Sql запрос построение дерева
Запись: xintrea/mytetra_db_mcold/master/base/15071041258dki4lju9y/text.html на raw.githubusercontent.com
Рекурсивны SQL запросы являются одним из способов решения проблемы дерева и других проблем, требующих рекурсивную обработку. Они были добавлены в стандарт SQL 99. До этого они уже существовали в Oracle. Несмотря на то, что стандарт вышел так давно, реализации запоздали. Например, в MS SQL они появились только в 2005-ом сервере.
Рекурсивные запросы используют довольно редко, прежде всего, из-за их сложного и непонятного синтаксиса:
В MS SQL нет ключевого слова recursive, а в остальном все тоже самое. Такой синтаксис поддерживается в DB2, Sybase iAnywhere, MS SQL и во всех базах данных, которые поддерживают стандарт SQL 99.
Проще разобрать на примере. Предположим, есть таблица:
create table tree_sample (
id integer not null primary key ,
id_parent integer foreign key references tree_sample (id),
nm varchar (31) )
id – идентификатор
id_parent – ссылка на родитель
nm – название.
with recursive tree (nm, id, level , pathstr)
as ( select nm, id, 0, cast ( » as text)
from tree_sample
where id_parent is null
union all
select tree_sample.nm, tree_sample.id, t. level + 1, tree.pathstr + tree_sample.nm
from tree_sample
inner join tree on tree.id = tree_sample.id_parent)
select id, space ( level ) + nm as nm
from tree
order by pathstr
Этот пример выведет дерево по таблице с отступами. Первый запрос из tree_sample этот запрос выдаст все корни дерева. Второй запрос соединяет между собой таблицу tree_sample и tree, которая определяется этим же запросом. Этот запрос дополняет таблицу узлами дерева.
Сначала выполняется первый запрос. Потом к его результатам добавляются результаты второго запроса, где данные таблица tree – это результат первого запроса. Затем снова выполняется второй запрос, но данные таблицы tree – это уже результат предыдущего выполнения второго запроса. И так далее. На самом деле база данных работает не совсем так, но результат будет таким же, как результат работы описанного алгоритма.
После этого данные этой таблицы можно использовать в основном запросе как обычно.
Хочу заметить, что я не говорю о применимости конкретно этого примера, а лишь пишу его для демонстрации возможностей рекурсивных запросов. Этот запрос реально будет работать достаточно медленно из-за order by.
Источник
Древовидные структуры данных. Рекурсивные запросы
Достаточно часто приходится иметь дело с древовидными структурами данных. Классическим примером является структура подразделений организации, где один отдел является частью другого, и при этом также состоит из нескольких подразделений. Также можно в виде дерева описать отношения между сотрудниками — кто кому приходится начальником; некий список документов, где один документ появляется на основании другого, а тот в свою очередь был создан на основании третьего, и т.п.
Реализация древовидных структур в РСУБД
Для того, чтобы можно было листья дерева собрать воедино, нужно знать, как они соотносятся друг с другом. Как правило, все данные, которые нужно хранить в виде дерева, хранятся в одной таблице. Для того, чтобы по определенной строке определить ее родителя, в таблицу добавляется колонка, которая ссылается на родителя в этой же таблице. У корневого узла в дереве колонка с id родительского узла остается пустой:
Для разбора создадим таблицу, которая будет содержать список подразделений.
create table departments( id number primary key, dept_name varchar2(100), parent_id number, constraint departments_parent_id_fk foreign key(parent_id) references departments(id)); comment on table departments is 'Подразделения'; comment on column departments.parent_id is 'Ссылка на родительский узел'; insert into departments values(1, 'ЗАО ИнвестКорп', null); insert into departments values(2, 'Бухгалтерия', 1); insert into departments values(3, 'Отдел продаж', 1); insert into departments values(4, 'IT-отдел', 1); insert into departments values(5, 'Дирекция', 1); insert into departments values(6, 'Бухгалтерия по участку 1', 2); insert into departments values(7, 'Бухгалтерия по участку 2', 2); insert into departments values(8, 'Отдел QA', 4); insert into departments values(9, 'Отдел разработки', 4); Connect by
Oracle имеет свой собственный синтаксис для написания рекурсивных запросов. Сначала пример:
select d.* from departments d start with d.id = 1 connect by prior id = d.parent_id 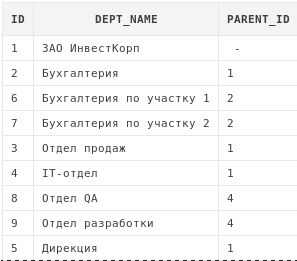
Данный запрос проходит по дереву вниз начиная с узла, имеющего id = 1 .
connect by задает правило, по которому дерево будет обходиться. В данном примере мы указываем, что у строк, которые должны будут выбираться на следующем шаге, значение столбца parent_id должно быть таким же, как значение столбца id на текущем.
В конструкции start with не обязательно указывать некие значения для id строк. Там можно указывать любое выражение. Те строки, для которых оно будет истинным, и будут являть собой стартовые узлы в выборке.
