Глава II Деревья
Как показано в § 4, среди графов с фиксированными порядком и числом компонент лишь один имеет максимальное число ребер. Другой крайний случай — минимальное число ребер — приводит к большому классу графов. Наиболее важными среди них являются связные графы, которые называются деревьями. Класс деревьев занимает в теории графов особое положение. С одной стороны, это достаточно просто устроенные графы, и многие задачи, весьма сложные в общей ситуации, для деревьев решаются легко. Доказано, например, что все деревья реконструируемы; несложно распознается изоморфизм деревьев. С другой стороны, деревья часто встречаются в областях, на первый взгляд не имеющих отношения к теории графов.
Деревья открывались независимо несколько раз. Еще в прошлом веке Г. Кирхгоф ввел деревья и применил их к исследованию электрических цепей, а А..Кэли, перечисляя изомеры насыщенных углеводоров, еще раз открыл деревья и первым исследовал их свойства. Тогда же деревья были введены и исследованы К. Жорданом как чисто математический объект.
§ 13. Определение дерева
Деревом называется связный граф, не содержащий циклов. Любой граф без циклов называется ациклическим (или лесом). Таким образом, компонентами леса являются деревья. На рис. 13.1 изображены все деревья шестого порядка.
Существует несколько вариантов определения дерева; некоторые из них отражены в следующей теореме.
Теорема 13.1. Для (n, m)-графа G следующие утверждения эквивалентны .
- G — дерево;
- G — связный граф и m = n — 1;
3) G — ациклический граф и m = n — 1; 4) любые две несовпадающие вершины графа G соединяет единственная простая цепь; 5) G — ациклический граф, обладающий тем свойством, что если какую-либо пару его несмежных вершин соединить ребром, то полученный граф будет содержать ровно один цикл.
- => 2) Воспользуемся индукцией по n. При n = 1 утверждение тривиально. Пусть
n > 1, е EG. В дереве G нет циклов, следовательно, согласно лемме 4.8, граф 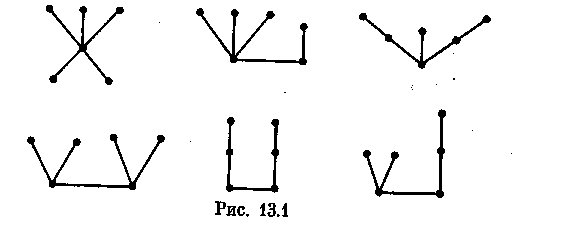 G — е имеет ровно две компоненты Т1 и T2, каждая из которых есть дерево. Пусть дерево T1 является (ni,mi)-графом, i=1, 2. По индуктивному предположению верно равенство mi = ni— 1. (1) Далее имеем n = m1 + m2 + 1 = (n1 — 1) + (n2 — 1) + 1 = (n1 + n2) — 1 = n — 1. 2) => 3) Граф G связен и m = n — 1. Нужно доказать, что в G нет циклов. Пусть, напротив, в графе G есть цикл, пусть е — ребро этого цикла. Тогда граф G — е связен лемма 4.8) и имеет n — 2 ребра, что противоречит теореме 4.9. Следовательно, G — ациклический граф. 3) => 4) Пусть k — число компонент графа G. Пусть, далее, компонента Ti является (ni, mi)-графом. Так как Ti — дерево, то верно равенство (1). Теперь имеем n— 1 = m = m1 + m2 + . . . + mk =(n1-1) + (n2 — 1)+ . +(nk — 1) = = (n1 + . + nk) — k = n — k, т. е. k = 1. Итак, G — связный граф и потому любые несовпадающие вершины u и v соединены в нем простой цепью. Если бы в G были две несовпадающие простые (u, v)-цепи, то согласно утверждению 4.3 их объединение содержало бы цикл. Следовательно, каждые две вершины соединены единственной простой цепью.
