- Study & Dev О программировании и не только
- Структуры данных и алгоритмы. Теория. Деревья. Основные алгоритмы над деревьями
- Способы представления деревьев: Представление дерева с помощью массива
- Представление дерева с помощью ссылок
- Алгоритмы формирования деревьев
- Замечания к приведенным алгоритмам
- Деревья
- Зачем нужны деревья
- Части дерева
- Другие понятия
- Виды деревьев
- Обход дерева
- Где используются
Study & Dev О программировании и не только
Структуры данных и алгоритмы. Теория. Деревья. Основные алгоритмы над деревьями
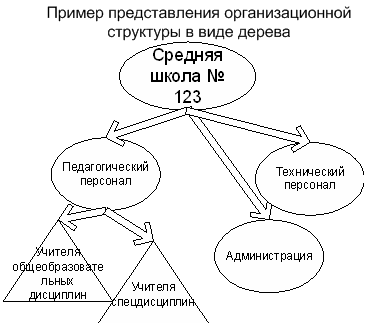
Дерево – это АТД (абстрактный тип данных) для хранения информационных элементов имеющих нелинейные отношения. За исключением элемента, который находится во главе дерева, каждый элемент имеет родителя, а также ноль или более дочерних элементов. Также говорят что дерево – это множество элементов, среди которых есть один выделенный который называется корнем, а остальные содержатся в N непересекающихся подмножествах, которые называются поддеревьями. Очевидно что дерево относится к классу динамических структур данных наряду с нам уже знакомыми стеком, очередями. С помощью дерева можно представить, например, следующую организационную структуру:
Наиболее известным классическим примером деревьев является генеалогическое дерево.
Также в качестве примера можно привести принятую в большинстве файловых систем организацию с помощью иерархически вложенных директорий и файлов. Наиболее ярко это проявляется в О.С. linux и unix, где файловую систему представляют в виде единого дерева, которое начинается с корневой директории обозначаемой “/”.
При дальнейшем обсуждении деревьев следует условиться о терминологии. Корень дерева (root) – первый его элемент (в приведенном выше изображении это “Средняя школа # 123”). Каждый элемент данных называют узлом (node), иногда листом (leaf). Фрагмент дерева называется поддеревом (subtree) или ветвью. Узел, не имеющий отходящих от него ветвей ли поддеревьев, называются терминальным или конечным узлом (terminal node). Высота дерева (height) – определяется количеством уровней, на которых располагаются его узлы. При работе с деревьями полезно изображать их на бумаге, однако при этом всегда следует помнить, что деревья – это метод логической организации информации в памяти компьютера, не физической.
Следует помнить, что большинство операций, которые выполняются над деревьями, являются рекурсивными, т.к. деревья имеют рекурсивную структуру – каждое дерево содержит множество поддеревьев.
О деревьях можно судить как об упорядоченных или не упорядоченных. Мы говорим, что дерево упорядочено, если каждому из элементов можно сопоставить порядковый номер: 1,2,3. На рисунках упорядоченные “братья-узлы” представляются слева направо.
Пример упорядоченного дерева: книга. Книга имеет древовидную структуру с делением на разделы, каждый из которых состоит из множества тем, а тема включает отдельные вопросы. Каждый из вопросов также можно разделить на элементарные части – абзацы, картинки, таблицы. Очевидно, что эти элементы имеют четкий порядок следования, нарушение которого приводит к потере смысла книги.
В информатике наиболее часто используются именно двоичные деревья — это деревья, каждый узел которого содержит не более чем два подчиненных ему (дочерних элемента). Бинарное дерево считается правильным, если каждый узел не содержит одного или содержит два дочерних элемента. Таким образом – генеалогическое дерево – это правильно двоичное дерево. В бинарных деревьях дочерние узлы именуют “правый” и “левый”.
С помощью двоичного дерева можно легко представить арифметическое выражение с использованием бинарных операций.
