36.Назначение и особенности построения таблиц идентификаторов
Проверка правильности семантики и генерация кода требуют знания характеристик переменных, констант, функций и других элементов, встречающихся в программе на исходном языке. Все эти элементы в исходной программе, как правило, обозначаются идентификаторами. Выделение идентификаторов и других элементов исходной программы происходит на фазе лексического
анализа. Их характеристики определяются на фазах синтаксического разбора, семантического анализа и подготовки к генерации кода. Состав возможных характеристик и методы их определения зависят от семантики входного языка.
В любом случае компилятор должен иметь возможность хранить все найденные идентификаторы и связанные с ними характеристики в течение всего процесса компиляции, чтобы иметь возможность использовать их на различных фазах компиляции. Для этой цели, как было сказано выше, в компиляторах используются специальные хранилища данных, называемые таблицами символов
или таблицами идентификаторов.
Любая таблица идентификаторов состоит из набора полей, количество которых равно числу различных идентификаторов, найденных в исходной программе. Каждое поле содержит в себе полную информацию о данном элементе таблицы. Компилятор может работать с одной или несколькими таблицам идентификаторов, в зависимости от реализации компилятора. Например, можно организовывать различные таблицы идентификаторов для различных модулей исходной программы или для различных типов элементов входного языка.
Состав информации, хранимой в таблице идентификаторов для каждого элемента исходной программы, зависит от семантики входного языка и типа элемента. Например, в таблицах идентификаторов может храниться следующая информация:
1. Для переменных: имя, тип данных, область памяти;
2. Для констант: название (если имеется), значение, тип данных;
3. Для функций: имя, количество и типы формальных аргументов, тип возвращаемого результата, адрес кода функции.
Не вся информация, хранимая в таблице идентификаторов, может заполняться компилятором сразу – он может несколько раз выполнять обращение к данным в таблице идентификаторов на различных фазах компиляции. Например, имена переменных могут быть выделены на фазе лексического анализа, типы данных для переменных – на фазе синтаксического разбора, а область памяти связывается с переменной только на фазе подготовки к генерации кода.
Вне зависимости от реализации компилятора принцип его работы с таблицей идентификаторов остается одним и тем же – на различных фазах компиляции компилятор вынужден многократно обращаться к таблице для поиска информации и записи новых данных. Как правило, каждый элемент в исходной программе однозначно идентифицируется своим именем. Поэтому компилятору приходится часто выполнять поиск необходимого элемента в таблице идентификаторов по его имени, в то время как процесс заполнения таблицы выполняется нечасто – новые идентификаторы описываются в программе гораздо реже, чем используются. Отсюда можно сделать вывод, что таблицы идентификаторов должны быть организованы таким образом, чтобы компилятор имел возможность максимально быстрого поиска нужного ему элемента.
37. Построение таблиц идентификаторов с помощью бинарного дерева и хэширования
- Для решения проблемы коллизии можно использовать много способов. Одним из них является метод рехеширования(или расстановка). Согласно этому методу, если для элементаAадресh(A), вычисленный с помощью хеш-функцииh, указывает на уже занятую ячейку, то необходимо вычислить значение функцииn1=h1(A) и проверить занятость ячейки по адресуn1. Если и она занята, то вычисляется значениеh2(A) и так до тех пор, пока либо не будет найдена свободная ячейка, либо очередное значениеhi(A) совпадет сh(A). В последнем случае считается, что таблица идентификаторов заполнена, и места в ней больше нет — выдается информация об ошибке размещения идентификатора в таблице.
- Такую таблицу идентификаторов можно организовать по следующему алгоритму размещения элемента:
- Шаг 1:Вычислить значение хеш-функцииn=h(A) для нового элементаA.
- Шаг 2:Если ячейка по адресуnпустая, то поместить в нее элементAи завершить алгоритм, иначеi:=1 и перейти к шагу 3.
- Шаг 3:Вычислитьni=hi(A). Если ячейка по адресуniпустая, то поместить в нее элементAи завершить алгоритм, иначе перейти к шагу 4.