Псевдостолбец level
При использовании рекурсивных запросов, написанных с использованием connect by , становится доступен такой псевдостолбец, как level . Этот псевдостолбец возвращает 1 для корневых узлов в дереве, 2 для их дочерних узлов и т.д.
select dp.*, level from departments dp start with dp.parent_id is null connect by prior id = dp.parent_id 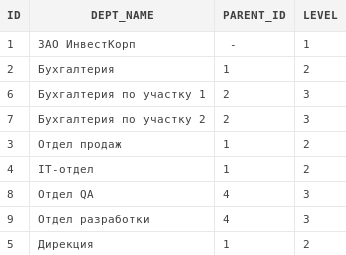
В приведенном выше примере мы начинаем строить наше дерево с корневых узлов, не зная их конкретных id . Но мы знаем, что у корневых узлов нет родителей, что и указали в конструкции start with — parent_id is null . В этом случае корневые узлы дерева, которое вернет запрос, будут совпадать с корневыми узлами дерева, которое хранится в БД.
Можно, например, используя level , вывести дерево в более красивом виде:
select lpad(dp.dept_name, length(dp.dept_name) + (level * 4) - 4, ' ') dept_name, level from departments dp start with dp.parent_id is null connect by prior id = dp.parent_id 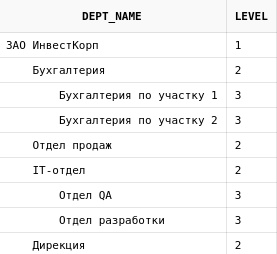
Здесь используется функция lpad , которая дополняет передаваемую строку(наименование подразделения) до определенной длины(длина наименования + уровень вложенности * 4) пробелами слева. Кстати, функция rpad работает так же, только дополняет символы справа.
Псевдостолбец CONNECT_BY_ISLEAF
Данный псевдостолбец вернет 1 в том случае, когда у узла в дереве больше нет потомков, и 0 в противном случае.
select dp.dept_name, CONNECT_BY_ISLEAF from departments dp start with dp.parent_id is null connect by prior id = dp.parent_id 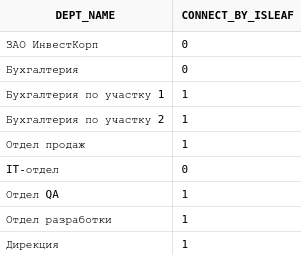
Сортировка в рекурсивных запросах
В запросах с использованием CONNECT BY нельзя использовать ORDER BY и GROUP BY , т.к. они нарушат древовидную структуру.
Это можно увидеть на примере:
select dp.dept_name, level from departments dp start with dp.parent_id is null connect by prior id = dp.parent_id order by dp.dept_name asc 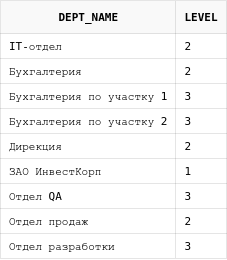
Как видно, корневой узел теперь шестой в выборке, а на первом месте подразделение, которое находится на втором уровне вложенности в дереве.
Для того, чтобы отсортировать данные, не нарушая их древовидной структуры, используется конструкция ORDER SIBLINGS BY . В этом случае сортировка будет применяться отдельно для каждой группы потомков в дереве:
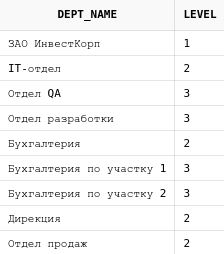
Теперь узлы, находящиеся на одном уровне, сортируются в алфавитном порядке, при этом структура дерева не нарушена.
Нарушение древовидной структуры при выборке
Предположим, что мы хотим получить структуру подразделений начиная с тех, чьи названия содержат в себе слово “отдел”:
select * from departments start with upper(dept_name) like upper('%Отдел%') connect by prior id = parent_id 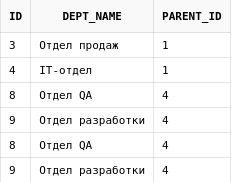
Некоторые строки дублируются, хотя в таблице имена подразделений не повторяются.
Теперь выполним тот же запрос, только добавим к списку колонок псевдостолбец level :
select id, dept_name, parent_id, level from departments start with upper(dept_name) like upper('%Отдел%') connect by prior id = parent_id 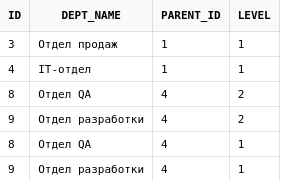
Теперь понятно, что строки дублируются из-за того, что они находятся на разных уровнях в дереве.
Разберем, почему так происходит, пройдя путь построения дерева:
- В качестве корней дерева добавляются узлы, которые удовлетворяют условию, находящемуся в START WITH . Это “Отдел продаж”, “IT-отдел”, “Отдел QA” и “Отдел разработки”. Все они находятся на первом уровне вложенности в дереве.
- Рекурсивно ищем потомков для всех выбранных на первом шаге узлов. Из всех них вложенность есть только у отдела IT — и внутри него как раз находятся “Отдел QA” и “Отдел разработки”, поэтому они добавляются со вторым уровнем вложенности.
Следует различать фактическое дерево, которое хранится в таблице, и то, которое получается при выборке, так как они могут не совпадать. На практике такая необходимость почти не встречается, и если при выборке данные не отражают той структуры, которая хранится в БД, то скорее всего запрос написан с ошибкой.
Источник