Например, для выражения: (2*3)/(1+1)-(3*7) можно построить следующее дерево:
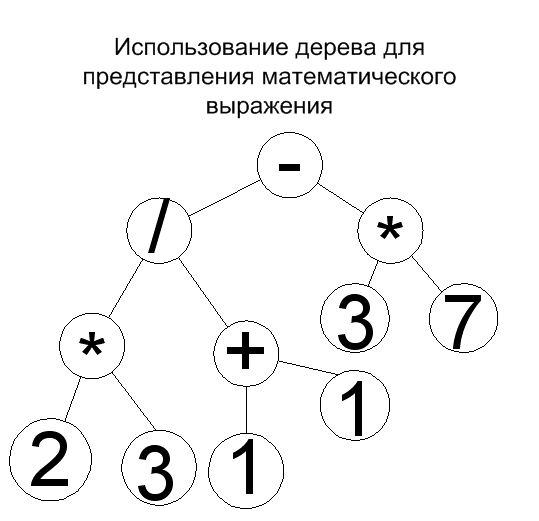
Для каждого узла дерева можно определить понятие глубины. Допустим, V – узел дерева. Глубина узла выражается количество предков V, за исключением самого V. По определению глубина корня равна нулю.
- если узел –корень, то его глубина ноль;
- в противном случае глубина узла V равна 1 + глубина его родителя V`.
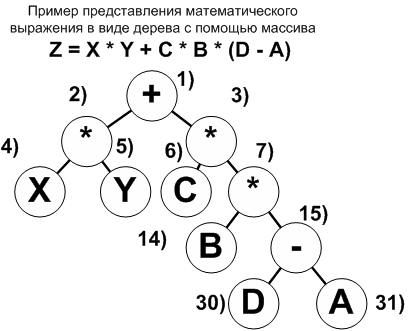
Способы представления деревьев: Представление дерева с помощью массива
- P(V) = 2*N — в случае если узел V находится слева от своего родительского узла V*.
- P(V)= 2*N + 1 – а эта формула применима в той ситуации, когда узел V находится правее чем родительский.
Очень важно, что если дерево не полное, то отсутствующим элементам назначаются номера и для них выделяется место в массиве, просто в ячейке с номером “8, 9, 13, 29” и других (согласно приведенному изображению дерева математического выражения) ничего не хранится.
Представление дерева с помощью ссылок
В случае множественного дерева (каждый узел может иметь произвольное количество потомков) возможно, воспользоваться подобным объявлением:
В данном примере DATA_TYPE – тип данных соответствующий хранимому в дереве, например, если у нас дерево математического выражения, то это может быть число или знак арифметической операции. Если дерево служит для хранения генеалогической информации – то в качестве типа каждого узла может быть строка с именем человека, или даже произвольная структура или класс CHuman, описывающий кого-то из предков. Обратите внимание на другое, в структуре присутствует ссылка на узел дерева который является родительским, в общем случае это не требуется, однако при решении многих задач поиска и модификации дерева позволяет их упростить, благодаря подобной ссылке мы можем перемещаться по дереву не только в направлении от корня к нижележащим элементам, но и в обратном порядке.
Под LIST_OF_NODES подразумевается некий контейнер способный хранить внутри себя достаточное количество ссылок на поддеревья. В случае если количество не велико и относительно стабильно, то можно воспользоваться обычным массивом. В случае, когда количество элементом может варьироваться в произвольном диапазоне, то рекомендуется применять один из ранее изученных контейнеров: очередь, дек. Если вы используете средства STL, то можно объявить ссылку на множество поддеревьев так:
Vector MultiNode *> children; Алгоритмы формирования деревьев
До текущего момента все рассмотренные алгоритмы предполагали, что у нас есть построенное двоичное или мульти-дерево. Теперь мы рассмотрим схему формирования деревьев с упором именно на практические направления. Одним из важнейших направлений использования бинарных деревьев является оптимизация задач поиска. Когда мы рассматривали тему поиска, то из двух способов – линейных поиск (затраты порядка O(n)) и двоичного поиска (затраты порядка O(log n)) очевидным было применение именно второго подхода. Однако в этом случае нам было необходимо выполнить сортировку массива данных в противном случае алгоритм не работал. В случае использования двоичных деревьев можно создать такой алгоритм его формирования, что задача поиска в нем нужного элемента также будет составлять порядка O(log n).