- Шаг 4:Еслиn=ni, то сообщить об ошибке и завершить алгоритм, иначеi:=i+1 и вернуться к шагу 3.
- Тогда поиск элемента Aв таблице идентификаторов, организованной таким образом, будет выполняться по следующему алгоритму:
- Шаг 1:Вычислить значение хеш-функцииn=h(A) для искомого элементаA.
- Шаг 2:Если ячейка по адресуnпустая, то элемент не найден, алгоритм завершен, иначе сравнить имя элемента в ячейкеnс именем искомого элементаA. Если они совпадают, то элемент найден и алгоритм завершен, иначеi:=1 и перейти к шагу 3.
- Шаг 3:Вычислитьni=hi(A). Если ячейка по адресуniпустая илиn=ni, то элемент не найден и алгоритм завершен, иначе сравнить имя элемента в ячейкеniс именем искомого элементаA. Если они совпадают, то элемент найден и алгоритм завершен, иначеi:=i+1 и повторить шаг 3.
- Алгоритмы размещения и поиска элемента схожи по выполняемым операциям. Поэтому они будут иметь одинаковые оценки времени, необходимого для их выполнения.
- При такой организации таблиц идентификаторов в случае возникновения коллизии алгоритм размещает элементы в пустых ячейках таблицы, выбирая их определенным образом. При этом элементы могут попадать в ячейки с адресами, которые потом будут совпадать со значениями хеш-функции, что приведет к возникновению новых, дополнительных коллизий. Таким образом, количество операций, необходимых для поиска или размещения в таблице элемента, зависит от заполненности таблицы.
- Для организации таблицы идентификаторов по методу рехеширования необходимо определить все хеш-функции hiдля всехi. Чаще всего функцииhiопределяют как некоторую модификации хеш-функцииh. Например, самым простым методом вычисления функции hi(A) является ее организация в виде hi(A) = (h(A) + pi) mod Nm, где pi — некоторое вычисляемое целое число, аNm— максимальное значение из области значений хеш-функцииh. В свою очередь, самым простым подходом здесь будет положитьpi=i. Тогда получаем формулуhi(A) = (h(A)+i)modNm. В этом случае при совпадении значений хеш-функции для каких-либо элементов поиск свободной ячейки в таблице начинается последовательно от текущей позиции, заданной хеш-функциейh(A).
- Этот способ нельзя признать особенно удачным — при совпадении хеш-адресов элементы в таблице начинают группироваться вокруг них, что увеличивает число необходимых сравнений при поиске и размещении. Но даже такой примитивный метод рехеширования является достаточно эффективным средством организации таблиц идентификаторов при неполном заполнении таблицы.
- Создать новую вершину, поместить в нее информацию об очередном идентификаторе, сделать эту новую вершину правой вершиной текущего узла и вернуться к шагу 1.
- проверка соблюдение во входной программе соблюдения семантических соглашений входного языка
- дополнение внутреннего представления программного оператора и действиями неявно предусмотренными семантикой входного языка.
- Проверка семантических норм программы на прямую не связанных с входным языком.
