- Using red black trees for sorting
- 6 Answers 6
- Красно-черные деревья: коротко и ясно
- Как бинарное дерево, красно-черное обладает свойствами:
- ключи всех левых потомков (в других определениях дубликаты должны располагаться с правой стороны либо вообще отсутствовать). Это неравенство должно быть истинным для всех потомков узла, а не только его дочерних узлов. Свойства красно-черных деревьев: 1) Каждый узел окрашен либо в красный, либо в черный цвет (в структуре данных узла появляется дополнительное поле – бит цвета). 2) Корень окрашен в черный цвет. 3) Листья(так называемые NULL-узлы) окрашены в черный цвет. 4) Каждый красный узел должен иметь два черных дочерних узла. Нужно отметить, что у черного узла могут быть черные дочерние узлы. Красные узлы в качестве дочерних могут иметь только черные. 5) Пути от узла к его листьям должны содержать одинаковое количество черных узлов(это черная высота). Ну и почему такое дерево является сбалансированным? Действительно, красно-черные деревья не гарантируют строгой сбалансированности (разница высот двух поддеревьев любого узла не должна превышать 1), как в АВЛ-деревьях. Но соблюдение свойств красно-черного дерева позволяет обеспечить выполнение операций вставки, удаления и выборки за время . И сейчас посмотрим, действительно ли это так. Пусть у нас есть красно-черное дерево. Черная высота равна (black height). Если путь от корневого узла до листового содержит минимальное количество красных узлов (т.е. ноль), значит этот путь равен . Если же путь содержит максимальное количество красных узлов ( в соответствии со свойством ), то этот путь будет равен . То есть, пути из корня к листьям могут различаться не более, чем вдвое (, где h — высота поддерева), этого достаточно, чтобы время выполнения операций в таком дереве было Как производится вставка? Вставка в красно-черное дерево начинается со вставки элемента, как в обычном бинарном дереве поиска. Только здесь элементы вставляются в позиции NULL-листьев. Вставленный узел всегда окрашивается в красный цвет. Далее идет процедура проверки сохранения свойств красно-черного дерева . Свойство 1 не нарушается, поскольку новому узлу сразу присваивается красный цвет. Свойство 2 нарушается только в том случае, если у нас было пустое дерево и первый вставленный узел (он же корень) окрашен в красный цвет. Здесь достаточно просто перекрасить корень в черный цвет. Свойство 3 также не нарушается, поскольку при добавлении узла он получает черные листовые NULL-узлы. В основном встречаются 2 других нарушения: 1) Красный узел имеет красный дочерний узел (нарушено свойство ). 2) Пути в дереве содержат разное количество черных узлов (нарушено свойство ). Подробнее о балансировке красно-черного дерева при разных случаях (их пять, если включить нарушение свойства ) можно почитать на wiki. Это вообще где-то используется? Да! Когда в институте на третьем курсе нам читали «Алгоритмы и структуры данных», я и не могла представить, что красно-черные деревья где-то используются. Помню, как мы не любили тему сбалансированных деревьев. Ох уж эти родственные связи в красно-черных деревьях («дядя», «дедушка», «чёрный брат и крестный красный отец»), прям Санта-Барбара какая-то. Правые и левые, малые и большие повороты АВЛ-деревьев – сплошные американские горки. Вы тоже не любите красно-черные деревья? Значит, просто не умеете их готовить. А кто-то просто взял и приготовил. Так, например, ассоциативные массивы в большинстве библиотек реализованы именно через красно-черные деревья. Это все, что я хотела рассказать. Источник
- Свойства красно-черных деревьев:
- Ну и почему такое дерево является сбалансированным?
- Как производится вставка?
- Это вообще где-то используется?
Using red black trees for sorting
The worst-case running time of insertion on a red-black tree is O(lg n) and if I perform a in-order walk on the tree, I essentially visit each node, so the total worst-case runtime to print the sorted collection would be O(n lg n) I am curious, why are red-black trees not preferred for sorting over quick sort (whose average-case running time is O(n lg n) . I see that maybe because red-black trees do not sort in-place, but I am not sure, so maybe someone could help.
An in-order walk over a tree takes O(1) time per node visited, so it should run in O(n) not O(n lg n).
6 Answers 6
Knowing which sort algorithm performs better really depend on your data and situation.
If you are talking in general/practical terms,
Quicksort (the one where you select the pivot randomly/just pick one fixed, making worst case Omega(n^2)) might be better than Red-Black Trees because (not necessarily in order of importance)
- Quicksort is in-place. The keeps your memory footprint low. Say this quicksort routine was part of a program which deals with a lot of data. If you kept using large amounts of memory, your OS could start swapping your process memory and trash your perf.
- Quicksort memory accesses are localized. This plays well with the caching/swapping.
- Quicksort can be easily parallelized (probably more relevant these days).
- If you were to try and optimize binary tree sorting (using binary tree without balancing) by using an array instead, you will end up doing something like Quicksort!