G — е имеет ровно две компоненты Т1 и T2, каждая из которых есть дерево. Пусть дерево T1 является (ni,mi)-графом, i=1, 2. По индуктивному предположению верно равенство mi = ni— 1. (1) Далее имеем n = m1 + m2 + 1 = (n1 — 1) + (n2 — 1) + 1 = (n1 + n2) — 1 = n — 1. 2) => 3) Граф G связен и m = n — 1. Нужно доказать, что в G нет циклов. Пусть, напротив, в графе G есть цикл, пусть е — ребро этого цикла. Тогда граф G — е связен лемма 4.8) и имеет n — 2 ребра, что противоречит теореме 4.9. Следовательно, G — ациклический граф. 3) => 4) Пусть k — число компонент графа G. Пусть, далее, компонента Ti является (ni, mi)-графом. Так как Ti — дерево, то верно равенство (1). Теперь имеем n— 1 = m = m1 + m2 + . . . + mk =(n1-1) + (n2 — 1)+ . +(nk — 1) = = (n1 + . + nk) — k = n — k, т. е. k = 1. Итак, G — связный граф и потому любые несовпадающие вершины u и v соединены в нем простой цепью. Если бы в G были две несовпадающие простые (u, v)-цепи, то согласно утверждению 4.3 их объединение содержало бы цикл. Следовательно, каждые две вершины соединены единственной простой цепью.
- => 5) Пара несовпадающих вершин, принадлежащих одному циклу, соединена по меньшей мере двумя простыми цепями. Следовательно, граф G ациклический. Пусть u и v — две его несмежные вершины. Присоединим к графу G ребро е = uv. В G есть простая (u, v)-цепь, которая в G + е дополняется до цикла. В силу утверждения 4.4 этот цикл единственный.
- => 1) Нужно доказать, что граф G связен. Если бы вершины u и v принадлежали разным компонентам графа G, то граф G + uv не имел бы циклов, что противоречит утверждению 5). Итак, G связен и потому является деревом.
Следствие13.2. В любом дереве порядка n 2 имеется не менее двух концевых вершин. Пусть d1,d2. dn (2) — степенная последовательность дерева. Тогда 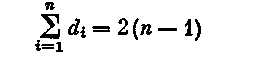 (лемма о рукопожатиях) и все di > 0. Следовательно, хотя бы два числа из последовательности (2) равны 1. Пусть Н — остовный подграф произвольного графа G. Если на каждой области связности графа G графом Н порождается дерево, то Н называется остовом (или каркасом) графа G. Очевидно, что в каждом графе существует остов: разрушая в каждой компоненте циклы, т. е. удаляя лишние ребра, придем к остову. Остов в графе легко найти с помощью поиска в ширину. Следствие13.3. Число ребер произвольного графа G, которые необходимо удалить для получения остова, не зависит от последовательности их удаления и равно m(G)—|G|+k(G), где m(G) и k(G)—число ребер и число компонент графа G соответственно. Если (n1, m1)-граф G является одной из компонент графа G, то для превращения ее в остовное дерево нужно удалить m1— (n1 — 1) подходящих ребер. Суммируя по всем k(G) компонентам, получим требуемое. Число v(G)= m(G) — |G| + k(G) называется циклическим рангом (или цикломатическим числом) графа G. Число v*(G)= |G| — k(G) ребер любого остова графа G называется коциклическим рангом графа G. Таким образом, v(G)+v*(G)=m(G). Очевидны три следствия 13.4—13.6. Следствие13.4. Граф G является лесом тогда и только тогда, когда v(G) = 0. Следствие13.5.Граф G имеет единственный цикл тогда и только тогда, когда v(G)= 1. Следствие13.6. Граф, в котором число ребер не меньше, чем число вершин, содержит цикл. В гл. III окажутся полезными утверждения 13.7, 13.8. Утверждение 13.7.Всякий ациклический подграф произвольного графа G содержится в некотором остове графа G. Пусть Н — ациклический подграф в G. Очевидно, что достаточно рассмотреть ситуацию, в которой Н—остовный подграф и G связен. Если теперь Н не является остовом, то он несвязен. Пусть А — одна из областей связности графа Н. В графе G есть такое ребро ab, что а А, b VH\A. Граф Н + аb — ациклический остовный подграф графа G, имеющий меньше, чем Н, компонент. Повторяя аналогичное построение, доберемся до дерева, т. е. остова, содержащего граф Н. Утверждение13.8. Если S и Т — два остова графа G, то для любого ребра е1 графа S существует такое ребро e2 графа Т, что граф S — е1 + е2 также является остовом. Не ограничивая общности, будем считать граф G связным. Граф S — е1 имеет ровно две области связности; пусть это будут А и В. Поскольку граф Т связен, то в нем существует ребро e2, один из концов которого входит в А, а другой — в В. Граф Н = S — е1 + е2 связен и число ребер в нем такое же, как в дереве S. Следовательно, он сам является деревом. Итак, Н— остов графа G. Очевидно, что два предыдущих утверждения об остовах (13.7 и 13.8) сохраняются для произвольного псевдографа. Докажем еще следующую теорему. Теорема 13.9. Центр любого дерева состоит из одной или из двух смежных вершин. Очевидно, что концевые вершины дерева Т являются центральными только для Т = К1 или Т = K2. Пусть Т — дерево порядка n > 2. Удалив из Т все концевые вершины, получим дерево Т’. Очевидно, что эксцентриситет Т’ на единицу меньше эксцентриситета дерева Т и что центры деревьев Т и Т’ совпадают. Далее доказательство легко проводится индукцией по числу вершин.