- Выполняет программы до достижения точки остановки
- Выполняет программы до поступления некоторых заданных условий
- Просмотр содержания областей памяти
- Группы системных программ1-2
- Понятие операционной среды2
- Понятие вычислительного процесса и ресурса3
- Диаграмма состояний процесса4
- Реализация понятия последовательного процесса в ОС5
- Процессы и потоки6
- Обработка прерываний7-8
- Дисциплины обслуживания прерываний9
- Обработка прерываний при участии супервизора ОС9
- Основные виды ресурсов10-11
- Классификация ОС12
- Функции ОС по управлению задачами13-14
- Планировщики, стратегии планирования15
- Дисциплины диспетчеризации FCFS, SJN, SRT16-17
- Дисциплина диспетчеризации RR, приоритеты, многоуровневая очередь18
- Вытесняющие и не вытесняющие алгоритмы диспетчеризации19
- Качество диспетчеризации, гарантии обслуживания20-21
- Диспетчеризация задач с использованием динамических приоритетов21
- Память и отображения, виртуальное адресное пространство22
- Простое непрерывное распределение, оверлейные структуры23-24
- Разделы с фиксированными границами25
- Разделы с подвижными границами26
- Сегментная организация виртуальной памяти27
- Страничная организация виртуальной памяти28-29
- Сегментно-страничная организация виртуальной памяти30
- Основные понятия и концепции организации ввода/вывода в ОС31-32
- Режимы управления вводом/выводом33
- Закрепление устройств, общие устройства ввода/вывода34
- Синхронный и асинхронный ввод/вывод35
- Кэширование операций ввода/вывода при работе с HDD36-37
- Стратегии обработки запросов к жесткому диску38
- Функции файловой системы ОС и иерархия данных39-40
- Транслятор, компилятор, интерпретатор.41-42
- Общая схема работы транслятора43
- Понятие прохода, особенности ассемблеров44
- Простейшие способы построения таблиц идентификаторов.45
- Построение таблиц идентификаторов с помощью бинарного дерева и хэширования 46-47
- Функции и принципы построения лексических и синтаксических анализаторов 48
- Функции и принципы построения синтаксических и семантических анализаторов 49
- Генерация и оптимизация кода 49
- Формы внутреннего представления программы50
- Структура системы программирования51
- Текстовый редактор и компилятор в системе программирования52
