- Дерево как структура данных
- Основные термины
- Обход древа
- Бинарные (двоичные) деревья
- Что значит древо в контексте программирования?
- Модели представления данных в БД
- Преимущества
- Недостатки
- Сетевая модель
- Преимущества
- Недостатки
- Объектно-ориентированная модель
- Преимущества
- Недостатки
- Реляционная модель
- Преимущества
Дерево как структура данных
Какую выгоду можно извлечь из такой структуры данных, как дерево? В этой статье мы расскажем о данных в виде дерева, рассмотрим основные определения, которые следует знать, а также узнаем, как и зачем используется дерево в программировании. Спойлер: бинарные деревья часто применяют для поиска информации в базах данных, для сортировки данных, для проведения вычислений, для кодирования и в других случаях. Но давайте обо всем по порядку.
Основные термины
Дерево — это, по сути, один из частных случаев графа. Древовидная модель может быть весьма эффективна в случае представления динамических данных, особенно тогда, когда у разработчика стоит цель быстрого поиска информации, в тех же базах данных, к примеру. Еще древом называют структуру данных, которая представляет собой совокупность элементов, а также отношений между этими элементами, что вместе образует иерархическую древовидную структуру.
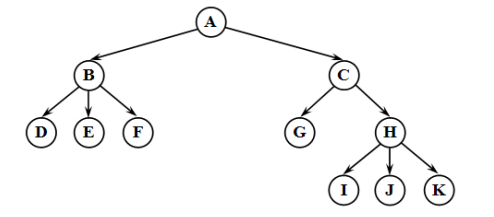
Каждый элемент — это вершина или узел дерева. Узлы, соединенные направленными дугами, называются ветвями. Начальный узел — это корень дерева (корневой узел). Листья — это узлы, в которые входит 1 ветвь, причем не выходит ни одной.
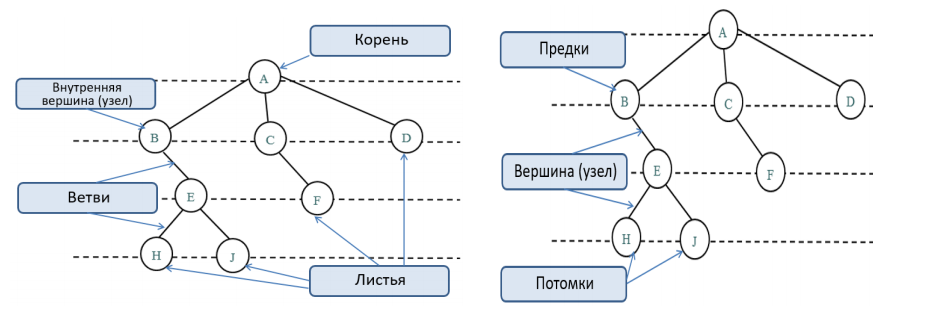
Общую терминологию можно посмотреть на левой и правой части картинки ниже:
Какие свойства есть у каждого древа:
— существует узел, в который не входит ни одна ветвь;
— в каждый узел, кроме корневого узла, входит 1 ветвь.
На практике деревья нередко применяют, изображая различные иерархии. Очень популярны, к примеру, генеалогические древа — они хорошо известны. Все узлы с ветвями, исходящими из единой общей вершины, являются потомками, а сама вершина называется предком (родительским узлом). Корневой узел не имеет предков, а листья не имеют потомков.
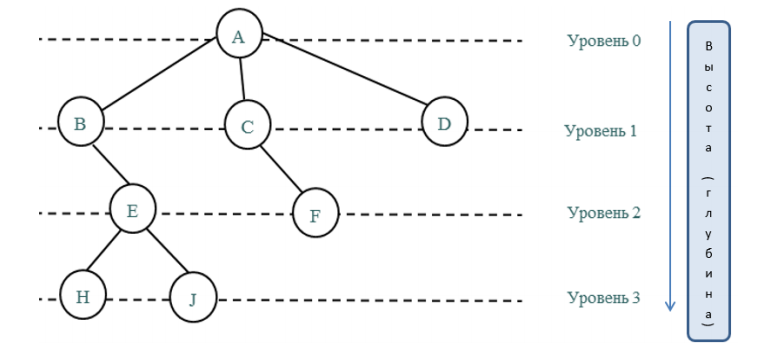
Также у дерева есть высота (глубина). Она определяется числом уровней, на которых располагаются узлы дерева. Глубина пустого древа равняется нулю, а если речь идет о дереве из одного корня, тогда единице. В данном случае на нулевом уровне может быть лишь одна вершина – корень, на 1-м – потомки корня, на 2-м – потомки потомков корня и т. д.
