерево перед посещением левого поддерева, это называется обратным неупорядоченным обходом.
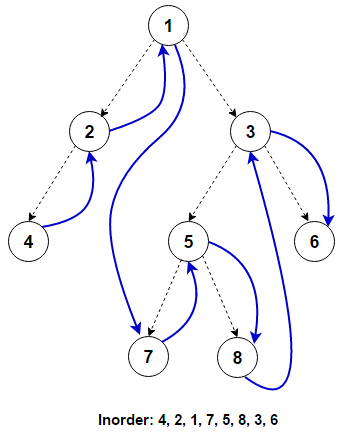
Рекурсивная реализация
Как мы видим, перед обработкой любого узла сначала обрабатывается левое поддерево, затем узел, а правое поддерево обрабатывается последним. Эти операции могут быть определены рекурсивно для каждого узла. Рекурсивная реализация называется Поиск в глубину (DFS), так как дерево поиска максимально углубляется для каждого дочернего элемента, прежде чем перейти к следующему родственному элементу.
Ниже приведена программа на C++, Java и Python, которая демонстрирует это:
Источник