(лемма о рукопожатиях) и все di > 0. Следовательно, хотя бы два числа из последовательности (2) равны 1. Пусть Н — остовный подграф произвольного графа G. Если на каждой области связности графа G графом Н порождается дерево, то Н называется остовом (или каркасом) графа G. Очевидно, что в каждом графе существует остов: разрушая в каждой компоненте циклы, т. е. удаляя лишние ребра, придем к остову. Остов в графе легко найти с помощью поиска в ширину. Следствие13.3. Число ребер произвольного графа G, которые необходимо удалить для получения остова, не зависит от последовательности их удаления и равно m(G)—|G|+k(G), где m(G) и k(G)—число ребер и число компонент графа G соответственно. Если (n1, m1)-граф G является одной из компонент графа G, то для превращения ее в остовное дерево нужно удалить m1— (n1 — 1) подходящих ребер. Суммируя по всем k(G) компонентам, получим требуемое. Число v(G)= m(G) — |G| + k(G) называется циклическим рангом (или цикломатическим числом) графа G. Число v*(G)= |G| — k(G) ребер любого остова графа G называется коциклическим рангом графа G. Таким образом, v(G)+v*(G)=m(G). Очевидны три следствия 13.4—13.6. Следствие13.4. Граф G является лесом тогда и только тогда, когда v(G) = 0. Следствие13.5.Граф G имеет единственный цикл тогда и только тогда, когда v(G)= 1. Следствие13.6. Граф, в котором число ребер не меньше, чем число вершин, содержит цикл. В гл. III окажутся полезными утверждения 13.7, 13.8. Утверждение 13.7.Всякий ациклический подграф произвольного графа G содержится в некотором остове графа G. Пусть Н — ациклический подграф в G. Очевидно, что достаточно рассмотреть ситуацию, в которой Н—остовный подграф и G связен. Если теперь Н не является остовом, то он несвязен. Пусть А — одна из областей связности графа Н. В графе G есть такое ребро ab, что а А, b VH\A. Граф Н + аb — ациклический остовный подграф графа G, имеющий меньше, чем Н, компонент. Повторяя аналогичное построение, доберемся до дерева, т. е. остова, содержащего граф Н. Утверждение13.8. Если S и Т — два остова графа G, то для любого ребра е1 графа S существует такое ребро e2 графа Т, что граф S — е1 + е2 также является остовом. Не ограничивая общности, будем считать граф G связным. Граф S — е1 имеет ровно две области связности; пусть это будут А и В. Поскольку граф Т связен, то в нем существует ребро e2, один из концов которого входит в А, а другой — в В. Граф Н = S — е1 + е2 связен и число ребер в нем такое же, как в дереве S. Следовательно, он сам является деревом. Итак, Н— остов графа G. Очевидно, что два предыдущих утверждения об остовах (13.7 и 13.8) сохраняются для произвольного псевдографа. Докажем еще следующую теорему. Теорема 13.9. Центр любого дерева состоит из одной или из двух смежных вершин. Очевидно, что концевые вершины дерева Т являются центральными только для Т = К1 или Т = K2. Пусть Т — дерево порядка n > 2. Удалив из Т все концевые вершины, получим дерево Т’. Очевидно, что эксцентриситет Т’ на единицу меньше эксцентриситета дерева Т и что центры деревьев Т и Т’ совпадают. Далее доказательство легко проводится индукцией по числу вершин.
