- Сортировка с помощью двоичного дерева
- Алгоритм
- Эффективность
- Примеры реализации
- См. также
- Сортировка с помощью дерева
- Комментариев к записи: 3
- Сортировка бинарным деревом
- Принцип работы алгоритма сортировки бинарным деревом
- Реализация алгоритма сортировки бинарным деревом
- Сортировка с помощью дерева (Heapsort)
Сортировка с помощью двоичного дерева
Сортировка с помощью двоичного дерева (сортировка двоичным деревом, сортировка деревом, древесная сортировка, сортировка с помощью бинарного дерева, англ. tree sort ) — универсальный алгоритм сортировки, заключающийся в построении двоичного дерева поиска по ключам массива (списка), с последующей сборкой результирующего массива путём обхода узлов построенного дерева в необходимом порядке следования ключей. Данная сортировка является оптимальной при получении данных путём непосредственного чтения с потока (например с файла, сокета или консоли).
Алгоритм
1. Построение двоичного дерева.
2. Сборка результирующего массива путём обхода узлов в необходимом порядке следования ключей.
Эффективность
Процедура добавления объекта в бинарное дерево имеет среднюю алгоритмическую сложность порядка O(log(n)). Соответственно, для n объектов сложность будет составлять O(n log(n)), что относит сортировку с помощью двоичного дерева к группе «быстрых сортировок». Однако, сложность добавления объекта в разбалансированное дерево может достигать O(n), что может привести к общей сложности порядка O(n²).
При физическом развёртывании древовидной структуры в памяти требуется не менее чем 4n ячеек дополнительной памяти (каждый узел должен содержать ссылки на элемент исходного массива, на родительский элемент, на левый и правый лист), однако, существуют способы уменьшить требуемую дополнительную память.
Примеры реализации
В простой форме функционального программирования на Haskell данный алгоритм будет выглядеть так:
data Tree a = Leaf | Node (Tree a) a (Tree a) insert :: Ord a => a -> Tree a -> Tree a insert x Leaf = Node Leaf x Leaf insert x (Node t y t') | x insert x (Node t y t') | x > y = Node t y (insert x t') flatten :: Tree a -> [a] flatten Leaf = [] flatten (Node t x t') = flatten t ++ [x] ++ flatten t' treesort :: Ord a => [a] -> [a] treesort = flatten . foldr insert Leaf
#include #include #include template typename Iterator> void binary_tree_sort(Iterator begin, Iterator end) std::multisettypename std::iterator_traitsIterator>::value_type> tree(begin, end); std::copy(tree.begin(), tree.end(), begin); >; Пример создания бинарного дерева и сортировки на языке Java:
// Скомпилируйте и введите java TreeSort class Tree public Tree left; // левое и правое поддеревья и ключ public Tree right; public int key; public Tree(int k) // конструктор с инициализацией ключа key = k; > /* insert (добавление нового поддерева (ключа)) сравнить ключ добавляемого поддерева (К) с ключом корневого узла (X). Если K>=X, рекурсивно добавить новое дерево в правое поддерево. Если K public void insert( Tree aTree) if ( aTree.key key ) if ( left != null ) left.insert( aTree ); else left = aTree; else if ( right != null ) right.insert( aTree ); else right = aTree; > /* traverse (обход) Рекурсивно обойти левое поддерево. Применить функцию f (печать) к корневому узлу. Рекурсивно обойти правое поддерево. */ public void traverse(TreeVisitor visitor) if ( left != null) left.traverse( visitor ); visitor.visit(this); if ( right != null ) right.traverse( visitor ); > > interface TreeVisitor public void visit(Tree node); >; class KeyPrinter implements TreeVisitor public void visit(Tree node) System.out.println( " " + node.key ); > >; public class TreeSort public static void main(String args[]) Tree myTree; myTree = new Tree( 7 ); // создать дерево (с ключом) myTree.insert( new Tree( 5 ) ); // присоединять поддеревья myTree.insert( new Tree( 9 ) ); myTree.traverse(new KeyPrinter()); > >
См. также
Источник
Сортировка с помощью дерева
Сортировка с помощью дерева осуществляется на основе бинарного дерева поиска.
Бинарное (двоичное) дерево поиска – это бинарное дерево, для которого выполняются следующие дополнительные условия (свойства дерева поиска):
- оба поддерева – левое и правое, являются двоичными деревьями поиска;
- у всех узлов левого поддерева произвольного узла X значения ключей данных меньше, чем значение ключа данных самого узла X;
- у всех узлов правого поддерева произвольного узла X значения ключей данных не меньше, чем значение ключа данных узла X.
Данные в каждом узле должны обладать ключами, на которых определена операция сравнения меньше.
Для сортировки с помощью дерева исходная сортируемая последовательность представляется в виде структуры данных «дерево».
Например, исходная последовательность имеет вид:
4, 3, 5, 1, 7, 8, 6, 2
Корнем дерева будет начальный элемент последовательности. Далее все элементы, меньшие корневого, располагаются в левом поддереве, все элементы, большие корневого, располагаются в правом поддереве. Причем это правило должно соблюдаться на каждом уровне.

