Вывести число вершин n-го уровня (Бинарное дерево поиска)
всем привет, дано такое задание:
Напишите программу, которая формирует бинарное дерево поиска, выводит построенное дерево на экран и подсчитывает число вершин на n-ом уровне сформированного дерева. Корень считать вершиной 0-го уровня. Обход дерева выполните с помощью не рекурсивного алгоритма. Данные могут вводиться с клавиатуры, из файла или генерироваться с помощью генератора случайных чисел. Перед завершением работы программы освободить занимаемую динамическую память. Для этого используйте поэлементное удаление элементов динамической структуры данных.
пока пытаюсь реализовать удаление поэлементное
уже мучаюсь целый день, и не могу понять в чем проблема, почему строчка 87 while ( cin >>dig2 ) TRoot=Del(TRoot, dig2);
неправильно срабатывает. не дает ввести элементы которые надо удалить, а просто пропускает, подскажите в чем дело??
заранее спасибо, вот мой код:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92
#include #include #include #include #include #include using namespace std; struct BSTree { int key; BSTree *Left; BSTree *Right; }; BSTree *TRoot=NULL; int lvl=0; BSTree* AddTree(BSTree *t, int k) { if (t == NULL) { t = new BSTree; t->Left = NULL; t->Right = NULL; t->key = k; } else if(t->key==k) return t; else { if (k > t->key ) t->Right=AddTree(t->Right, k); else t->Left=AddTree(t->Left, k); } return t; } void TreeShow(BSTree *t, int lvl ) { int tab = 5; if (t == NULL) cout "Derevo pusto \n"; else { if (t->Right != NULL) TreeShow(t->Right, lvl+1); cout setw(tab*lvl) t->key endl; if (t->Left != NULL) TreeShow(t->Left, lvl+1); } } BSTree* Del(BSTree* T, int k) { BSTree *P, *v; if (T!=NULL) cout "this element in the tree there!" endl; else if (k T->key) T->Left = Del(T->Left, k); else if (k > T-> key) T->Right = Del(T->Right, k); else {P = T; if (T->Right!=NULL) T = T->Left; // случай 1 else if (T->Left!=NULL) T = T->Right; // случай 1 else // случай 2 { v = T->Left; if (v->Right) { while (v->Right->Right) v = v->Right; T->key = v->Right->key; P = v->Right; v->Right = v->Right->Left; } else { T->key = v->key; P = v; T->Left=T->Left->Left; } } free(P); } return T; } void main() { int dig, dig2; cout "Enter the numbers, for the end of any character other than numbers:\n"; while ( cin >>dig ) TRoot=AddTree(TRoot, dig); cout endl; TreeShow(TRoot, lvl); cout "Enter number of items you want to delete, for the end of any character other than numbers:\n"; while ( cin >>dig2 ) TRoot=Del(TRoot, dig2); coutendl; lvl=0; TreeShow(TRoot, lvl); system("PAUSE"); } Источник
Бинарные деревья. Начало
На этом занятии мы затронем новую тему – бинарные деревья. Что это такое? Давайте предположим, что нам в программе нужно хранить и обрабатывать иерархические структуры данных, например, генеалогическое древо семьи, или структура каталогов и файлов и т.п.

То есть, везде, где есть некая начальная (корневая) вершина, от которой можно провести связи к дочерним, а от них – к следующим дочерним, получается иерархическая древовидная структура. Именно о таких структурах данных мы и будем вести речь на ближайших занятиях.
Начальная вершина дерева, от которого следуют все остальные, называется корнем дерева (root). Сами элементы дерева – узлами или вершинами (nodes). Причем, узел слева, называется левым, а справа – правым. Если у вершины нет левого или правого потомка, то обычно указывают значение NULL. Вершины, у которых нет потомков, называются листьями. Само же дерево, у которого каждая вершина может содержать не более двух дочерних узлов, называется бинарным или двоичным. Всю эту терминологию и обозначения, мы в дальнейшем будем активно использовать.
Структура бинарного дерева
Чаще всего в практике программирования используют бинарные деревья. Даже когда у вершины предполагается множество потомков, то зачастую задачу сводят все равно к бинарным деревьям или какой-либо другой структуре данных. Поэтому мы в рамках данного курса ограничимся именно бинарными деревьями.