Источник
Все деревья являются графами

Поиск значения в BST занимает O(log n) времени. Это означает, что можно очень быстро найти требуемое значение среди миллионов или даже миллиардов записей.
Предположим, мы ищем узел со значением x. Чтобы быстро найти его в BST, воспользуемся следующим алгоритмом:
- Начать с корня дерева.
- Если x = значению узла: остановиться.
- Если x < значения узла: перейти к левому дочернему узлу.
- Если x > значения узла: перейти к правому дочернему узлу.
- Перейти к шагу 2.
При отсутствии уверенности в существовании искомого узла, необходимо изменить шаги 3 и 4 для остановки поиска.
Если хочешь подтянуть свои знания по алгоритмам, загляни на наш курс «Алгоритмы и структуры данных», на котором ты:
- углубишься в теорию структур данных;
- научишься решать сложные алгоритмические задачи;
- научишься применять алгоритмы и структуры данных при разработке программ.
Реализация
Создание узла TreeNode идентично созданию узла ListNode . Единственное отличие в том, что вместо одного атрибута у нас два: left и right , которые ссылаются на левые и правые дочерние узлы.
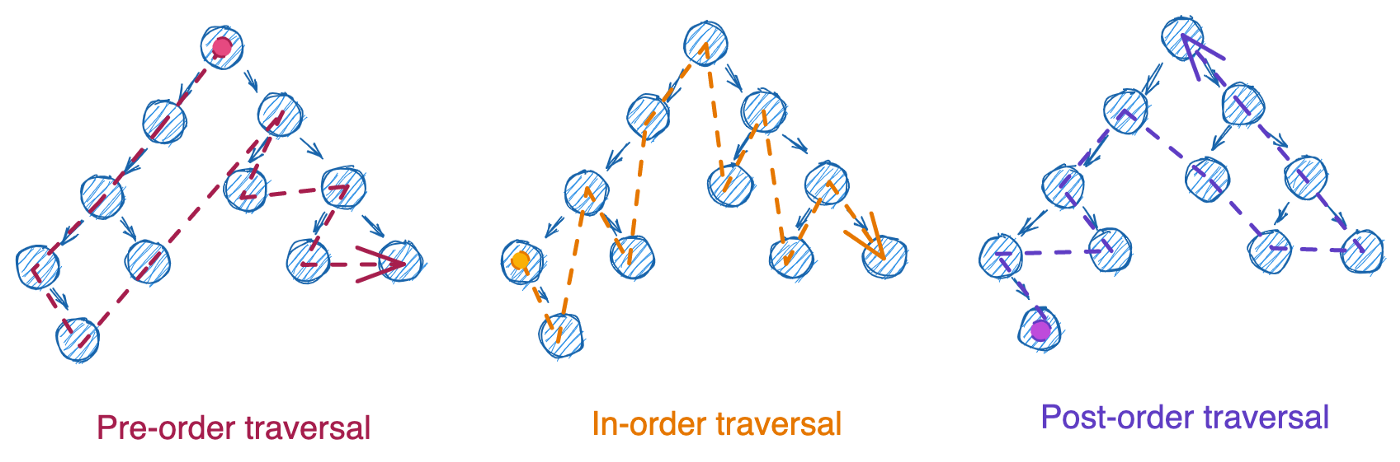
Эти три типа обхода могут быть реализованы следующими методами:
- с итерацией – использование цикла while и стека. В этом случае удаление данных возможно только с конца.
- с рекурсией – использование функции, которая вызывает сама себя.
Есть четвертый тип обхода – порядок уровней (level-order traversal). Этот способ использует очередь (queue). Удаление данных здесь возможно только с начала.