После того, как все элементы размещены в структуре «дерево», необходимо вывести их, используя инфиксную форму обхода.
Реализация сортировки с помощью дерева на C++
#include
using namespace std;
// Структура — узел дерева
struct tnode
int field; // поле данных
struct tnode *left; // левый потомок
struct tnode *right; // правый потомок
>;
// Вывод узлов дерева (обход в инфиксной форме)
void treeprint(tnode *tree)
if (tree != NULL ) < //Пока не встретится пустой узел
treeprint(tree->left); //Рекурсивная функция вывода левого поддерева
cout field treeprint(tree->right); //Рекурсивная функция вывода правого поддерева
>
>
// Добавление узлов в дерево
struct tnode * addnode( int x, tnode *tree) if (tree == NULL ) // Если дерева нет, то формируем корень
tree = new tnode; //память под узел
tree->field = x; //поле данных
tree->left = NULL ;
tree->right = NULL ; //ветви инициализируем пустотой
>
else // иначе
if (x < tree->field) //Если элемент x меньше корневого, уходим влево
tree->left = addnode(x, tree->left); //Рекурсивно добавляем элемент
else //иначе уходим вправо
tree->right = addnode(x, tree->right); //Рекурсивно добавляем элемент
return (tree);
>
//Освобождение памяти дерева
void freemem(tnode *tree)
if (tree != NULL ) // если дерево не пустое
freemem(tree->left); // рекурсивно удаляем левую ветку
freemem(tree->right); // рекурсивно удаляем правую ветку
delete tree; // удаляем корень
>
>
// Тестирование работы
int main()
struct tnode *root = 0; // Объявляем структуру дерева
system( «chcp 1251» ); // переходим на русский язык в консоли
system( «cls» );
int a; // текущее значение узла
// В цикле вводим 8 узлов дерева
for ( int i = 0; i < 8; i++)
cout cin >> a;
root = addnode(a, root); // размещаем введенный узел на дереве
>
treeprint(root); // выводим элементы дерева, получаем отсортированный массив
freemem(root); // удаляем выделенную память
cin.get(); cin.get();
return 0;
>

Результат выполнения
Комментариев к записи: 3
Источник
Сортировка бинарным деревом
Сортировка бинарным деревом (Tree sort) – алгоритм сортировки, который заключается в построении двоичного дерева поиска по ключам массива, с последующим построением результирующего массива упорядоченных элементов путем обхода дерева.
Принцип работы алгоритма сортировки бинарным деревом
- Элементы неотсортированного массива данных добавляются в двоичное дерево поиска;
- Для получения отсортированного массива, производится обход бинарного дерева с переносом данных из дерева в результирующий массив.
Реализация алгоритма сортировки бинарным деревом
using System; using System.Collections.Generic; namespace TreeSortApp < //простая реализация бинарного дерева public class TreeNode < public TreeNode(int data) < Data = data; >//данные public int Data < get; set; > //левая ветка дерева public TreeNode Left < get; set; > //правая ветка дерева public TreeNode Right < get; set; > //рекурсивное добавление узла в дерево public void Insert(TreeNode node) < if (node.Data < Data) < if (Left == null) < Left = node; >else < Left.Insert(node); >> else < if (Right == null) < Right = node; >else < Right.Insert(node); >> > //преобразование дерева в отсортированный массив public int[] Transform(Listint> elements = null) < if (elements == null) < elements = new Listint>(); > if (Left != null) < Left.Transform(elements); >elements.Add(Data); if (Right != null) < Right.Transform(elements); >return elements.ToArray(); > > class Program < //метод для сортировки с помощью двоичного дерева private static int[] TreeSort(int[] array) < var treeNode = new TreeNode(array[0]); for (int i = 1; i < array.Length; i++) < treeNode.Insert(new TreeNode(array[i])); > return treeNode.Transform(); > static void Main(string[] args) < Console.Write("n hljs-keyword">var n = int.Parse(Console.ReadLine()); var a = new int[n]; var random = new Random(); for (int i = 0; i < a.Length; i++) < a[i] = random.Next(0, 100); > Console.WriteLine("Random Array: ", string.Join(" ", a)); Console.WriteLine("Sorted Array: ", string.Join(" ", TreeSort(a))); > > > Источник
Сортировка с помощью дерева (Heapsort)
Начнем с простого метода сортировки с помощью дерева, при использовании которого явно строится двоичное дерево сравнения ключей. Построение дерева начинается с листьев, которые содержат все элементы массива. Из каждой соседней пары выбирается наименьший элемент, и эти элементы образуют следующий (ближе к корню уровень дерева). Из каждой соседней пары выбирается наименьший элемент и т.д., пока не будет построен корень, содержащий наименьший элемент массива. Двоичное дерево сравнения для массива, используемого в наших примерах, показано на рисунке 1. Итак, мы уже имеем наименьшее значение элементов массива. Для того, чтобы получить следующий по величине элемент, спустимся от корня по пути, ведущему к листу с наименьшим значением. В этой листовой вершине проставляется фиктивный ключ с «бесконечно большим» значением, а во все промежуточные узлы, занимавшиеся наименьшим элементом, заносится наименьшее значение из узлов — непосредственных потомков (рис. 12.2). Процесс продолжается до тех пор, пока все узлы дерева не будут заполнены фиктивными ключами (рисунки 12.3 – 12.8).