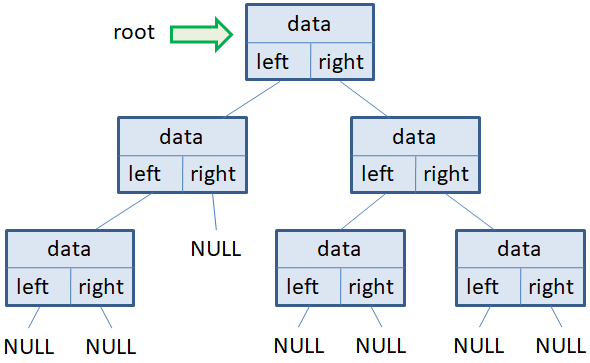
Каждая вершина такого дерева содержит, как минимум, три поля:
- data – данные, хранимые в вершине дерева;
- left – ссылка (указатель) на потомка слева;
- right – ссылка (указатель) на потомка справа.
Иногда еще добавляют ссылку на родительский узел. Но чаще всего ограничиваются этими тремя полями. На вершину дерева, которая называется корнем, ведет указатель root. И через этот указатель происходит вся работа с бинарным деревом: добавление/удаление элементов; обход всех узлов дерева. То есть, из корневого узла можно пройти до любого другого в данном дереве. При этом, количество вершин, через которые нужно пройти, чтобы достичь некоторого узла, определяет уровень (level) дерева. Если дерево не содержит ни одной вершины, то root = NULL. Также, если у какой-либо вершины отсутствует левый или правый потомок, то соответствующий указатель принимает значение NULL.
Добавление вершин в бинарное дерево
Давайте теперь посмотрим, как можно формировать бинарное дерево, то есть, добавлять в него новые вершины. Обычно, новые узлы добавляются к свободному указателю (то есть, тот, который принимает значение NULL), начиная с корневого. То есть, первая вершина всегда добавляется в корень, и других вариантов просто нет. А вот далее, мы уже решаем добавить левый или правый узел. Строго говоря, ограничений здесь никаких нет. Алгоритм добавления может быть самым разным, исходя из поставленной задачи. Например, если нам нужно сформировать генеалогическое древо, то, очевидно, в вершинах последовательно должны указываться потомки: на нулевом уровне – некоторый человек; на первом – мама, папа; на втором – бабушки, дедушки и т.д. Но есть отдельный класс задач, когда в вершинах бинарного дерева хранятся данные, которые можно сравнивать на больше и меньше (например, числа), и добавление нового узла происходит по правилам:
- если добавляемое значение меньше значения в родительском узле, то новая вершина добавляет в левую ветвь, иначе – в правую;
- если добавляемое значение уже присутствует в дереве, то оно игнорируется (то есть, дубли отсутствуют).
Например, предположим, мы собираемся хранить в вершинах бинарного дерева целые числа. И будем последовательно добавлять узлы для значений: 10, 5, 7, 16, 13, 2, 20 Первое значение 10 просто добавляется в корневую вершину. Следующее значение 5. Смотрим от корня. Пять меньше 10. Тогда, согласно нашим правилам, это значение нужно записать в левую ветвь. Формируем новый узел со значением 5. Следующее значение 7. Снова идет от корня дерева. Семь меньше 10, переходим в левую ветвь. Здесь у нас узел со значением 5. И пять больше 7. Следовательно, семь нужно добавить в качестве правого узла дерева у вершины 5. Далее, идет число 16. Оно больше 10, поэтому добавляем его в качестве правой вершины у корневой. Затем, число 13. Оно также больше 10, но меньше 16. Следовательно, нужно добавить левый узел у вершины 16. Следующее значение 2 меньше 10 и меньше 5. Добавляем новый узел справа от узла 5. И последнее значение 20 – самое большое, поэтому оно станет самой крайней правой вершиной дерева. 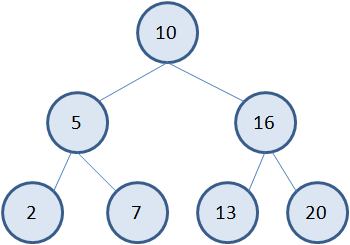 Благодаря такому подходу в формировании бинарного дерева, у нас в левой ветви будут находиться вершины со значениями меньше, чем у корневой, а в правой ветви – вершины со значениями больше корневой. И этот вывод будет справедлив для любого выделенного фрагмента поддерева, например:
Благодаря такому подходу в формировании бинарного дерева, у нас в левой ветви будут находиться вершины со значениями меньше, чем у корневой, а в правой ветви – вершины со значениями больше корневой. И этот вывод будет справедлив для любого выделенного фрагмента поддерева, например: 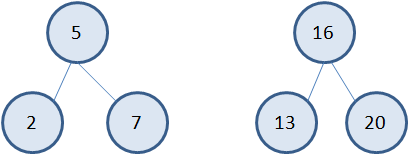
Поиск значений в бинарном дереве
Хорошо, но что нам это дает? Смотрите, здесь появляется несколько интересных эффектов. Первый – это ускорение поиска заданного значения. Например, нам нужно определить, находится ли число 2 в последовательности чисел 10, 5, 7, 16, 13, 2, 20. Если бы мы хранили числа в обычном массиве:  то время поиска, с точки зрения O большого, составило бы O(n), где n – число элементов в массиве. Нам пришлось бы последовательно перебирать все элементы и сравнивать значения с числом 2. А вот в бинарном дереве все несколько иначе и, в среднем, быстрее. Вначале число 2 сравнивается с числом 10. Оно меньше, поэтому идем по левой ветви, где сосредоточены вершины со значениями меньше 10. В результате, мы сразу отсекаем правую группу элементов, значения которых заведомо не равны 2. За счет этого происходит ускорение поиска. Затем, сравниваем 2 и 5. И, так как 2 меньше 5, то снова переходим по левой ветви. Находим заданное значение. Как видите, нам потребовалось всего три сравнения, чтобы найти число 2 в бинарном дереве. С позиции О большого среднее число операций, необходимое для поиска нужного значения составляет
то время поиска, с точки зрения O большого, составило бы O(n), где n – число элементов в массиве. Нам пришлось бы последовательно перебирать все элементы и сравнивать значения с числом 2. А вот в бинарном дереве все несколько иначе и, в среднем, быстрее. Вначале число 2 сравнивается с числом 10. Оно меньше, поэтому идем по левой ветви, где сосредоточены вершины со значениями меньше 10. В результате, мы сразу отсекаем правую группу элементов, значения которых заведомо не равны 2. За счет этого происходит ускорение поиска. Затем, сравниваем 2 и 5. И, так как 2 меньше 5, то снова переходим по левой ветви. Находим заданное значение. Как видите, нам потребовалось всего три сравнения, чтобы найти число 2 в бинарном дереве. С позиции О большого среднее число операций, необходимое для поиска нужного значения составляет 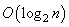 . И это значительно быстрее, чем линейный поиск в массивах или связных списках. Давайте теперь посмотрим на работу алгоритма в случае, когда заданное значение для поиска в бинарном дереве отсутствует. Например, это число 11. Очевидно, мы должны идти сначала по правой ветви, в узле 16 – по левой, и доходим до листовой вершины 13. Далее, никаких узлов в дереве нет, но значение не было найдено, следовательно, в дереве нет этого числа 11. Или, такой пример. Нам нужно найти число 5. Оно хранится в промежуточной вершине. Поэтому, когда мы доходим до нее, то дальнейший процесс поиска прерывается, значение найдено. Вот принцип, по которому выполняется поиск значений в вершинах бинарного дерева.
. И это значительно быстрее, чем линейный поиск в массивах или связных списках. Давайте теперь посмотрим на работу алгоритма в случае, когда заданное значение для поиска в бинарном дереве отсутствует. Например, это число 11. Очевидно, мы должны идти сначала по правой ветви, в узле 16 – по левой, и доходим до листовой вершины 13. Далее, никаких узлов в дереве нет, но значение не было найдено, следовательно, в дереве нет этого числа 11. Или, такой пример. Нам нужно найти число 5. Оно хранится в промежуточной вершине. Поэтому, когда мы доходим до нее, то дальнейший процесс поиска прерывается, значение найдено. Вот принцип, по которому выполняется поиск значений в вершинах бинарного дерева.
