Динамические структуры данных: бинарные деревья
Аннотация: В лекции рассматриваются определения, свойства и виды деревьев, элементы, характеристики и способы объявления деревьев в программах, основные операции над элементами деревьев, понятие и виды обходов деревьев, приводятся примеры реализации основных операций над бинарными деревьями в виде рекурсивных функций.
Цель лекции: изучить понятие, формирование, особенности доступа к данным и работы с памятью в бинарных деревьях, научиться решать задачи с использованием рекурсивных функций и алгоритмов обхода бинарных деревьев в языке C++.
Дерево является одним из важнейших и интересных частных случаев графа. Древовидная модель оказывается довольно эффективной для представления динамических данных с целью быстрого поиска информации .
Деревья являются одними из наиболее широко распространенных структур данных в информатике и программировании, которые представляют собой иерархические структуры в виде набора связанных узлов.
Дерево – это структура данных , представляющая собой совокупность элементов и отношений, образующих иерархическую структуру этих элементов ( рис. 31.1). Каждый элемент дерева называется вершиной (узлом) дерева. Вершины дерева соединены направленными дугами, которые называют ветвями дерева. Начальный узел дерева называют корнем дерева, ему соответствует нулевой уровень. Листьями дерева называют вершины, в которые входит одна ветвь и не выходит ни одной ветви.
Каждое дерево обладает следующими свойствами:
- существует узел, в который не входит ни одной дуги (корень);
- в каждую вершину, кроме корня, входит одна дуга.
Деревья особенно часто используют на практике при изображении различных иерархий. Например, популярны генеалогические деревья.
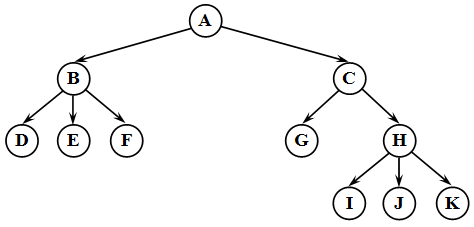
Все вершины, в которые входят ветви, исходящие из одной общей вершины, называются потомками, а сама вершина – предком. Для каждого предка может быть выделено несколько. Уровень потомка на единицу превосходит уровень его предка. Корень дерева не имеет предка, а листья дерева не имеют потомков.
Высота (глубина) дерева определяется количеством уровней, на которых располагаются его вершины. Высота пустого дерева равна нулю, высота дерева из одного корня – единице. На первом уровне дерева может быть только одна вершина – корень дерева , на втором – потомки корня дерева, на третьем – потомки потомков корня дерева и т.д.
Поддерево – часть древообразной структуры данных, которая может быть представлена в виде отдельного дерева.
Степенью вершины в дереве называется количество дуг, которое из нее выходит. Степень дерева равна максимальной степени вершины, входящей в дерево . При этом листьями в дереве являются вершины, имеющие степень нуль. По величине степени дерева различают два типа деревьев:
Упорядоченное дерево – это дерево , у которого ветви, исходящие из каждой вершины, упорядочены по определенному критерию.
Деревья являются рекурсивными структурами, так как каждое поддерево также является деревом. Таким образом, дерево можно определить как рекурсивную структуру, в которой каждый элемент является:
Действия с рекурсивными структурами удобнее всего описываются с помощью рекурсивных алгоритмов.
Списочное представление деревьев основано на элементах, соответствующих вершинам дерева. Каждый элемент имеет поле данных и два поля указателей: указатель на начало списка потомков вершины и указатель на следующий элемент в списке потомков текущего уровня. При таком способе представления дерева обязательно следует сохранять указатель на вершину, являющуюся корнем дерева .
Для того, чтобы выполнить определенную операцию над всеми вершинами дерева необходимо все его вершины просмотреть. Такая задача называется обходом дерева.
Обход дерева – это упорядоченная последовательность вершин дерева, в которой каждая вершина встречается только один раз.
При обходе все вершины дерева должны посещаться в определенном порядке. Существует несколько способов обхода всех вершин дерева. Выделим три наиболее часто используемых способа обхода дерева ( рис. 31.2):
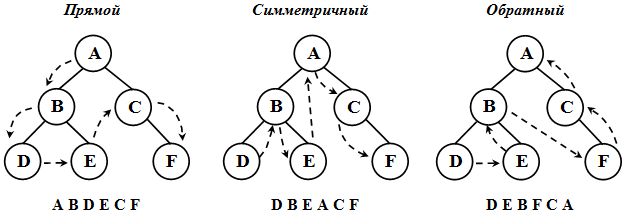
Существует большое многообразие древовидных структур данных. Выделим самые распространенные из них: бинарные (двоичные) деревья, красно-черные деревья, В-деревья, АВЛ-деревья , матричные деревья, смешанные деревья и т.д.