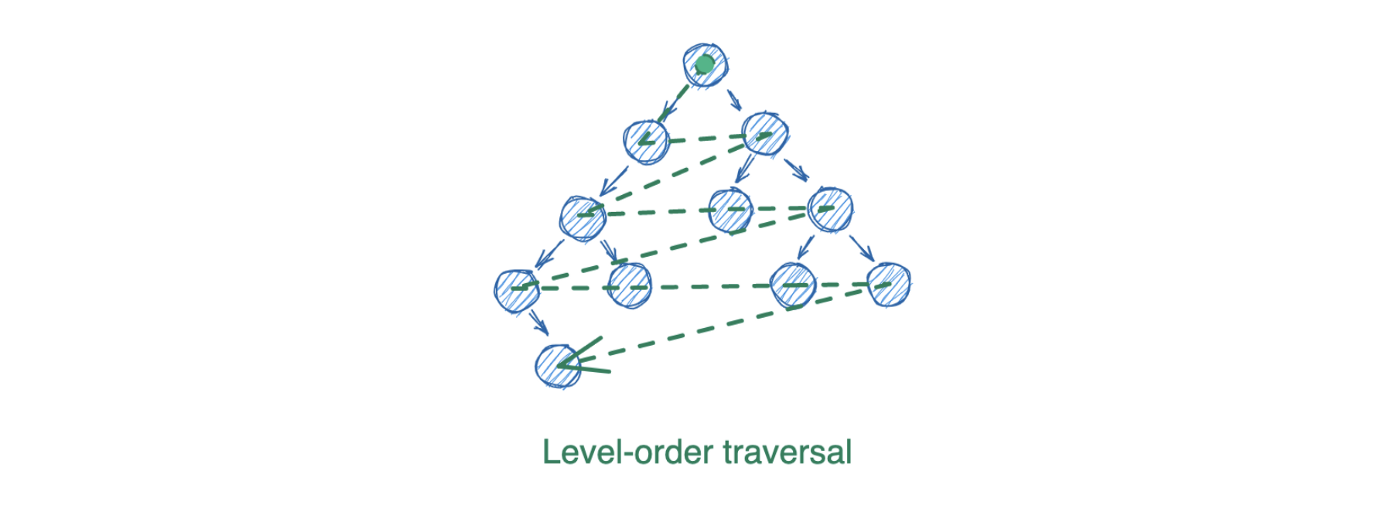
Для первых трех типов обработки узлов паттерны практически идентичны. Просто выберем обход в порядке возрастания. Ниже разберем итеративный и рекурсивный методы для LC 94: Binary Tree Inorder Traversal, начиная с итеративной версии:
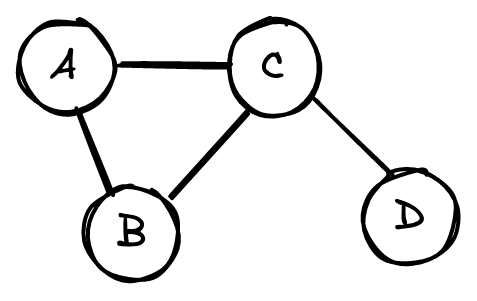
Как правило, графы представлены в виде матриц смежности (adjacency matrix). Так, у приведенного выше графа будет следующая матрица.

Каждая строка и столбец представляют собой узел. Единица в строке i и столбце j , или A_=1 , означает связь между узлом i и узлом j .
A_=0 означает, что узлы i и j не связаны.
Ни один из узлов в этом графе не связан с самим собой. Следовательно, диагональ матрицы равна нулю. Аналогично, A_ = A_ , потому что связи ненаправленны. То есть если узел A связан с узлом B , то B связан с A . В результате матрица смежности симметрична по диагонали.
Рассмотрим пример, который поможет нам понять описанную выше теорию.