Сбалансированные и несбалансированные деревья
Внимательный зритель сейчас мог бы мне возразить и сказать, что у нас все так хорошо получается, потому что я привел пример «красивого» бинарного дерева с минимальным числом уровней (всего два): 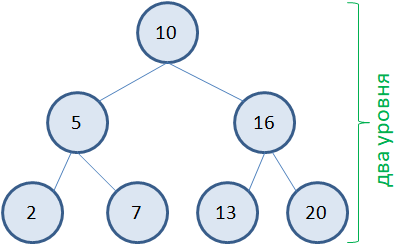 Но, если бы числа при формировании дерева поступали в другом порядке, или по возрастанию: 2, 5, 7, 10, 13, 16, 20 или по убыванию: 20, 16, 13, 10, 7, 5, 2 то деревья выглядели бы совсем иначе:
Но, если бы числа при формировании дерева поступали в другом порядке, или по возрастанию: 2, 5, 7, 10, 13, 16, 20 или по убыванию: 20, 16, 13, 10, 7, 5, 2 то деревья выглядели бы совсем иначе: 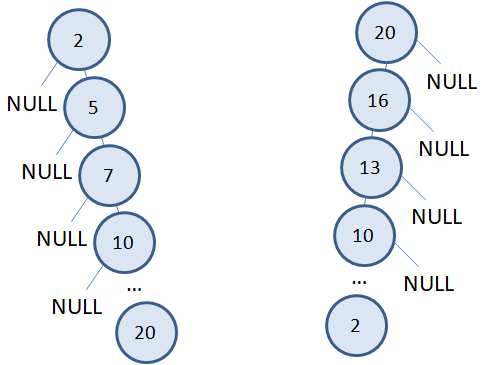 Фактически, они вырождаются в односвязный список и объем вычислений для поиска заданного значения в них составляет O(n). Так же, как и в обычных массивах или связных списках. Выигрыша уже нет. Такие вырожденные деревья (и подобные им) называются несбалансированными. В отличие от первого, которое относится к сбалансированным. Вообще, дерево называется сбалансированным, если в нем поддеревья от одной вершины отличаются не более чем на один уровень. И именно в сбалансированных деревьях поиск значений в вершинах выполняется за минимальное число шагов с объемом вычислений O(log n). Поэтому, на практике, стремятся строить деревья близкие к сбалансированным. Для этого используют методы балансировки двоичных деревьев, среди которых, наиболее известны следующие:
Фактически, они вырождаются в односвязный список и объем вычислений для поиска заданного значения в них составляет O(n). Так же, как и в обычных массивах или связных списках. Выигрыша уже нет. Такие вырожденные деревья (и подобные им) называются несбалансированными. В отличие от первого, которое относится к сбалансированным. Вообще, дерево называется сбалансированным, если в нем поддеревья от одной вершины отличаются не более чем на один уровень. И именно в сбалансированных деревьях поиск значений в вершинах выполняется за минимальное число шагов с объемом вычислений O(log n). Поэтому, на практике, стремятся строить деревья близкие к сбалансированным. Для этого используют методы балансировки двоичных деревьев, среди которых, наиболее известны следующие:
- АВЛ-дерево (AVL tree), разработан в 1968 году;
- красно-черное дерево (red-black tree), разработан в 1972 году;
- расширяющееся или косое дерево (splay tree), разработан в 1983 году.
Любой из этих методов может быть реализован в бинарном дереве и вызываться при добавлении новых вершин. В результате получаем более сбалансированное дерево при любых входных последовательностях данных. В данном курсе мы не будем углубляться в эти темы. Кому будет интересно, подробную информацию по этим методам легко найти на просторах Интернета. Отмечу только, что если нам известно, что в решаемой задаче данные (значения) поступают в случайном порядке, то в среднем, будет формироваться бинарное дерево близкое к сбалансированному. На этом мы завершим наше первое знакомство с бинарными деревьями, а на следующем продолжим и поговорим об алгоритмах обхода и удаления вершин бинарных деревьев. Курс по структурам данных: https://stepik.org/a/134212
Источник