Рис. 12.1.

Рис.12. 2. Второй шаг

Рис. 12.3. Третий шаг

Рис. 12.4. четвертый шаг

Рис.12.5. Пятый шаг

Рис.12.6. Шестой шаг

Рис. 12.7. Седьмой шаг

Рис. 12.8. Восьмой шаг
На каждом из n шагов, требуемых для сортировки массива, нужно log n (двоичный) сравнений. Следовательно, всего потребуется n?log n сравнений, но для представления дерева понадобится 2n — 1 дополнительных единиц памяти.
Имеется более совершенный алгоритм, который принято называть пирамидальной сортировкой (Heapsort). Его идея состоит в том, что вместо полного дерева сравнения исходный массив a[1], a[2], . a[n] преобразуется в пирамиду, обладающую тем свойством, что для каждого a[i] выполняются условия a[i]
Наиболее наглядно метод построения пирамиды выглядит при древовидном представлении массива, показанном на рисунке 12.9. Массив представляется в виде двоичного дерева, корень которого соответствует элементу массива a[1]. На втором ярусе находятся элементы a[2] и a[3]. На третьем — a[4], a[5], a[6], a[7] и т.д. Как видно, для массива с нечетным количеством элементов соответствующее дерево будет сбалансированным, а для массива с четным количеством элементов n элемент a[n] будет единственным (самым левым) листом «почти» сбалансированного дерева.
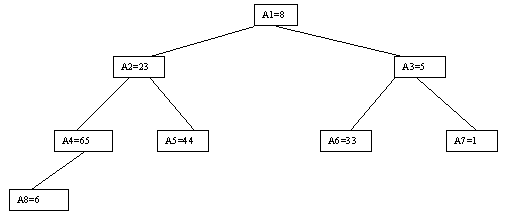
Рис.12.9.
Очевидно, что при построении пирамиды нас будут интересовать элементы a[n/2], a[n/2-1], . a[1] для массивов с четным числом элементов и элементы a[(n-1)/2], a[(n-1)/2-1], . a[1] для массивов с нечетным числом элементов (поскольку только для таких элементов существенны ограничения пирамиды). Пусть i — наибольший индекс из числа индексов элементов, для которых существенны ограничения пирамиды. Тогда берется элемент a[i] в построенном дереве и для него выполняется процедура просеивания, состоящая в том, что выбирается ветвь дерева, соответствующая min(a[2?i], a[2?i+1]), и значение a[i] меняется местами со значением соответствующего элемента. Если этот элемент не является листом дерева, для него выполняется аналогичная процедура и т.д. Такие действия выполняются последовательно для a[i], a[i-1], . a[1]. Легко видеть, что в результате мы получим древовидное представление пирамиды для исходного массива (последовательность шагов для используемого в наших примерах массива показана на рисунках 12.10-12.13).

Рис. 12.10.

Рис. 12.11.

Рис. 12.12.

Рис. 12.13.
В 1964 г. Флойд предложил метод построения пирамиды без явного построения дерева (хотя метод основан на тех же идеях). Построение пирамиды методом Флойда для нашего стандартного массива показано в таблице 12.7.
Таблица 12.7 Пример построения пирамиды
Начальное состояние массива
Источник