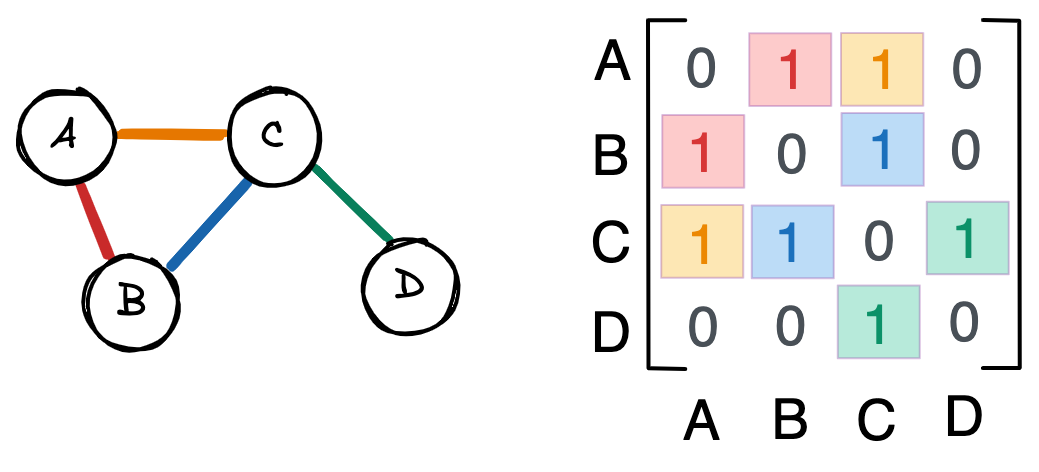
На представленных рисунках мы видим взвешенный граф с направленными ребрами. Обратите внимание, что связи больше не симметричны – вторая строка матрицы смежности пуста, потому что у B нет исходящих связей. Числа от 0 до 1 отражают силу связи. Например, граф C влияет на граф A сильнее, чем A на C .
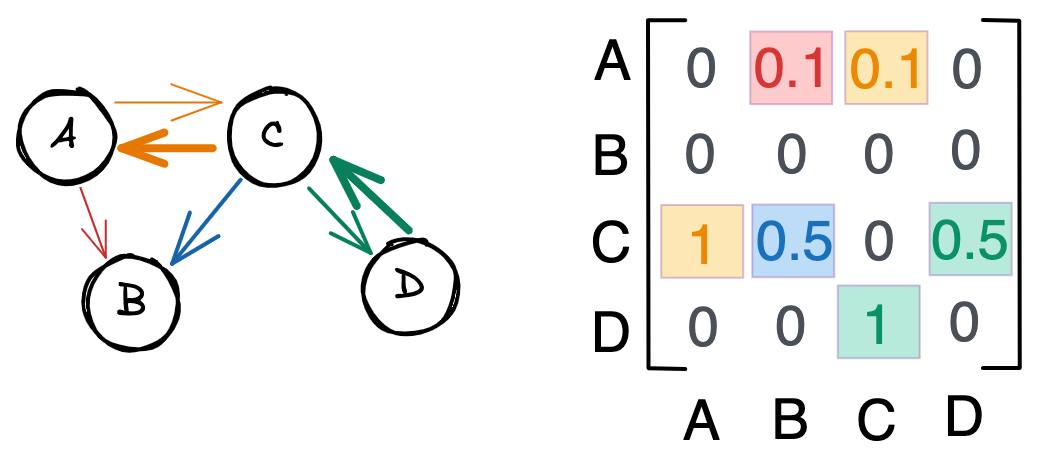
Реализация
Реализуем невзвешенный и неориентированный граф. Основной структурой класса является список списков Python. Каждый из них – это строка. Индексы в списке представляют собой столбцы. При создании объекта Graph необходимо указать количество узлов n, чтобы создать список списков. Затем мы можем получить доступ к соединению между узлами a и b с помощью self.graph[a][b] .