- Red-Black trees have memory overheads. You have to allocate nodes possibly multiple times, your memory requirements with trees is doubles/triple that using arrays.
- After sorting, say you wanted the 1045th (say) element, you will need to maintain order statistics in your tree (extra memory cost because of this) and you will have O(logn) access time!
- Red-black trees have overheads just to access the next element (pointer lookups)
- Red-black trees do not play well with the cache and the pointer accesses could induce more swapping.
- Rotation in red-black trees will increase the constant factor in the O(nlogn).
- Perhaps the most important reason (but not valid if you have lib etc available), Quicksort is very simple to understand and implement. Even a school kid can understand it!
I would say you try to measure both implementations and see what happens!
Also, Bob Sedgewick did a thesis on quicksort! Might be worth reading.
You can implement red-black trees where nodes are only allocated once, rotation can be done by pure pointer swizzling. But of course a node needs a constant factor more space than an array cell.
There are plenty of sorting algorithms which are worst case O(n log n) — for example, merge sort. The reason quicksort is preferred is because it is faster in practice, even though algorithmically it may not be as good as some other algorithms.
Often in-built sorts use a combination of various methods depending on the values of n.
but merge-sort does not sort in-place, and how is quick-sort faster in practice? (I never understood it, although I find it thrown at me every time I ask this question)
All sorting algorithms have their own hidden constants factors involved, and while perhaps you could find papers on why this is the case with a bit of searching, trying to decide which actually performs faster theoretically isn’t that easy. In practice means exactly that — if you compare the sorting algorithms on real data, you will find that quicksort inevitably has a faster runtime.
Quicksort is not always faster. If you keep increasing the number of elements, an O(n log n) algorithm will inevitably beat an O(n^2) algorithm at some time. However for small n, the constant factors have a much stronger impact and the O(n^2) algorithm may actually be the faster solution. Consider for example 10000*n and 100*n^2. At first, 100*n^2 will yield smaller values, but at n=100 the linear function catches up and produces smaller values for all further n. The effect is the same for quicksort and for most «practical» n it is faster.
@Gnafoo — The analysis in your example is correct, but in this case two algorithms with the same O(n log n) average time complexity are being compared. Average time complexity is usually what matters in most real-world applications; worst-case time-complexity is usually only relevant for those few scenarios with hard execution time bound requirements.
There are many cases where red-back trees are not bad for sorting. My testing showed, compared to natural merge sort, that red-black trees excel where:
Trees are better for Dups: All the tests where dups need to be eleminated, tree algorithm is better. This is not astonishing, since the tree can be kept very small from the beginning, whereby algorithms that are designed for inline array sort might pass around larger segments for a longer time.
Trees are better for Random: All the tests with random, tree algorithm is better. This is also not astonishing, since in a tree distance between elements is shorter and shifting is not necessary. So repeatedly inserting into a tree could need less effort than sorting an array.
So we get the impression that the natural merge sort only excels in ascending and descending special cases. Which cant be even said for quick sort.
P.S.: it should be noted that using trees for sorting is non-trivial. One has not only to provide an insert routine but also a routine that can linearize the tree back to an array. We are currently using a get_last and a predecessor routine, which doesn’t need a stack. But these routines are not O(1) since they contain loops.
Источник
Красно-черные деревья: коротко и ясно
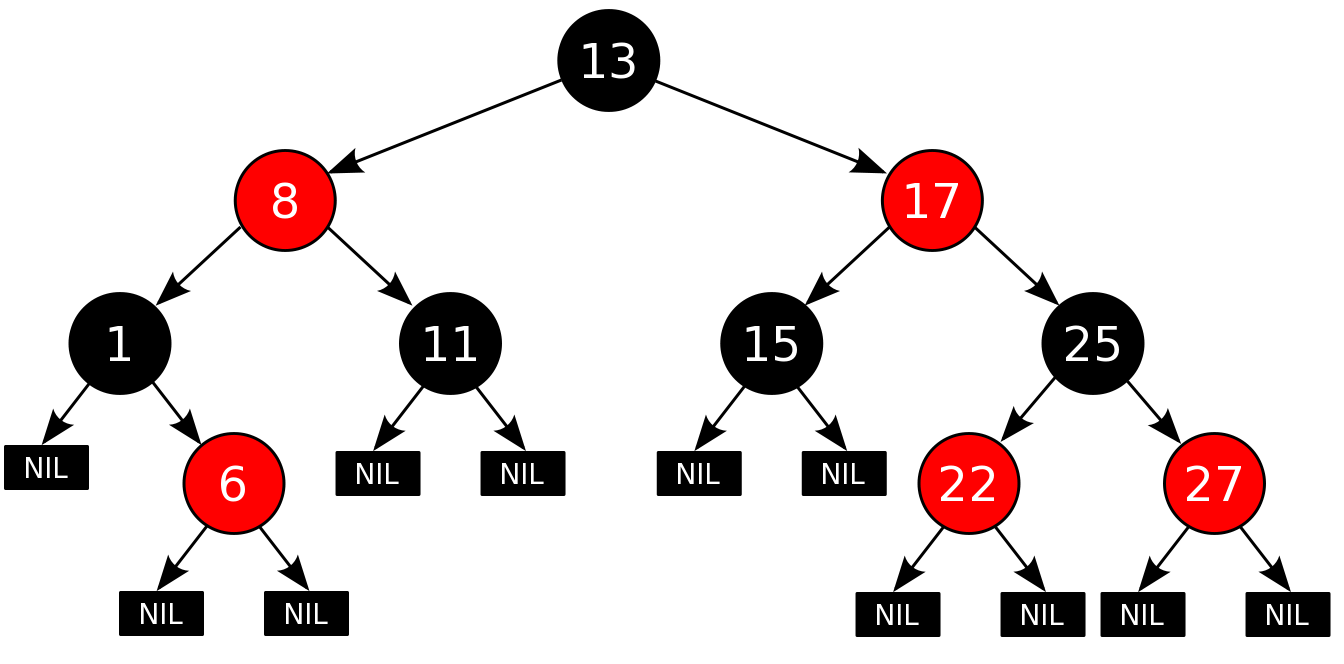
Итак, сегодня хочу немного рассказать о красно-черных деревьях. Рассказ будет кратким, без рассмотрения алгоритмов балансировки при вставке/удалении элементов в красно-черных деревьях.