Ниже изображен графический вывод древа с 4-мя уровнями (дерево имеет глубину, равную четырем):
Следующий термин, который стоит рассмотреть, — это поддерево. Поддеревом называют часть древообразной структуры, которую можно представить в виде отдельного дерева.
Идем дальше. Древо может быть упорядоченным — в данном случае ветви, которые исходят из каждого узла, упорядочены по некоторому критерию.
Степень вершины в древе — это число ветвей (дуг), выходящих из этой вершины. Степень равняется максимальной степени вершины, которая входит в дерево. В этом случае листьями будут узлы, имеющие нулевую степень. По величине степени деревья бывают:
— двоичные (степень не больше двух);
— сильноветвящиеся (степень больше двух).
Деревья — это рекурсивные структуры, ведь каждое поддерево тоже является деревом. Каждый элемент такой рекурсивной структуры является или пустой структурой, или компонентом, с которым связано конечное количество поддеревьев.
Когда мы говорим о рекурсивных структурах, то действия с ними удобнее описывать посредством рекурсивных алгоритмов.
Обход древа
Чтобы выполнить конкретную операцию над всеми вершинами, надо все эти узлы просмотреть. Данную задачу называют обходом дерева. То есть обход представляет собой упорядоченную последовательность узлов, в которой каждый узел встречается лишь один раз.
В процессе обхода все узлы должны посещаться в некотором, заранее определенном порядке. Есть ряд способов обхода, вот три основные:
— прямой (префиксный, preorder);
— симметричный (инфиксный, inorder);
— обратный (постфиксный, postorder).
Существует много древовидных структур данных: двоичные (бинарные), красно-черные, В-деревья, матричные, смешанные и пр. Поговорим о бинарных.
Бинарные (двоичные) деревья
Бинарные имеют степень не более двух. То есть двоичным древом можно назвать динамическую структуру данных, где каждый узел имеет не большое 2-х потомков. В результате двоичное дерево состоит из элементов, где каждый из элементов содержит информационное поле, а также не больше 2-х ссылок на различные поддеревья. На каждый элемент древа есть только одна ссылка.
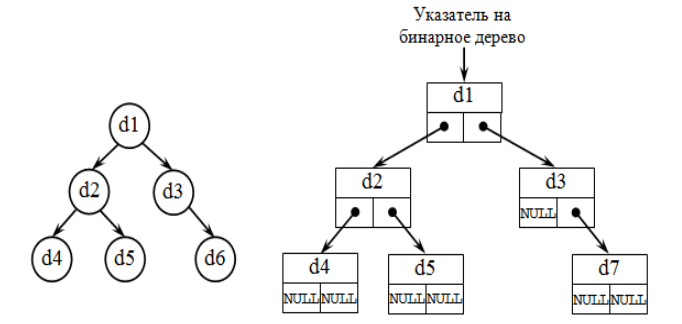
У бинарного древа каждый текущий узел — это структура, которая состоит из 4-х видов полей. Какие это поля:
— информационное (ключ вершины);
— служебное (включена вспомогательная информация, однако таких полей может быть несколько, а может и не быть вовсе);
— указатель на правое поддерево;
— указатель на левое поддерево.
Самый удобный вид бинарного древа — бинарное дерево поиска.
Что значит древо в контексте программирования?
Мы можем долго рассуждать о математическом определении древа, но это вряд ли поможет понять, какие именно выгоды можно извлечь из древовидной структуры данных. Тут важно отметить, что древо является способом организации данных в форме иерархической структуры.