Пример: предположим, что нашей программе на вход подается поток чисел (в общем случае не упорядоченный), если мы опишем узел дерева как
И потребуем чтобы все узлы, находящиеся в правом поддереве были больше чем корневой элемент, а все узлы из левого поддерева были не более чем корневой элемент, то в таком случае для последовательности чисел: 6 1 3 7 2 9 4 5 2 будет построено следующее дерево:
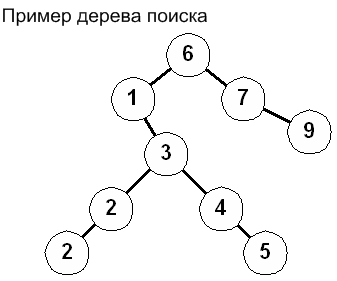
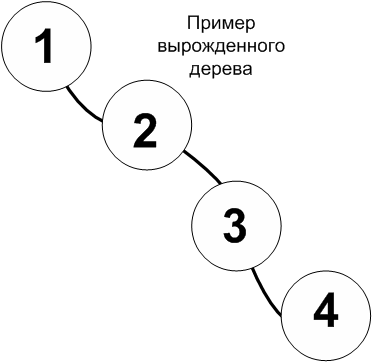
Деревья, для которых выполняется вышеописанное соотношение, называются деревьями поиска. В таком дереве, для того чтобы найти нужный элемент на каждом шаге пути необходимо принимать решение о выборе направления в зависимости от того, как соотносятся искомый элемент X и значение текущего узла Vi. Если Vi >= X то в таком случае поиск должен идти именно в левом поддереве, в противном случае в правом. Следует отметить, что получившееся двоичное дерево и соответственно эффективность операций поиска сильно зависит от степени упорядоченности поступающих наборов чисел. В случае если эти значения уже отсортированы, например: 1, 2, 3, 4 то получающееся дерево вырождается и начинает напоминать обычный линейный список.
В идеальном случае дерево должно быть сбалансированным. Напомню, что сбалансированным деревом является то, где количество узлов в правом и левом поддеревьях отличаются не более чем на 1. для повышения скорости работы алгоритма поиска в бинарном дереве также используют прием буфера (барьера). В этом случае все ветви будут заканчиваться не ссылкой на NULL, а ссылкой на этот буферный элемент. То, что у нас получилось можно увидеть на картинке:
BinNode * find (int data, BinNode * cur){
BinNode * find (int data, BinNode * cur){
Замечания к приведенным алгоритмам
В примере 2 предполагается наличие глобальной переменной GlobalBuffer, которая и является ссылкой на вспомогательный (фиктивный) барьерный элемент. Отметьте, что значение информационной компоненты data для этого буферного элемента перед началом цикла устанавливается в data, что позволяет упростить поиск за счет уменьшения количества операций сравнения. Часто начинающие программисты пытаются реализовать подобный поиск с помощью рекурсии, аргументируя, что раз структура данных рекурсивна то и поиск тоже должен быть таковым. Напоминаю, что настоятельно рекомендуется избегать применения рекурсии везде где это возможно из-за непроизводительных затрат на вызов функции.
Очевидно, что деревья будут вряд ли применяться в задачах, структуры данных которых сформированы и не изменяются на протяжении работы программы. Также очевидно, что на практике деревья должны будут расти и уменьшаться. Рассмотрим пример использования дерева для решения задачи частотного анализа.