- Функции компоновщика и отладчика52
Источник
1.3 Метод простого рехэширования
Для организации таблицы идентификаторов по методу рехэширования необходимо определить все хэш-функции 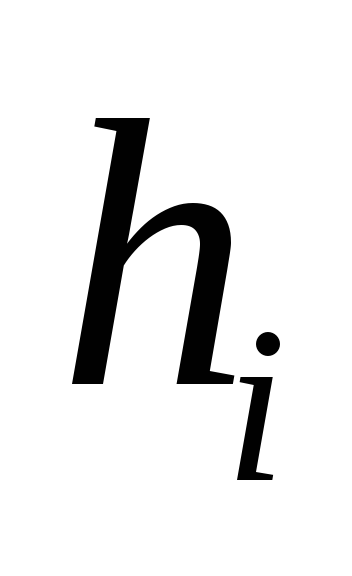 для всех
для всех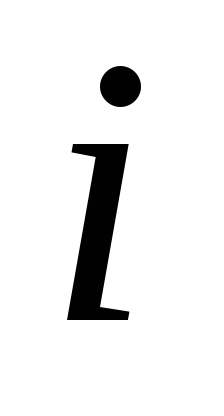 Чаще всего функции
Чаще всего функции определяют как некоторую модификацию хэш-функцииh. Например, самым простым методом вычисления функции
определяют как некоторую модификацию хэш-функцииh. Например, самым простым методом вычисления функции является ее организация в виде
является ее организация в виде
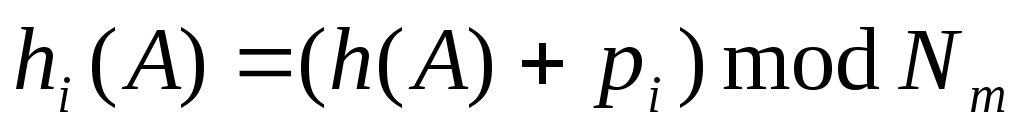
(1)
где 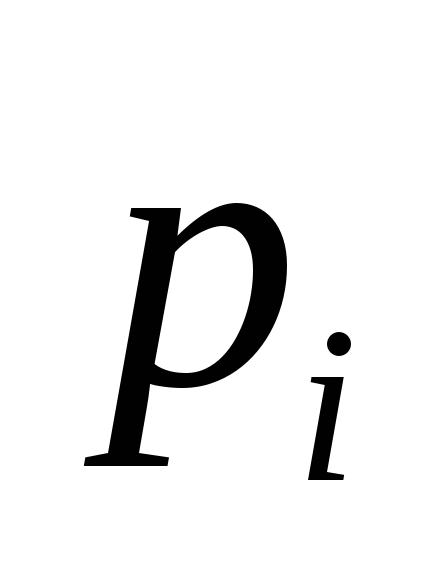 — некоторое вычисляемое целое число, а
— некоторое вычисляемое целое число, а — максимальное значение из области значений хэш-функцииh. В данной работе положим
— максимальное значение из области значений хэш-функцииh. В данной работе положим . Тогда получаем формулу
. Тогда получаем формулу
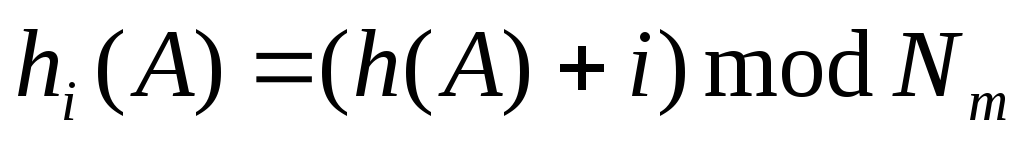
(2)
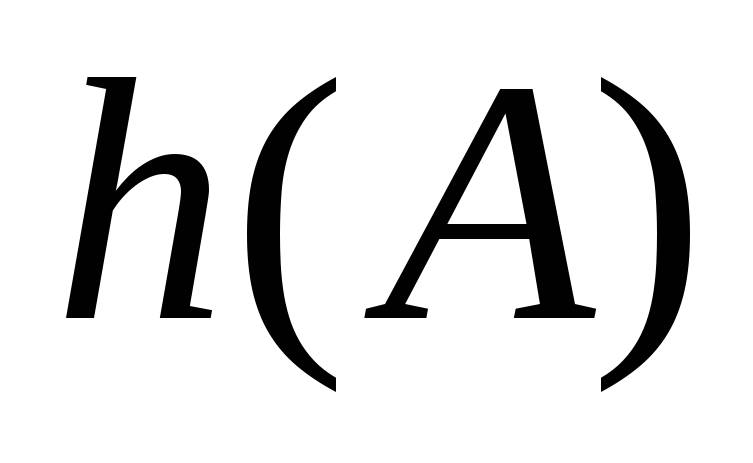
В этом случае при совпадении значений хэш-функции для каких-либо элементов поиск свободной ячейки в таблице начинается последовательно от текущей позиции, заданной хэш-функцией .
Блок-схема метода простого рехэширования представлена на рисунке 1.1.
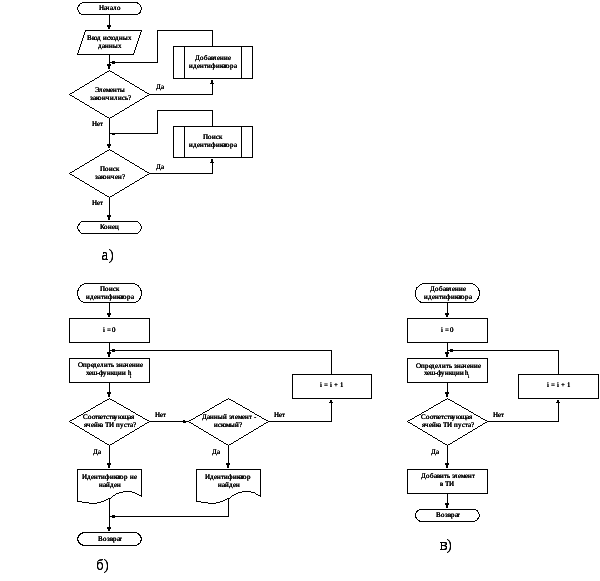
Рис. 1.1 – Блок-схема метода простого рехэширования; а) – Блок-схема алгоритма простого рехэширования;б) – Блок-схема функции поиска идентификатора;
в) – Блок-схема функции добавления идентификатора
1.4 Метод бинарного дерева
Метод построения таблиц, при котором таблица имеет форму бинарного дерева. Каждый узел дерева представляет собой элемент таблицы, причем корневой узел является первым элементом. При построении дерева элементы сравниваются между собой, и в зависимости от результатов, выбирается путь в дереве. Предположим, что надо записать новый идентификатор. Для него выбирается левое поддерево, если этот идентификатор меньше текущего, если же идентификатор больше, выбирается правое поддерево. В случае если текущий узел не является концевым, переходим в следующий узел (согласно выбранному направлению) и опять сравниваем добавляемый идентификатор с текущим.