В каких случаях древовидные структуры могут быть полезны при программировании:
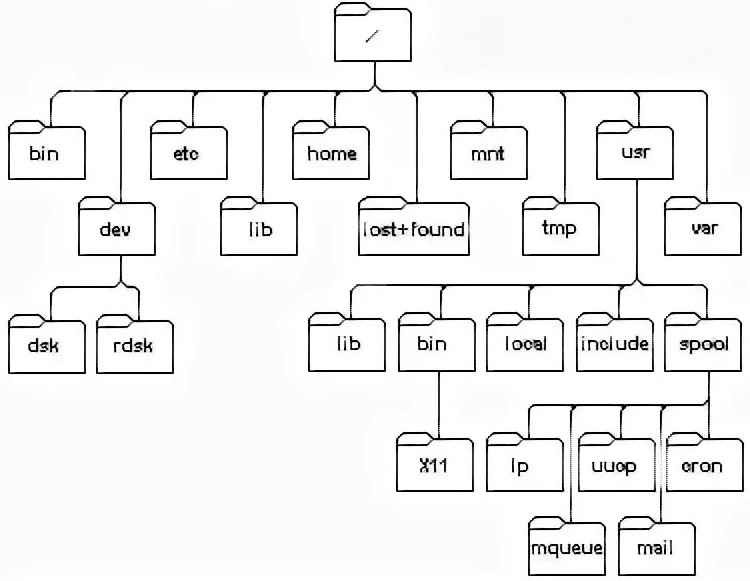
- Когда данная иерархия существует в предметной области разрабатываемой программы. К примеру, программа должна обрабатывать генеалогическое древо либо работать со структурой каталогов. В таких ситуациях иногда есть смысл сохранять между объектами программы существующие иерархические отношения. В качестве примера можно вывести древо каталогов операционной системы UNIX:
- Когда между объектами, которые обрабатывает программа, отношения иерархии не заданы явно, но их можно задать, что сделает обработку данных удобнее. Как тут не вспомнить разработку парсеров либо трансляторов, где весьма полезным может быть древо синтаксического разбора?
- А сейчас очевидная вещь: поиск объектов более эффективен, когда объекты упорядочены, будь то те же базы данных. К примеру, поиск значения в неструктурированном наборе из тысячи элементов потребует до тысячи операций, тогда как в упорядоченном наборе может хватить всего дюжины. Вывод прост: раз иерархия — эффективный способ упорядочивания объектов, почему же не использовать древовидную иерархию для ускорения поиска узлов со значениями? Так и происходит: если вспомнить бинарные деревья, то на практике их можно применять в следующих целях:
— поиск данных в базах данных (специально построенных деревьях);
— сортировка и вывод данных;
— вычисления арифметических выражений;
— кодирование по методу Хаффмана и пр.
Источник
Модели представления данных в БД

В иерархической модели данные представляются в виде древовидной (иерархической) структуры и базируется на теории графов. Такая организация данных удобна только для работы с иерархически упорядоченной информацией. При оперировании данными со сложными логическими связями иерархическая модель становится слишком громоздкой и сложной.

Вершины графа – деревья БД, а дуги, которые соединяют эти вершины – связь «предок-потомок». Иерархическую модель данных часто называют деревом или набором деревьев, т.к. внешне сходно с ним. В начале или вершине иерархии модели находится корень дерева, а его ответвления – листья дерева. Между типами записи поддерживаются связи, а целостность связи поддерживается между предками и потомками.
Преимущества
- Эффективное использование памяти компьютера.
- Высокие временные показатели выполнения операций над данными.
Недостатки
Сетевая модель
В сетевой модели данные организуются в виде произвольного графа и является расширением иерархической модели. В иерархических структурах запись-потомок должна иметь в точности одного предка; в сетевой структуре данных потомок может иметь любое число предков. Основными элементами сетевой базы данных являются элемент данных, агрегат данных, запись, набор.

Элемент данных – наименьшая неделимая поименованная информационная единица, доступная пользователю. Элемент данных может иметь свой тип. Агрегат данных – поименованная совокупность элементов данных внутри записи (день, месяц, год).
Запись – поименованная структура, содержащая элементы данных (запись в реляционной таблице).
Тип записей – это совокупность логически связанных экземпляров записей, моделирует некоторый класс объектов реального мира.
Набор – это поименованная двухуровневая иерархическая структура, которая выражает связи между двумя типами записей (один к одному, один ко многим).
Преимущества
- Возможность эффективной реализации по показателям затрат памяти
оперативности. - Большие возможности по созданию и моделированию различных связей между сущностями реального мира (предметной области).
Недостатки
- Высокая сложность.