Бинарные деревья
Бинарные деревья являются деревьями со степенью не более двух.
Бинарное (двоичное) дерево – это динамическая структура данных , представляющее собой дерево , в котором каждая вершина имеет не более двух потомков ( рис. 31.3). Таким образом, бинарное дерево состоит из элементов, каждый из которых содержит информационное поле и не более двух ссылок на различные бинарные поддеревья. На каждый элемент дерева имеется ровно одна ссылка .
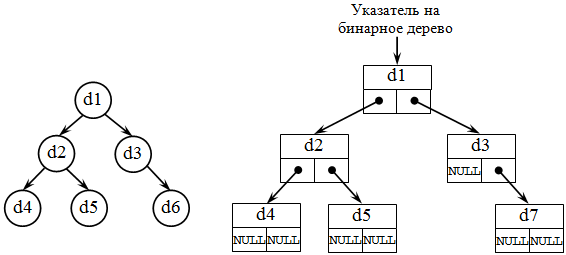
Каждая вершина бинарного дерева является структурой, состоящей из четырех видов полей. Содержимым этих полей будут соответственно:
- информационное поле (ключ вершины);
- служебное поле (их может быть несколько или ни одного);
- указатель на левое поддерево ;
- указатель на правое поддерево .
По степени вершин бинарные деревья делятся на ( рис. 31.4):
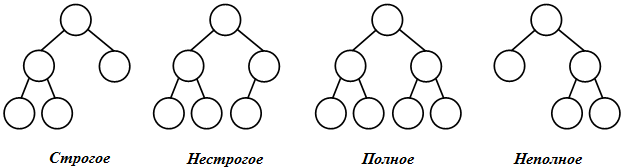
- строгие – вершины дерева имеют степень ноль (у листьев) или два (у узлов);
- нестрогие – вершины дерева имеют степень ноль (у листьев), один или два (у узлов).
В общем случае у бинарного дерева на k -м уровне может быть до 2 k-1 вершин. Бинарное дерево называется полным, если оно содержит только полностью заполненные уровни. В противном случае оно является неполным.
Дерево называется сбалансированным, если длины всех путей от корня к внешним вершинам равны между собой. Дерево называется почти сбалансированным, если длины всевозможных путей от корня к внешним вершинам отличаются не более, чем на единицу.
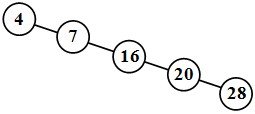
Бинарное дерево может представлять собой пустое множество . Бинарное дерево может выродиться в список ( рис. 31.5).
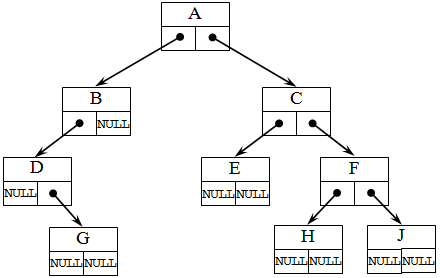
Структура дерева отражается во входном потоке данных так: каждой вводимой пустой связи соответствует условный символ, например, ‘*’ (звездочка). При этом сначала описываются левые потомки, затем, правые. Для структуры бинарного дерева , представленного на следующем рисунке 6, входной поток имеет вид: ABD*G***CE**FH**J** .
Бинарные деревья могут применяться для поиска данных в специально построенных деревьях ( базы данных ), сортировки данных, вычислений арифметических выражений , кодирования (метод Хаффмана) и т.д.
Источник
Деревья поиска
Дерево — одна из наиболее распространенных структур данных в программировании.
Деревья состоят из набора вершин (узлов, нод) и ориентированных рёбер (ссылок) между ними. Вершины связаны таким образом, что от какой-то одной вершины, называемой корневой (вершина 8 на рисунке), можно дойти до всех остальных единственным способом.
- Родитель вершины $v$ — вершина, из которой есть прямая ссылка в $v$.
- Дети (дочерние элементы, сын, дочь) вершины $v$ — вершины, в которые из $v$ есть прямая ссылка.
- Предки — родители родителей, их родители, и так далее.
- Потомки — дети детей, их дети, и так далее.
- Лист (терминальная вершина) — вершина, не имеющая детей.
- Поддерево — вершина дерева вместе со всеми её потомками.
- Степень вершины — количество её детей.