Пример: предположим, что есть файл, содержащий некоторый объем текста. Для каждого из слов (как вариант, буквы) содержащегося в файле необходимо выполнить подсчет частоты его встречи. Простейшее решение, которое приходит в голову, это воспользоваться структурой данных типа ХЕШ (ассоциативный массив) в этом случае в качестве ключа будет использоваться само слово, в качестве его значения будет количество повторений. Разумеется, что хеш будет легко эмулировать с помощью двух массивов. В случае если файл содержит достаточно большое количество разных слов, то узким местом данного алгоритма будет поиск позиции, в которой встречается нужное слово. В случае если слова поступают в не отсортированном виде, что вполне ожидаемо, то мы должны будем просматривать в среднем половину от заполненного массива слов пока не найдем искомый. Можно воспользоваться, например, алгоритмом сортировки (здесь наиболее естественно применять метод вставки), мы же рассмотрим применение поискового дерева. Слова в нем будут располагаться в алфавитном порядке, т.е. все слова левого поддерева должны находиться в словаре раньше, чем корневой элемент, соответственно все слова правого поддерева должны находиться в словаре позже, чем корневой элемент (не забывайте, что такое соотношение должно выполняться для всех поддеревьев). Каждый раз, когда на вход программе будет поступать очередное слово будет выполняться поиск его схема идентична той, которая была приведена в таблице выше, если операция поиска была неудачна (функция из примера 1 вернула NULL, а функция из примера 2 вернула ссылку на сам буферный элемент), то необходимо в соответствующую позицию вставить новое слово, и его счетчик количества повторений инициализировать 1. После завершения формирования дерева его можно распечатать. Фрагмент кода решающего данную задачу приводится ниже.
int count; // количество повторений слова
Источник
Деревья
Дерево — это нелинейная иерархическая структура данных. Она состоит из узлов и ребер, которые соединяют узлы.

Зачем нужны деревья
Другие структуры данных, например, массивы, списки, стеки и очереди, линейные. Это значит, что данные в них хранятся последовательно. Когда мы выполняем любую операцию в линейной структуре данных, временная сложность растет с увеличением размера данных. В современном мире это не очень круто.
Разные древовидные структуры позволяют быстрее и легче получать доступ к данным, поскольку дерево — структура нелинейная.
Части дерева
- Узел — это объект, в котором есть ключ или значение и указатели на дочерние узлы.
Узлы, у которых нет дочерних узлов, называют листами или терминальными узлами.
Узлы, у которых есть хотя бы один дочерний узел, называются внутренними. - Ребро связывает два узла.
- Корень — это самый верхний узел дерева. Его ещё иногда называют корневым узлом.
.png)
Другие понятия
- Высота узла — это максимальная длина пути от этого узла к самому нижнему узлу (листу).
- Глубина вложенности узла — длина пути от корня до этого узла.
- Высота дерева — это высота корневого узла или глубина самого глубокого узла.
- Степень узла — это общее количество ребер, которые соединены с этим узлом.

- Лес — множество непересекающихся деревьев. Например, если «срезать» корень, получится лес.

Виды деревьев
Обход дерева
Чтобы выполнить какую-либо операцию с деревом, нужно добраться до определенного узла. Для этого и существуют алгоритмы обхода дерева. Они помогают «дойти» до необходимого узла.
Где используются
- Деревья двоичного поиска помогают быстро проверить наличие элемента в наборе.
- Куча — это тоже своеобразное дерево. Кучи используют в алгоритме сортировки кучей.
- Префиксные деревья используются в маршрутизаторах, они хранят информацию о маршруте.
- Большинство популярных баз данных основаны на B-деревья и T-деревья.
- Компиляторы используют абстрактное синтаксическое дерево, чтобы находить синтаксические ошибки в ваших программах.
СodeСhick.io — простой и эффективный способ изучения программирования.
2023 © ООО «Алгоритмы и практика»
Источник