- Жесткость схемы данных.
- Сложность для понимания и выполнения обработки информации обычным пользователем.
Объектно-ориентированная модель
В объектно-ориентированной модели отдельные записи базы данных представляются в виде объектов. Между записями базы данных и функциями их обработки устанавливаются взаимосвязи с помощью механизмов, подобных соответствующим средствам объектно-ориентированных языков программирования. Объектно-ориентированные модели сочетают особенности сетевой и реляционной моделей и используются для создания крупных БД со сложными структурами данных.

Значением свойства типа string является строка символов. Значение свойства типа class есть объект, являющийся экземпляром соответствующего класса, Каждый объект-экземпляр класса считается потомком объекта, в котором он определен как свойство. Объект-экземпляр класса принадлежит своему классу и имеет одного родителя. Родовые отношения в БД образуют связную иерархию объектов.
Объект типа библиотека является родительским для объектов-экземпляров классов абонент, каталог и выдача. различные объекты типа книга могут иметь одного или разных родителей. объекты типа книга, имеющие одного и того же родителя, должны различаться по крайней мере инвентарным номером (уникален для каждого экземпляра книги), но имеют одинаковые значения свойств ISBN, УДК, название и автор.
Логическая структура объектно-ориентированной БД внешне похожа на структуру иерархической БД. Основное отличие между ними состоит в методах манипулирования данными.
- Инкапсуляция ограничивает область видимости имени свойства пределами того объекта, в котором оно определено. Смысл такого свойства будет определяться тем объектом, в который оно инкапсулировано.
- Наследование, наоборот, распространяет область видимости свойства на всех потомков объекта. Если необходимо расширить действие механизма наследования на объекты, не являющиеся непосредственными родственниками (например, между двумя потомками одного родителя), то в их общем предке определяется абстрактное свойство типа аbs.
- Полиморфизм в объектно-ориентированных языках программирования означает способность одного и того же программного кода работать с разнотипными данными. Другими словами, он означает допустимость в объектах разных типов иметь методы (процедуры или функции) с одинаковыми именами.
Преимущества
- Возможность отображения информации о сложных взаимосвязях объектов.
- Позволяет идентифицировать отдельную запись базы данных и определять функции их обработки.
Недостатки
- Высокая понятийная сложность.
- Неудобство обработки данных.
- Низкая скорость выполнения запросов.
Реляционная модель
Реляционная модель состоит из relations (связей, отношений), каждое из которых имеет уникальное имя и состоит из строк (записей – кортежей) и столбцов (полей – атрибутов). Каждая запись представляет объект реального мира. Свойства объекта (его характеристики) определяются значениями полей. Каждое поле имеет имя, тип и размер данных, хранимых в нем. Имена полей вынесены в шапку таблицы.

Пример реляционной таблицы с полями «Сотрудник», «Задача», «Время разработки» представлен в таблице.
| Сотрудник | Задача | Время разработки |
|---|---|---|
| Иванов И.И. | Тестирование ПО | 3 ч |
| Петров П.П. | Разработка ПО | 12 ч |
Понятие тип данных в реляционной модели данных полностью адекватно понятию типа данных в языках программирования.
Обычно в современных реляционных БД допускается хранение символьных, числовых данных, битовых строк, специализированных числовых данных (например, денежная валюта), а также специальных «темпоральных» данных (дата, время, временной интервал).
Наименьшая единица данных реляционной модели – это отдельное атомарное (неразложимое) значение данных. Так, в одной предметной области фамилия, имя и отчество могут рассматриваться как единое значение, а в другой – как три различных значения.
Доменом называется множество значений данного типа (например, множество названий населенных пунктов).
Отношением является таблица, заголовком которой является схема отношения, строками – кортежи, а имена атрибутов – столбцы таблицы. Отношения используются для представления объектов окружающего мира и представления связей между объектами.
Реляционная база данных – это конечный набор отношений. Т.е. некоторое количество реляционных таблиц во взаимосвязи и составляют реляционную базу данных.
Каждое отношение обладает хотя бы одним потенциальным ключом, т.е. полем, все значения которого в данной таблице являются уникальными.
Преимущества
- Простота.
- Гибкость структуры.
- Удобство реализации на компьютере.
- Наличие теоретического описания.
Источник