- Глубина вершины — расстояние от корня до неё.
- Высота дерева — максимальная из глубин всех вершин.
Деревья чаще всего представляются в памяти как динамически создаваемые структуры с явными указателями на своих детей, либо как элементы массива связанные отношениями, неявно определёнными их позициями в массиве.
Деревья также используются в контексте графов.
Бинарные деревья поиска
Бинарное дерево поиска (англ. binary search tree, BST) — дерево, для которого выполняются следующие свойства:
- У каждой вершины не более двух детей.
- Все вершины обладают ключами, на которых определена операция сравнения (например, целые числа или строки).
- У всех вершин левого поддерева вершины $v$ ключи не больше, чем ключ $v$.
- У всех вершин правого поддерева вершины $v$ ключи больше, чем ключ $v$.
- Оба поддерева — левое и правое — являются двоичными деревьями поиска.
Более общим понятием являются обычные (не бинарные) деревья поиска — в них количество детей может быть больше двух, и при этом в «более левых» поддеревьях ключи должны быть меньше, чем «более правых». Пока что мы сконцентрируемся только на двоичных, потому что они проще.
Чаще всего бинарные деревья поиска хранят в виде структур — по одной на каждую вершину — в которых записаны ссылки (возможно, пустые) на правого и левого сына, ключ и, возможно, какие-то дополнительные данные.
Как можно понять по названию, основное преимущество бинарных деревьев поиска в том, что в них можно легко производить поиск элементов:
Эта функция — как и многие другие основные, например, вставка или удаление элементов — работает в худшем случае за высоту дерева. Высота бинарного дерева в худшем случае может быть $O(n)$ («бамбук»), поэтому в эффективных реализациях поддерживаются некоторые инварианты, гарантирующую среднюю глубину вершины $O(\log n)$ и соответствующую стоимость основных операций. Такие деревья называются сбалансированными.
Источник
Деревья поиска
Дерево — одна из наиболее распространенных структур данных в программировании.
Деревья состоят из набора вершин (узлов, нод) и ориентированных рёбер (ссылок) между ними. Вершины связаны таким образом, что от какой-то одной вершины, называемой корневой (вершина 8 на рисунке), можно дойти до всех остальных единственным способом.
- Родитель вершины $v$ — вершина, из которой есть прямая ссылка в $v$.
- Дети (дочерние элементы, сын, дочь) вершины $v$ — вершины, в которые из $v$ есть прямая ссылка.
- Предки — родители родителей, их родители, и так далее.
- Потомки — дети детей, их дети, и так далее.
- Лист (терминальная вершина) — вершина, не имеющая детей.
- Поддерево — вершина дерева вместе со всеми её потомками.
- Степень вершины — количество её детей.
- Глубина вершины — расстояние от корня до неё.
- Высота дерева — максимальная из глубин всех вершин.
Деревья чаще всего представляются в памяти как динамически создаваемые структуры с явными указателями на своих детей, либо как элементы массива связанные отношениями, неявно определёнными их позициями в массиве.
Деревья также используются в контексте графов.
Бинарные деревья поиска
Бинарное дерево поиска (англ. binary search tree, BST) — дерево, для которого выполняются следующие свойства:
- У каждой вершины не более двух детей.
- Все вершины обладают ключами, на которых определена операция сравнения (например, целые числа или строки).
- У всех вершин левого поддерева вершины $v$ ключи не больше, чем ключ $v$.
- У всех вершин правого поддерева вершины $v$ ключи больше, чем ключ $v$.
- Оба поддерева — левое и правое — являются двоичными деревьями поиска.
Более общим понятием являются обычные (не бинарные) деревья поиска — в них количество детей может быть больше двух, и при этом в «более левых» поддеревьях ключи должны быть меньше, чем «более правых». Пока что мы сконцентрируемся только на двоичных, потому что они проще.
Чаще всего бинарные деревья поиска хранят в виде структур — по одной на каждую вершину — в которых записаны ссылки (возможно, пустые) на правого и левого сына, ключ и, возможно, какие-то дополнительные данные.
Как можно понять по названию, основное преимущество бинарных деревьев поиска в том, что в них можно легко производить поиск элементов:
Эта функция — как и многие другие основные, например, вставка или удаление элементов — работает в худшем случае за высоту дерева. Высота бинарного дерева в худшем случае может быть $O(n)$ («бамбук»), поэтому в эффективных реализациях поддерживаются некоторые инварианты, гарантирующую среднюю глубину вершины $O(\log n)$ и соответствующую стоимость основных операций. Такие деревья называются сбалансированными.
Источник