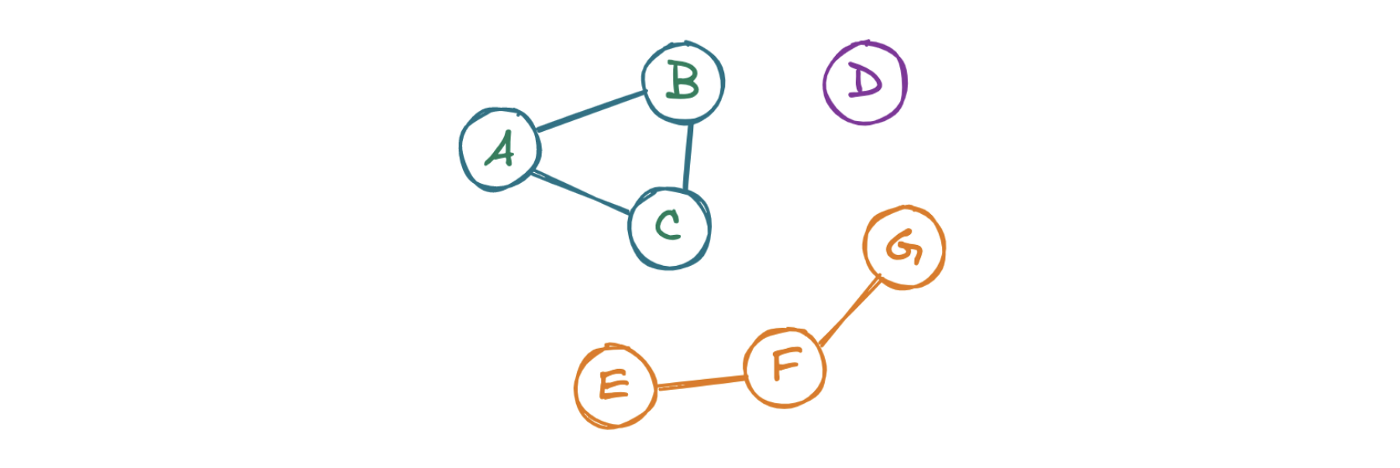
Чтобы ответить на вопрос LC 323: Количество связных компонентов, изучим каждый узел графа. Далее «посетим» соседние графы. Повторяем операцию до тех пор, пока не встретим только те узлы, которые уже были замечены программой. После этого проверим наличие в графе узлов, которые еще не были замечены. Если такие узлы присутствуют, то существует еще как минимум один кластер, поэтому нужно взять новый узел и повторить процесс.
def get_n_components(self, mat: List[List[int]]) -> int: """ Учитывая матрицу смежности, возвращает количество связанных компонентов """ q = [] unseen = [*range(len(mat))] answer = 0 while q or unseen: # Если все соседние узлы прошли через цикл, переходим к новому кластеру if not q: q.append(unseen.pop(0)) answer += 1 # Выбираем узел из текущего кластера focal = q.pop(0) i = 0 # Поиск связей во всех оставшихся узлах while i < len(unseen): node = unseen[i] # Если узел подключен к центру, добавляем его в очередь # чтобы перебрать его соседей # из невидимых узлов и избежать бесконечного цикла if mat[focal][node] == 1: q.append(node) unseen.remove(node) else: i += 1 return answer- Строки 5-8: Создаем очередь ( q ), список узлов ( unseen ) и количество компонентов ( answer ).
- Строка 10: Запускаем цикл while , который выполняем до тех пор, пока в очереди есть узлы, которые нужно обработать или узлы, которые не были замечены.
- Строки 13-15: Если очередь пуста, удаляем первый узел из непросмотренных и увеличиваем количество компонентов.
- Строки 18-19: Выбираем следующий доступный узел в очереди ( focal ).
- Строка 22: Запускаем цикл while , который выполняем до тех пор, пока не обработаем все оставшиеся узлы.
- Строка 23: Даем имя текущему узлу для оптимизации кода.
- Строки 28-30: Если текущий узел подключен к центру, добавляем его в очередь узлов текущего кластера. Удаляем его из списка тех узлов, которые могут находиться в невидимом кластере. Благодаря этому действию, мы избегаем бесконечного цикла.
- Строки 31-32: Если текущий узел не подключен к focal (центру), переходим к следующему узлу.
Заключение
Графы и деревья – основные структуры данных. Спектр их применения огромен. Например, графы используются там, где необходим алгоритм поиска решений. Реальный пример их использования – sea-of-nodes JIT-компилятора.
Деревья используются тогда, когда мы должны произвести быстрое добавление/удаление объекта с поиском по ключу. Например, в различных словарях и индексах БД (Баз данных). Кроме того, деревья являются неотъемлемой частью случайного леса – алгоритма машинного обучения.
В следующей части материала мы приступим к изучению хэш-таблиц.
Базовый и продвинутый курс «Алгоритмы и структуры данных» включает в себя:
- Живые вебинары 2 раза в неделю.
- 47 видеолекций и 150 практических заданий.
- Консультации с преподавателями курса.
Материалы по теме
Источник