Для данного метода число требуемых сравнений и форма получившегося дерева во многом зависят от того порядка, в котором поступают идентификаторы.
Блок-схема метода бинарного дерева представлена на рисунке 1.2

Рис. 1. 1 – Блок-схема метода бинарного дерева; а) – Блок-схема алгоритма метода бинарного дерева;б) – Блок-схема функции добавления идентификатора;
в) – Блок-схема функции поиска идентификатора
1.5 Результат выполнения программы
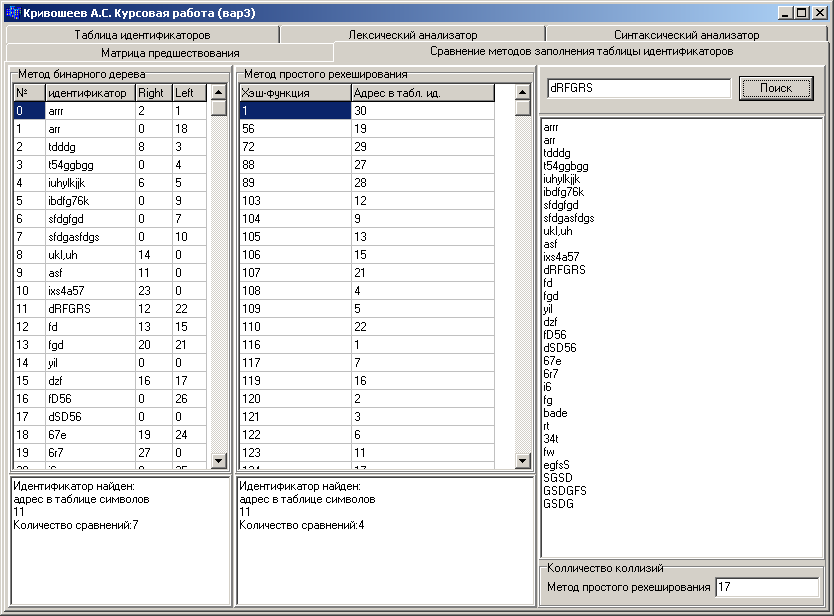
Рис. 1.3 – Результаты сравнения методов организации таблицы идентификаторов
Для сравнения методов организации таблицы идентификаторов был разработан модуль, иллюстрирующий их работу.
Было выявлено, что для метода рехэширования для поиска идентификатора используется меньшее количество сравнений, чем для метода бинарного дерева.
В дальнейшем для заполнения таблицы идентификаторов исходной программы будем использовать метод бинарного дерева, т.к метод простого рехэширования требует больше памяти, и общее кол-во переменных зависит от длинны хэш-таблицы.
2 Проектирование лексического анализатора
2.1 Исходные данные
Текст на входном языке задается в виде символьного (текстового) файла. Программа должна выдает сообщения о наличие во входном тексте ошибок, которые могут быть обнаружены на этапе лексического анализа.
Предусмотрены следующие варианты операторов входной программы:
условный оператор вида if then
составной оператор вида begin. end;
оператор цикла whiledo ;
операции сложения (+), вычитания (-), инкремент (++);
операции сравнения «меньше» (<), «больше» (>), «равно» (=);
логические операции and, or, not;
операндами в выражениях могут выступать идентификаторы и константы;
все идентификаторы должны восприниматься как переменные.
Источник