Красно-черные деревья относятся к сбалансированным бинарным деревьям поиска.
Как бинарное дерево, красно-черное обладает свойствами:
1) Оба поддерева являются бинарными деревьями поиска.
2) Для каждого узла с ключом выполняется критерий упорядочения:
ключи всех левых потомков
(в других определениях дубликаты должны располагаться с правой стороны либо вообще отсутствовать).
Это неравенство должно быть истинным для всех потомков узла, а не только его дочерних узлов.
Свойства красно-черных деревьев:
1) Каждый узел окрашен либо в красный, либо в черный цвет (в структуре данных узла появляется дополнительное поле – бит цвета).
2) Корень окрашен в черный цвет.
3) Листья(так называемые NULL-узлы) окрашены в черный цвет.
4) Каждый красный узел должен иметь два черных дочерних узла. Нужно отметить, что у черного узла могут быть черные дочерние узлы. Красные узлы в качестве дочерних могут иметь только черные.
5) Пути от узла к его листьям должны содержать одинаковое количество черных узлов(это черная высота).
Ну и почему такое дерево является сбалансированным?
Действительно, красно-черные деревья не гарантируют строгой сбалансированности (разница высот двух поддеревьев любого узла не должна превышать 1), как в АВЛ-деревьях. Но соблюдение свойств красно-черного дерева позволяет обеспечить выполнение операций вставки, удаления и выборки за время . И сейчас посмотрим, действительно ли это так.
Пусть у нас есть красно-черное дерево. Черная высота равна (black height).
Если путь от корневого узла до листового содержит минимальное количество красных узлов (т.е. ноль), значит этот путь равен .
Если же путь содержит максимальное количество красных узлов ( в соответствии со свойством ), то этот путь будет равен .
То есть, пути из корня к листьям могут различаться не более, чем вдвое (, где h — высота поддерева), этого достаточно, чтобы время выполнения операций в таком дереве было
Как производится вставка?
Вставка в красно-черное дерево начинается со вставки элемента, как в обычном бинарном дереве поиска. Только здесь элементы вставляются в позиции NULL-листьев. Вставленный узел всегда окрашивается в красный цвет. Далее идет процедура проверки сохранения свойств красно-черного дерева .
Свойство 1 не нарушается, поскольку новому узлу сразу присваивается красный цвет.
Свойство 2 нарушается только в том случае, если у нас было пустое дерево и первый вставленный узел (он же корень) окрашен в красный цвет. Здесь достаточно просто перекрасить корень в черный цвет.
Свойство 3 также не нарушается, поскольку при добавлении узла он получает черные листовые NULL-узлы.
В основном встречаются 2 других нарушения:
1) Красный узел имеет красный дочерний узел (нарушено свойство ).
2) Пути в дереве содержат разное количество черных узлов (нарушено свойство ).
Подробнее о балансировке красно-черного дерева при разных случаях (их пять, если включить нарушение свойства ) можно почитать на wiki.
Это вообще где-то используется?
Да! Когда в институте на третьем курсе нам читали «Алгоритмы и структуры данных», я и не могла представить, что красно-черные деревья где-то используются. Помню, как мы не любили тему сбалансированных деревьев. Ох уж эти родственные связи в красно-черных деревьях («дядя», «дедушка», «чёрный брат и крестный красный отец»), прям Санта-Барбара какая-то. Правые и левые, малые и большие повороты АВЛ-деревьев – сплошные американские горки. Вы тоже не любите красно-черные деревья? Значит, просто не умеете их готовить. А кто-то просто взял и приготовил. Так, например, ассоциативные массивы в большинстве библиотек реализованы именно через красно-черные деревья.
Это все, что я хотела рассказать.
Источник